
Introduktion til Bagging and Boosting
Bagging and Boosting er de to populære Ensemble-metoder. Så før vi forstå Bagging and Boosting, lad os få en idé om, hvad der er ensemble Learning. Det er teknikken at bruge flere indlæringsalgoritmer til at træne modeller med det samme datasæt for at få en forudsigelse i maskinlæring. Når vi har fået forudsigelsen fra hver model, vil vi bruge gennemsnitsteknikker til modeller som vægtet gennemsnit, varians eller maksimal stemme for at få den endelige forudsigelse. Denne metode sigter mod at opnå bedre forudsigelser end den individuelle model. Dette resulterer i bedre nøjagtighed og undgår overfitting og reducerer bias og co-varians. To populære ensemble-metoder er:
- Bagging (Bootstrap Aggregating)
- Øget
bagging:
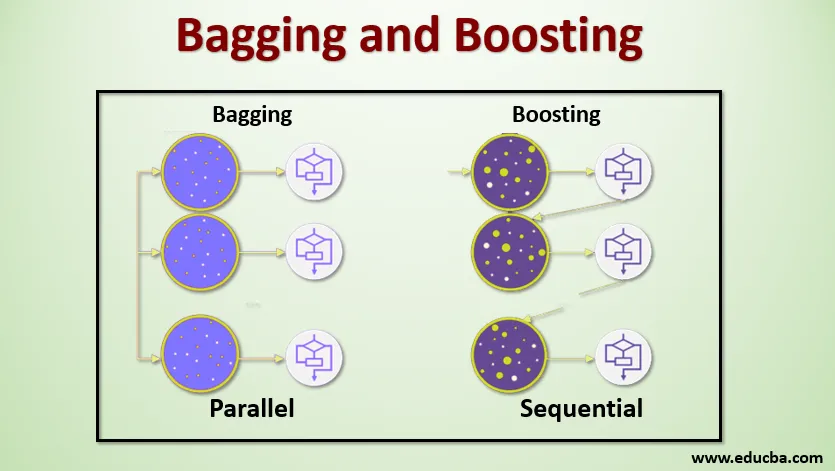
Bagging, også kendt som Bootstrap Aggregating, bruges til at forbedre nøjagtigheden og gør modellen mere generaliseret ved at reducere variansen, dvs. ved at undgå overmontering. I dette tager vi flere undergrupper af træningsdatasættet. For hvert undersæt tager vi en model med de samme indlæringsalgoritmer som beslutningstræ, logistisk regression osv. For at forudsige output for det samme sæt testdata. Når vi først har en forudsigelse fra hver model, bruger vi en model for gennemsnitsteknik til at få den endelige forudsigelsesudgang. En af de berømte teknikker, der bruges i Bagging, er Random Forest . I den tilfældige skov bruger vi flere beslutnings træer.
Boosting :
Boosting bruges primært til at reducere bias og varians i en overvåget læringsteknik. Det henviser til familien af en algoritme, der konverterer svage elever (baselærer) til stærke elever. Den svage lærer er klassifikatorerne, der kun er korrekte i en lille grad med den faktiske klassificering, mens de stærke elever er klassifikatorerne, der er godt korreleret med den faktiske klassificering. Få berømte teknikker til Boosting er AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Så vi ved nu, hvad bagging og boosting er, og hvad er deres roller i maskinlæring.
Arbejde med bagging og boosting
Lad os nu forstå, hvordan bagging og boosting fungerer:
afsækningskapacitet
For at forstå, hvordan Bagging fungerer, skal du antage, at vi har et N antal modeller og et datasæt D. Hvor m er antallet af data, og n er antallet af funktioner i hver data. Og vi formodes at gøre binær klassificering. Først deler vi datasættet. På nuværende tidspunkt vil vi kun opdele dette datasæt i trænings- og testsæt. Lad os kalde træningsdatasættet som hvor det samlede antal træningseksempler er.
