
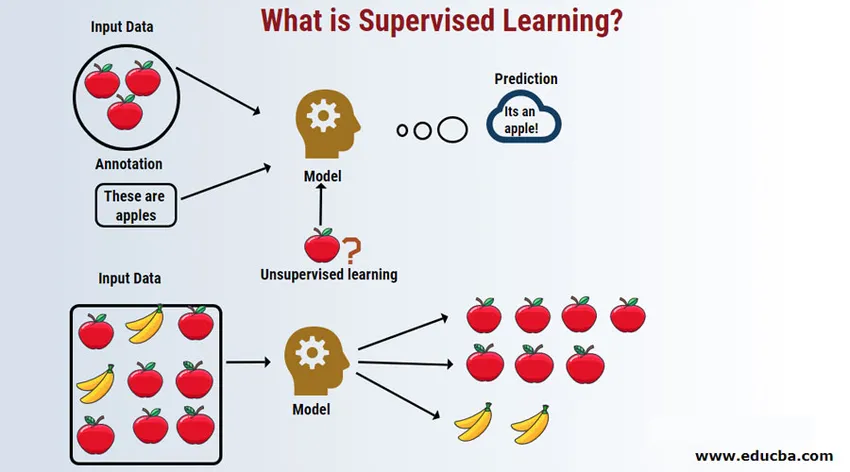
Introduktion til Supervised Learning
Supervised Learning er et område inden for maskinlæring, hvor vi arbejder på at forudsige værdierne ved hjælp af mærkede datasæt. De mærkede inputdatasæt kaldes den uafhængige variabel, mens de forudsagte resultater kaldes den afhængige variabel, fordi de afhænger af den uafhængige variabel for deres resultater. For eksempel har vi alle spam-mapper i vores e-mail-konto (f.eks. Gmail), som automatisk registrerer de fleste af spam / svindel-e-mails til dig med en nøjagtighed på over 95%. Det fungerer baseret på en overvåget læringsmodel, hvor vi har et træningssæt med mærkede data, som i dette tilfælde er mærket spam-e-mail, der er markeret af brugerne. Disse træningssæt bruges til læring, som senere vil blive brugt til kategorisering af nye e-mails som spam, hvis det passer til kategorien.
Arbejder med overvåget maskinlæring
Lad os forstå overvåget maskinlæring ved hjælp af et eksempel. Lad os sige, at vi har frugtkurv, der er fyldt med forskellige frugtsarter. Vores job er at kategorisere frugter baseret på deres kategori.
I vores tilfælde har vi overvejet fire typer frugter, og disse er æble, banan, druer og appelsiner.
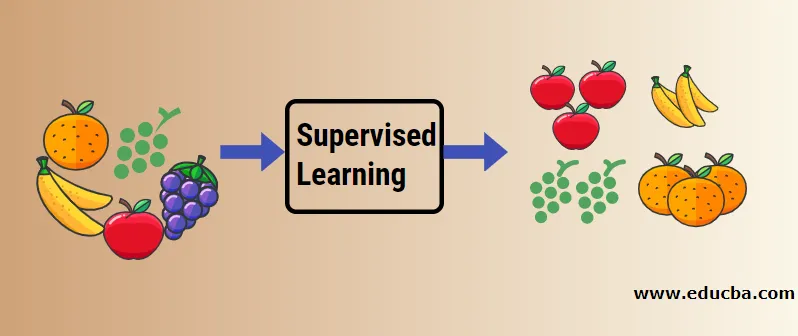
Nu vil vi prøve at nævne nogle af de unikke egenskaber ved disse frugter, der gør dem unikke.
|
S Nej | Størrelse | Farve | Form |
Fornavn |
|
1 | Lille | Grøn | Rund til oval, bunkeform cylindrisk |
Grape |
|
2 | Stor | Rød | Afrundet form med en depression øverst |
Æble |
|
3 | Stor | Gul | Lang buet cylinder |
Banan |
| 4 | Stor | orange | Rundet form |
orange |
Lad os nu sige, at du har hentet en frugt fra frugtkurven, du kiggede på dens egenskaber, f.eks. For dets form, størrelse og farve, og så udleder du, at farven på denne frugt er rød, størrelsen hvis stor, formen er afrundet form med depression i toppen, derfor er det et æble.
- Ligeledes gør du det samme for alle andre resterende frugter også.
- Den højre kolonne (“Fruit Name”) er kendt som responsvariablen.
- Sådan formulerer vi en overvåget læringsmodel, nu vil det være ret let for enhver ny (Lad os sige en robot eller en udlænding) med givne egenskaber til let at gruppere den samme type frugt sammen.
