

Introduktion til Hashing i DBMS
Når vi taler om den enorme databasestruktur og deres kompleksitet, bliver det meget ineffektivt at søge efter alle indekser, og at nå ønskede data bliver meget vag og en kompleks mulighed. Ved at gøre brug af hashteknikken kan disse tilstande nås, og en direkte markør kan tildeles for at kende det nøjagtige og den direkte placering på disken for den bestemte post uden at gøre brug af den komplekse indeksstruktur. Dataene i tilfælde af hashing-teknik gemmes i form af datablokke, hvis adresse genereres ved at gøre brug af funktionen, der typisk kaldes hashing-funktionen. Placeringen i hukommelsen, hvor denne er bosiddende og poster gemmes, kaldes datablokke eller datapand.
Typer af Hashing i DBMS
Der er typisk to typer hashing-teknikker i DBMS:
1. Statisk Hashing
2. Dynamisk Hashing
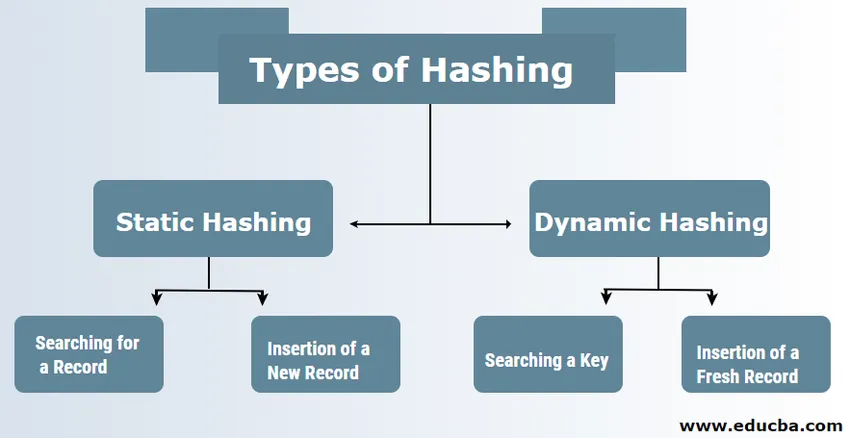
1) Statisk Hashing
I tilfælde af statisk hashing er det dannede datasæt og spandeadressen den samme. Dette betyder, at hvis vi forsøger at generere adressen til USER_ID = 113 ved at gøre brug af hashfunktionsmodulet 5, giver den os altid resultanten som 3 med den samme udseende spandeadresse. I dette tilfælde vil der ikke være nogen ændring i adressen på den leverede spand. Derfor forbliver antallet af spande konstant under hele operationen.
Betjening af statisk maskinskrivning
en. Søgning efter en post: Hvis der er behov for, at posten findes, bruges den nøjagtige samme hashing-funktion til at hente adressen og stien til datapanden med de data, der gemmes.
b. Indsættelse af en ny post: Hvis en ny og frisk post sættes i en tabel, genereres der en adresse til en ny post baseret på hash-nøglen, hvorved posten gemmes på det sted.
- Sletning af posten : For at posten skal slettes, skal den post først hentes, som kan slettes. Når denne opgave er udført, skal posterne slettes for den hukommelsesadresse.
- Opdatering af en post: For at opdatere posten søger vi først posten ved at bruge den hash-baserede funktion, og når dette er gjort, kan det siges, at vores datapost er i en opdateret tilstand. For at vi kan indsætte en ny post i filen, og den adresse, der genereres fra den hash-baserede funktion og datapanden er ikke tom, eller hvis dataene allerede er til stede i den angivne adresse. Denne situation, der især opstår i tilfælde af statisk hashing, kan være bedre kaldet spandoverløb, og derfor er der nogle måder, der bruges til at overvinde dette problem, såsom:
(i) Open Hashing: Hvis en hashfunktion genererer den adresse, som dataene allerede kan ses i den gemte tilstand, i dette tilfælde tildeles det næste niveau af spanden automatisk. Denne mekanisme kan betegnes som en lineær sonderingsteknik.
For eksempel, hvis R3 er den friske adresse, der skal sættes, genererer den hash-baserede funktion adresse som nummer 102 for R3-adressen. Den genererede adresse er i fuld tilstand, og systemet er derfor beregnet til at søge efter den nye datakuffer, der er 113 og tildele R3 til den datakammer.
(ii) Closed Hashing: Når skovlerne er helt fyldte, tildeles der derefter en ny spand til et bestemt hashresultat, som er knyttet lige efter det, der er afsluttet tidligere, og derfor kaldes denne metode til at være overløbskædeteknikker.
F.eks. Er R3 den friske adresse, der kræves anbragt i den nye tabel, hashingfunktionen bruges til at generere adresse som nummer 110 til den. Denne spand er til gengæld fuld og kan derfor ikke modtage nye data, og derfor sættes en frisk spand til slut efter 100.
2) Dynamisk Hashing
Denne form for hashbaseret metode kan bruges til at løse de grundlæggende problemer med statisk baseret hashing som dem som f.eks. Spandoverløb, da dataskufferne kan vokse og krympe med den størrelse, det er mere pladsoptimeret teknik, og derfor kaldes det for at kunne udvides hash-baseret metode. I denne metode gøres hasningen dynamisk, hvilket betyder, at indsættelsesaktivitet eller sletning er tilladt uden at gå i at give dårlige resultater.
en. Søge efter en nøgle: Beregn den hashbaserede adresse på den krævede nøgle og kontroller antallet af bits, der bruges i tilfælde af et bibliotek, der kaldes i. Derefter tages de, der er mindst betydningsfulde af I-bitene, fra det bibliotek, der giver en idé om indekset fra biblioteket. Ved at gøre brug af denne indeksværdi, gå ind i biblioteket for at finde spandeadressen til at søge efter de nuværende poster.
b. Indsættelse af en frisk post: Til at begynde med skal du følge nøjagtigt den samme hentningsprocedure, som skal ende et eller andet sted i spanden. Søg efter plads i den spand, og sæt derefter posterne inde i den. Hvis den oprettede spand er komplet og fuld, vil spanden blive delt, og posterne bliver distribueret.
F.eks. Er de sidste to bit af cifrene 2 og 4 00. Så de vil gå i spanden B0 og så videre frem efter modulfunktionen. Nøgle 9 har en adresse på 10001, der skal være til stede i den første spand, men vil blive splittet og vil flytte til den nye spand B1, og dette fortsætter, indtil alle spande og taster er dynamisk hashede. Hash-funktionen bruges på en måde, hvor hash-funktionen bruges til at vælge kolonnen og dens værdi til at generere adressen. Maksimum gange hash-funktionen bruger den primære nøgle, der igen bruges til at generere adresserne på datablokken. Det er en simpel matematisk funktion, hvor den primære nøgle også kan betragtes som datablokkeadressen, hvilket betyder, at hver række med den samme adresse som den for den primære nøgle gemmes i datablokken.
Anbefalede artikler
Dette er en guide til Hashing i DBMS. Her diskuterer vi introduktionen og forskellige typer hashing i DBMS, der inkluderer en statisk hashing og dynamisk hashing sammen med eksempler. Du kan også se på de følgende artikler for at lære mere -
- Datamodeller i DBMS
- Fordele ved DBMS
- Dataintegrationsværktøj
- Hvad er RDBMS?