

Introduktion til Map Join in Hive
Map join er en funktion, der bruges i Hive-forespørgsler for at øge dens effektivitet med hensyn til hastighed. Deltag er en betingelse, der bruges til at kombinere dataene fra 2 tabeller. Så når vi udfører en normal sammenføjning, sendes jobbet til en kort-reducer-opgave, der deler hovedopgaven i 2 trin - “Kortfase” og “Reducer fase”. Kortstadiet fortolker inputdataene og returnerer output til reduktionsstadiet i form af nøgleværdipar. Dette næste går gennem shuffle-scenen, hvor de sorteres og kombineres. Reduceringsenheden tager denne sorterede værdi og afslutter sammenføjningsjobbet.
En tabel kan indlæses helt i hukommelsen i en kortlægning og uden at skulle bruge Map / Reducer-processen. Den læser dataene fra den mindre tabel og gemmer dem i en hash-tabel i hukommelsen og derefter serialiserer den til hashhukommelsesfil og reducerer tiden betydeligt. Det er også kendt som Map Side Join in Hive. Grundlæggende involverer det udførelse af sammenføjninger mellem 2 borde ved kun at bruge kortfasen og springe over reduktionsfasen. Et tidsfald i beregningen af dine forespørgsler kan ses, hvis de regelmæssigt bruger en lille tabelforbindelse.
Syntaks for kort Deltag i Hive
Hvis vi ønsker at udføre en joinforespørgsel ved hjælp af map-join, skal vi specificere et nøgleord “/ * + MAPJOIN (b) * /” i erklæringen som nedenfor:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Til dette eksempel er vi nødt til at oprette 2 tabeller med navne tablename1 og tablename2 med 2 kolonner: emp_id og emp_name. Den ene skal være en større fil og den anden skal være en mindre.
Før vi kører forespørgslen, skal vi indstille nedenstående egenskab til sand:
hive.auto.convert.join=true
Samlingsforespørgslen til kortforbindelse er skrevet som ovenfor, og resultatet, vi får, er:
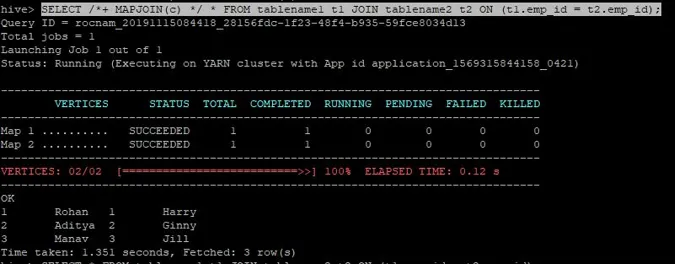
Forespørgslen blev afsluttet på 1.351 sekunder.
Eksempler på Map Join in Hive
Her er følgende eksempler nævnt nedenfor
1. Kort tilslutningseksempel
For dette eksempel, lad os oprette 2 tabeller med navnet tabel1 og tabel2 med henholdsvis 100 og 200 poster. Du kan henvise nedenstående kommando og skærmbilleder til at udføre det samme:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

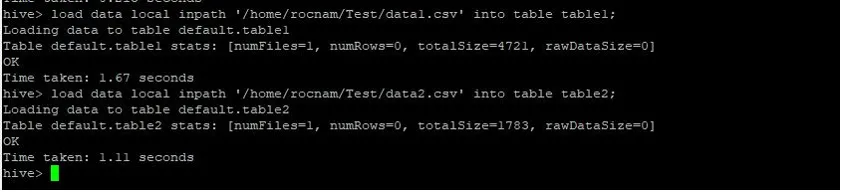
Nu indlæser vi posterne i begge tabeller ved hjælp af kommandoer nedenfor:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Lad os udføre en normal kortforbindelsesforespørgsel på deres ID'er som vist nedenfor og verificere den tid, det tager for det samme:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
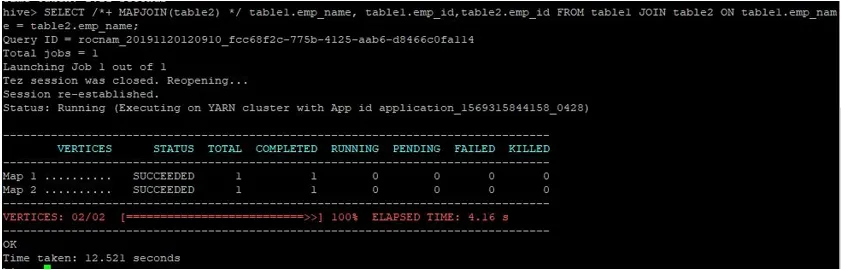
Som vi kan se, tog en normal forespørgsel efter kortforbindelse 12.521 sekunder.
