

Forskellen mellem Hadoop og HBase
Hadoop er en open source Java-ramme, der bruges til at styre og behandle en enorm mængde strukturerede og ustrukturerede data. Hadoop er massivt skalerbar og bruges derfor til at behandle Big Data-arbejdsmængder. Store data gemmes, åbnes og behandles i den pålidelige og udvidelige klynge. HBase (Hadoop Database) er en ikke-relationel og ikke kun SQL, dvs. NoSQL-database, der kører på toppen af Hadoop som et distribueret og skalerbart big data-lager. Det er en open source-database, hvor data gemmes i form af rækker og kolonner, i denne celle er et skæringspunkt mellem kolonner og rækker.
Nedenfor er kernekomponenterne i Hadoop arkitektur:
- Hadoop Distribueret filsystem (HDFS): Hadoop inkluderer et distribueret lagringssystem, Hadoop Distribueret filsystem (HDFS). HDFS er master-slave-arkitekturen, der gemmer data på tværs af klyngen. Data distribueret på flere slaveknudepunkter af masternoden i formblokken. Hovednoden kaldes Namenode, og slaveknudene kaldes Datanode. HDFS kan let udvides og gemmer en enorm mængde data på Datanoder. HDFS har en konfigurerbar replikeringsfaktor med standardværdi 3, der kan redigeres.
- MapReduce: MapReduce er et programmeringsparadigme, som processer parallelt på et stort antal datasæt over netværket. MapReduce refererer til to forskellige opgaver: kortlægge inputdataene, i hvilke data opdelt i en undergruppe af data kaldet tuple og reducere opgave tager disse tuples fra kortet som input og kombineres for at danne output fra originalen.
- Garn: YARN står for Endnu en ressourcenavigator, der beregner ressourcer såsom administrerer CPU og hukommelse, planlægning af ressourceanmodninger.
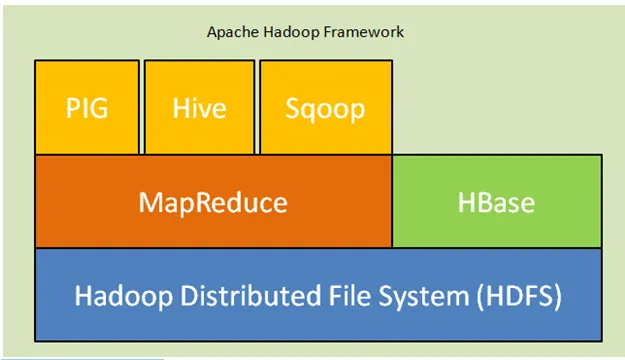
Fig. Apache Hadoop Framework
Regionserver serverer data til læsning / skrivning. Alle HBase-data gemmes i HDFS-filen. HDFS Datanode gemmer de data, som regionserveren administrerer. HDFS Namenode opbevarer metadatainformation for alle fysiske datablokke, der indeholder filerne.
Versionering bruges til at spore celleændringer, hvilket holder sporet med indholdsversionen. Fra det kan enhver version af indhold hentes. Hver celleværdi inkluderer attributten 'version' med hensyn til tidsstemplet til at hente cellen. Hver værdi på kortet er en uafbrudt række af bytes. Kortet indekseres med en række nøgle, kolonnetast og en tidsstempel. Arkitekturen i HBase er meget skalerbare, sparsomme, distribuerede, vedvarende og multidimensionelle sorterede kort.
Sammenligning mellem hoved og hoved mellem Hadoop vs HBase (Infographics)
Nedenfor er Top 7 forskellen mellem Hadoop vs HBase
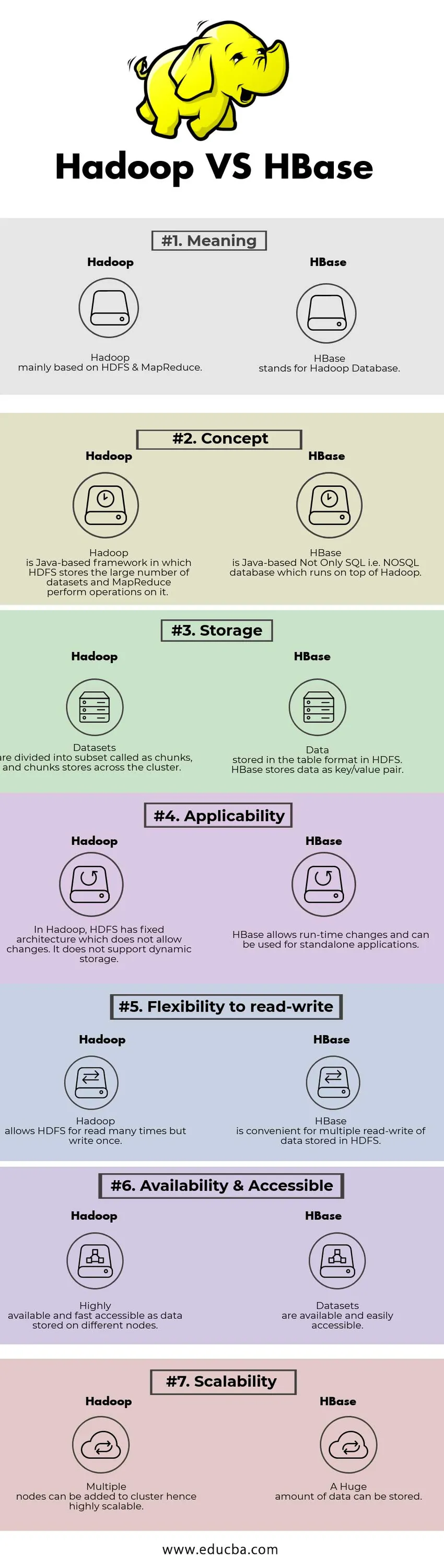
Vigtige forskelle mellem Hadoop vs HBase
Forskellen mellem Hadoop og HBase forklares i nedenstående punkter:
- Hadoop er ikke egnet til Online analytisk behandling (OLAP), og HBase er en del af Hadoop-økosystemet, som giver tilfældig realtidsadgang (læse / skrive) til data i Hadoop-filsystemet.