Typer af overvåget maskinlæringsalgoritme
Lad os se forskellige typer maskinlæringsalgoritmer:
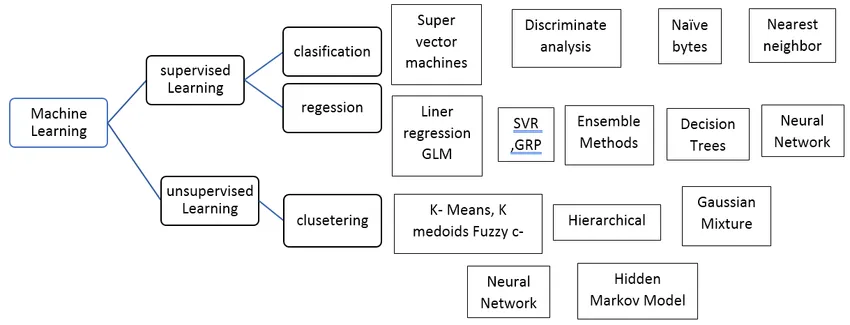
Regression:
Regression bruges til at forudsige output af en enkelt værdi ved hjælp af træningsdatasættet. Outputværdien kaldes altid som den afhængige variabel, mens inputene er kendt som den uafhængige variabel. Vi har forskellige typer regression i Supervised Learning, f.eks.
- Lineær regression - Her har vi kun en uafhængig variabel, der bruges til at forudsige output dvs. afhængig variabel.
- Multipel regression - Her har vi mere end en uafhængig variabel, der bruges til at forudsige output, dvs. den afhængige variabel.
- Polynomial regression - Her følger grafen mellem de afhængige og uafhængige variabler en polynomial funktion. For f.eks. Øges hukommelsen med alderen, derefter når den en tærskel ved en bestemt alder, og derefter begynder den at falde, når vi bliver gamle.
Klassifikation:
Klassificeringen af overvågede læringsalgoritmer bruges til at gruppere lignende objekter i unikke klasser.
- Binær klassificering - Hvis algoritmen forsøger at gruppere 2 forskellige grupper af klasser, kaldes den binær klassificering.
- Multiklasseklassificering - Hvis algoritmen forsøger at gruppere objekter til mere end 2 grupper, kaldes den multiklasseklassificering.
- Styrke - Klassificeringsalgoritmer fungerer normalt meget godt.
- Ulemper - tilbøjelig til overfitting og kan muligvis være ubegrænset. For eksempel - E-mail-spam-klassifikator
- Logistisk regression / klassificering - Når Y-variablen er en binær kategori (dvs. 0 eller 1), bruger vi Logistisk regression til forudsigelse. F.eks . Forudsigelse af, om en given kreditkorttransaktion er svig eller ej.
- Naïve Bayes klassifikatorer - Naïve Bayes klassifikator er baseret på det bayesiske sætning. Denne algoritme er normalt bedst egnet, når dimensionerne af input er høj. Det består af acykliske grafer, der har en forælder og mange børnknudepunkter. Børneknuderne er uafhængige af hinanden.
- Beslutningstræer - Et beslutningstræ er et trækortlignende struktur, der består af en intern knude (test på attribut), gren, der angiver resultatet af testen og bladknudepunkterne, der repræsenterer fordelingen af klasser. Rodenoden er den øverste knude. Det er en meget anvendt teknik, der bruges til klassificering.
- Support Vector Machine - En supportvektormaskine er, eller en SVM udfører jobbet med klassificering ved at finde hyperplanet, der skal maksimere margenen mellem 2 klasser. Disse SVM-maskiner er forbundet til kernefunktionerne. Felter, hvor SVM'er bruges vidt, er biometri, mønstergenkendelse osv.
Fordele
Nedenfor er nogle af fordelene ved modellerede maskinlæringsmodeller:
- Modellenes ydelse kan optimeres af brugeroplevelserne.
- Overvåget læring producerer output ved hjælp af tidligere erfaring og giver dig også mulighed for at indsamle data.
- Overvågede maskinlæringsalgoritmer kan bruges til at implementere en række reelle problemer.
Ulemper
Ulemperne ved Overvåget læring er som følger:
- Arbejdet med at uddanne overvågede modeller for maskinlæring kan tage meget tid, hvis datasættet er større.
- Klassificeringen af big data udgør undertiden en større udfordring.
- Man kan være nødt til at håndtere problemerne med overfitting.
- Vi har brug for mange gode eksempler, hvis vi ønsker, at modellen skal fungere godt, mens vi træner klassificeren.
God praksis, mens du bygger læringsmodeller
Det er en god praksis, mens du bygger en Supervised Learning Machine Models: -
- Inden der bygges en god maskinlæringsmodel, skal processen med forbehandling af data udføres.
- Man skal beslutte den algoritme, der skal være bedst egnet til et givet problem.
- Vi er nødt til at beslutte, hvilken type data der skal bruges til træningssættet.
- Skal træffe beslutning om strukturen af algoritmen og funktionen.
Konklusion
I vores artikel har vi lært, hvad der er overvåget læring, og vi så, at vi her træner modellen ved hjælp af mærkede data. Derefter gik vi ind i arbejdet med modellerne og deres forskellige typer. Endelig så vi fordele og ulemper ved disse overvågede maskinlæringsalgoritmer.
Anbefalede artikler
Dette er en guide til, hvad der er Supervised Learning ?. Her diskuterer vi koncepterne, hvordan det fungerer, typer, fordele og ulemper ved Supervised Learning. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Hvad er dyb læring
- Overvåget læring vs dyb læring
- Hvad er synkronisering i Java?
- Hvad er webhosting?
- Måder at oprette beslutningstræ med fordele
- Polynomial regression | Anvendelser og funktioner