2. Eksempel på sammenkobling af bucket-map
Lad os nu bruge Bucket-map join til at køre det samme. Der er et par begrænsninger, der skal følges for bucketing:
- Skovlerne kan kun forbindes med hinanden, hvis de samlede spande i en tabel er flere end antallet af spande i den anden tabel.
- Skal have bucketede borde for at udføre bucketing. Lad os derfor skabe det samme.
Følgende er de kommandoer, der bruges til at oprette bucketede tabeller tabel1 og tabel2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Vi indsætter også de samme poster fra tabel 1 i disse spændende tabeller:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
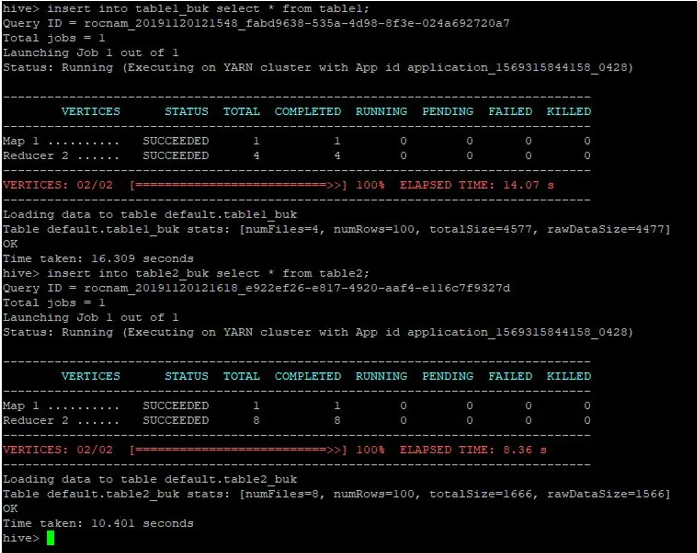
Nu hvor vi har vores 2 spændende borde, så lad os udføre en spandskortsamling på disse. Den første tabel har 4 spande, mens den anden tabel har 8 spande oprettet i den samme kolonne.
For at forespørgsel om spænd-kort-sammenføjning skal fungere, skal vi indstille nedenstående egenskab til sand i bikuben:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
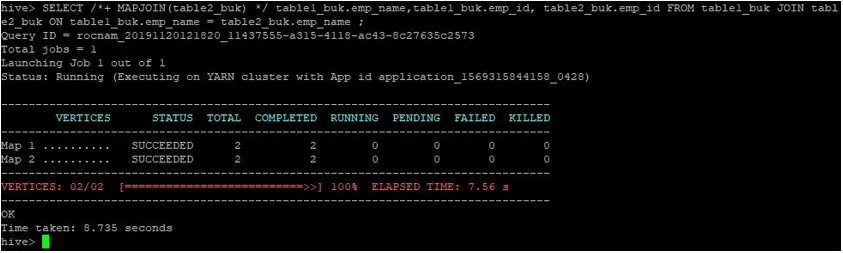
Som vi kan se, forespørgslen blev afsluttet på 8.735 sekunder, hvilket er hurtigere end et normalt kortforbindelse.
3. Sorter eksempel på sammenføjningspandskort (SMB)
SMB kan udføres på spændte borde med samme antal spande, og hvis tabellerne skal sorteres og spændes i sammenføjningskolonner. Mapper-niveau slutter sig tilsvarende til disse spande.
Samme som i skovlkortforbindelse er der 4 spande til tabel1 og 8 spande til tabel2. I dette eksempel opretter vi en anden tabel med 4 spande.