- Hadoop-rammerne er fejltolerante ved design og understøtter hurtig dataoverførsel mellem noder, selv under systemfejl. HBase er en ikke-relationel og open source Not-Only-SQL-database, der kører oven på Hadoop. HBase hører under CP-typen CAP (konsistens, tilgængelighed og partitionstolerance) teorem.
- Hadoop er bedst egnet til at udføre batchanalyse. En af dens største ulemper er imidlertid dens manglende evne til at udføre realtidsanalyse, IT-brancheens tendenskrav. HBase på den anden side kan håndtere store datasæt og er ikke passende til batchanalyse. I stedet bruges det til at skrive / læse data fra Hadoop i realtid.
- Både Hadoop og HBase er i stand til at behandle strukturerede, semistrukturerede såvel som ustrukturerede data. I Hadoop mangler HDFS en in-memory-behandlingsmotor, der bremser processen med dataanalyse; som det bruger almindelig gammel MapReduce til at gøre det. HBase, tværtimod, kan prale af en processor i hukommelsen, der drastisk øger hastigheden på læse / skrivning.
- Hadoop er meget gennemsigtig i sin udførelse af dataanalyse. På den anden side henter HBase, der er en NoSQL-database i tabelformat, værdier ved at sortere dem under forskellige nøgleværdier.
Hadoop vs HBase sammenligningstabel
| GRUNDLÆGGENDE TIL Sammenligning | Hadoop | HBase |
| Betyder | Hadoop hovedsageligt baseret på HDFS & MapReduce. | HBase står for Hadoop Database. |
| Koncept | Hadoop er en Java-baseret ramme, hvor HDFS gemmer det store antal datasæt og MapReduce udfører operationer på det. | HBase er Java-baseret ikke kun SQL dvs. NoSQL-database, der kører oven på Hadoop. |
| Opbevaring | Datasæt er opdelt i delmængder kaldet biter, og bunker gemmer på tværs af klyngen. | Data gemt i tabelformatet i HDFS. HBase gemmer data som nøgle / værdipar. |
| Anvendelsesområde | I Hadoop har HDFS en fast arkitektur, som ikke tillader ændringer. Det understøtter ikke dynamisk lagring. | HBase tillader ændringer i løbetid og kan bruges til fristående applikationer. |
| Fleksibilitet til at læse-skrive | Hadoop giver HDFS mulighed for at læse mange gange, men skrive en gang. | HBase er praktisk til flere læsning af data, der er gemt i HDFS |
| Tilgængelighed og tilgængelig | Meget tilgængelig og hurtigt tilgængelig som data, der er gemt på forskellige noder. | Datasæt er tilgængelige og let tilgængelige |
| Skalerbarhed | Flere noder kan tilføjes til klynge og dermed meget skalerbare. | En enorm mængde data kan gemmes. |
Konklusion - Hadoop vs HBase
Hadoop-arkitektur hovedsageligt baseret på HDFS og MapReduce. HBase er den understøttende komponent i Hadoop-systemet. HBase er i stand til at være vært for store tabeller og giver hurtig tilfældig adgang til tilgængelige data, mens HDFS er velegnet til opbevaring af store filer. Både Hadoop og HBase giver hurtig adgang til data, men med HBase kan læse / skriv-operationer udføres, og for HDFS læses mange gange og en gang kan skrivning udføres. Denne artikel beskrev en forståelse af Hadoop og HBase, kort fremhævede funktioner og sammenlignet med omhu.
Anbefalet artikel
- Apache Hadoop vs Apache Spark | Top 10 sammenligninger, du skal vide!
- Hadoop vs Hive - Find ud af de bedste forskelle
- HBase vs Cassandra - Hvilken der er bedre (Infographics)
- Top 12 sammenligning af Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Spark: Hvad er funktionerne