Tag en prøve af poster fra træningssættet, og brug den til at træne den første model siger m1. For den næste model skal m2 genprøve træningssættet og tage en anden prøve fra træningssættet. Vi vil gøre det samme for N-antallet af modeller. Da vi sampler træningsdatasættet og tager prøverne fra det uden at fjerne noget fra datasættet, kan det være muligt, at vi har to eller flere træningsdataposter, der er fælles i flere prøver. Denne teknik til at resample træningsdatasættet og levere prøven til modellen kaldes Row Sampling with Replacement. Antag, at vi har trænet hver model, og nu vil vi se forudsigelsen på testdata. Da vi arbejder med binær klassificering, kan output være enten 0 eller 1. Testdatasættet overføres til hver model, og vi får en forudsigelse fra hver model. Lad os sige, at ud af N-modeller mere end N / 2-modeller forudsagde det at være 1, og derfor kan vi sige, at det forudsagte output for testdataene er 1 ved at anvende gennemsnitsteknikken til modellen.
Øget
I boosting tager vi poster fra datasættet og videregiver det til baseleverende i rækkefølge. Her kan baseleverandører være enhver model. Antag, at vi har et antal poster i datasættet. Derefter passerer vi et par poster til at basere den studerende BL1 og træne den. Når BL1 er blevet trænet, videregiver vi alle poster fra datasættet og ser, hvordan Base-eleven fungerer. For alle poster, der er klassificeret ukorrekt af baselæreren, tager vi dem kun og videregiver den til andre baselever sige BL2 og samtidig videregiver vi de forkerte poster klassificeret af BL2 til at trene BL3. Dette fortsætter, medmindre og indtil vi specificerer et specifikt antal basistudentmodeller, vi har brug for. Endelig kombinerer vi output fra disse basalærere og skaber en stærk lærer, som et resultat bliver modelens forudsigelsesstyrke forbedret. Okay. Så nu ved vi, hvordan Bagging and Boosting fungerer.
Fordele og ulemper ved bagging og boosting
Nedenfor er de vigtigste fordele og ulemper.
Fordele ved bagging
- Den største fordel ved bagging er, at flere svage elever kan arbejde bedre end en enkelt stærk lærer.
- Det giver stabilitet og øger nøjagtigheden af maskinlæringsalgoritmen, der bruges til statistisk klassificering og regression.
- Det hjælper med at reducere variansen, dvs. det undgår overfitting.
Ulemper ved bagging
- Det kan resultere i høj forspænding, hvis det ikke er modelleret korrekt, og dermed kan resultere i underfitting.
- Da vi skal bruge flere modeller, bliver det beregningsmæssigt dyrt og er muligvis ikke egnet i forskellige anvendelsestilfælde.
Fordele ved at øge
- Det er en af de mest succesrige teknikker til løsning af klasserne i to klasses problemer.
- Det er godt til at håndtere de manglende data.
Ulemper ved at øge
- Boosting er svært at implementere i realtid på grund af den øgede kompleksitet af algoritmen.
- Høj fleksibilitet af denne teknik resulterer i et flere antal parametre, end det har en direkte indflydelse på opførslen af modellen.
Konklusion
Den vigtigste afhentning er, at Bagging and Boosting er et maskinlæringsparadigme, hvor vi bruger flere modeller til at løse det samme problem og få en bedre ydelse. Hvis vi kombinerer svage elever korrekt, kan vi opnå en stabil, nøjagtig og en robust model. I denne artikel har jeg givet et grundlæggende overblik over Bagging and Boosting. I de kommende artikler vil du lære de forskellige teknikker, der bruges i begge dele, at kende. Til sidst vil jeg afslutte med at minde dig om, at Bagging and Boosting er blandt de mest anvendte teknikker til ensemblæring. Den virkelige kunst til at forbedre ydelsen ligger i din forståelse af, hvornår du skal bruge hvilken model, og hvordan du indstiller hyperparametrene.
Anbefalede artikler
Dette er en guide til Bagging and Boosting. Her diskuterer vi introduktionen til bagging og boosting, og det arbejder sammen med fordele og ulemper. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Introduktion til ensembleteknikker
- Kategorier af maskinlæringsalgoritmer
- Gradient Boosting Algorithm med prøvekode
- Hvad er den boostende algoritme?
- Sådan opretter du beslutningstræ?