For at køre SMB-forespørgsel skal vi indstille følgende bikiveegenskaber som vist nedenfor:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = sandt;
hive.optimize.bucketmapjoin.sortedmerge = sandt;
For at udføre SMB-sammenknytning skal der sorteres data pr. Sammenføjningskolonner. Derfor overskriver vi dataene i tabel1, der er bucketed som nedenfor:
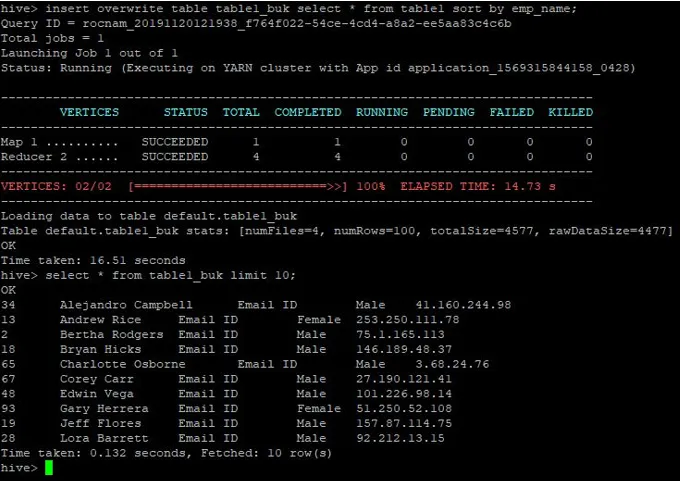
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Dataene er sorteret nu, hvilket kan ses i nedenstående skærmbillede:
Vi vil også overskrive data i bucketed tabel2 som nedenfor:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Lad os udføre sammenføjningen til ovenstående 2 tabeller som følger:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
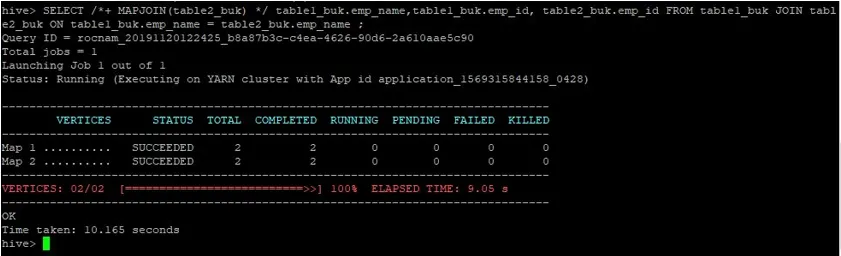
Vi kan se, at forespørgslen tog 10.165 sekunder, hvilket igen er bedre end et normalt kortforbindelse.
Lad os nu oprette en anden tabel til tabel2 med 4 spande og de samme data sorteret med emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
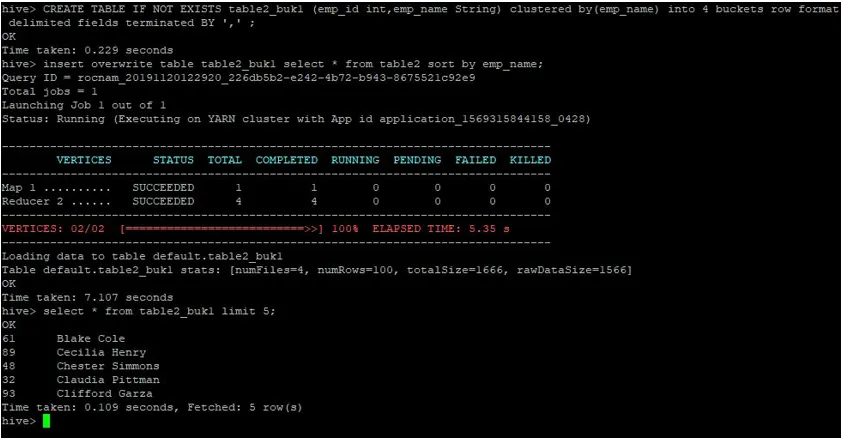
I betragtning af at vi nu har begge borde med 4 spande, så lad os igen udføre en sammenkoblingsforespørgsel.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Forespørgslen har taget 8.851 sekunder igen hurtigere end den normale kortforbindelseforespørgsel.
Fordele
- Kortforbindelse reducerer den tid, det tager at sortere og flette processer, der finder sted i blandingen, og reducere trin og minimerer dermed også omkostningerne.
- Det øger effektiviteten af opgaven.
Begrænsninger
- Den samme tabel / alias må ikke bruges til sammenføjning af forskellige kolonner i den samme forespørgsel.
- Forespørgsel efter kortforbindelse kan ikke konvertere Fuld ydre sammenføjning til kortsideforbindelser.
- Kortforbindelse kan kun udføres, når et af tabellerne er lille nok, så det kan passe til hukommelsen. Derfor kan det ikke udføres, hvor tabeldataene er enorme.
- En venstre sammenføjning er kun mulig at udføre til et kortforbindelse, når den rigtige bordstørrelse er lille.
- Det er muligt at udføre en højre sammenføjning til et kortforbindelse, når den venstre bordstørrelse er lille.
Konklusion
Vi har forsøgt at medtage de bedst mulige punkter på Map Join in Hive. Som vi har set ovenfor, fungerer Map-side-sammenlægning bedst, når en tabel har mindre data, så jobbet hurtigt afsluttes. Den tid, det tager for de forespørgsler, der vises her, afhænger af størrelsen på datasættet, og den tid, der vises her, er kun til analyse. Map join kan let implementeres i realtid applikationer, da vi har enorme data og dermed hjælper med at reducere netværkets I / O-trafik.
Anbefalede artikler
Dette er en guide til Map Join in Hive. Her diskuterer vi eksemplerne på Map Join in Hive sammen med fordele og begrænsninger. Du kan også se på den følgende artikel for at lære mere -
- Deltager i Hive
- Hive indbyggede funktioner
- Hvad er en bikube?
- Hive-kommandoer