

Forskellen mellem Apache Nifi og Apache Spark
Indtil længe, hvor der var et tungt arbejde, der skulle afsluttes, stole folk på heste for at trække tunge byrder, opretholde hastigheden eller noget andet derimellem. Dog var ikke alle heste egnede til enhver opgave. Det samme er tilfældet med teknologi i dag. Med fremkomsten af nye teknologier, der strømmer ind hver dag, bliver det ekstremt vigtigt at kende deres rigtige applikationer. To sådanne teknologier er Apache Nifi og Apache Spark, og vi vil studere om dem i dette indlæg.
Apache Spark er en cluster computing open source-ramme, der sigter mod at tilvejebringe en grænseflade til programmering af hele sæt klynger med implicit fejletolerance og dataparallelitet. Den gør brug af RDD'er (Resilient Distribuerede datasæt) og behandler dataene i form af diskretiserede strømme, som yderligere bruges til analytiske formål.
Apache Nifi (som er den korte form for NiagaraFiles) er et andet softwareprojekt, der sigter mod at automatisere dataflyten mellem softwaresystemer. Designet er baseret på flowbaseret programmeringsmodel, der giver funktioner, der inkluderer drift med klyngens evne. Det er et nemt at bruge, pålideligt og et kraftfuldt system til at behandle og distribuere data. Det understøtter skalerbare rettede grafer til dataruting, systemformidling og transformationslogik. Lad os diskutere sammenligningerne mellem begge emner.
Head to head sammenligning mellem Apache Nifi vs Apache Spark (Infographics)
Nedenfor er top 9 sammenligning mellem Apache Nifi vs Apache Spark
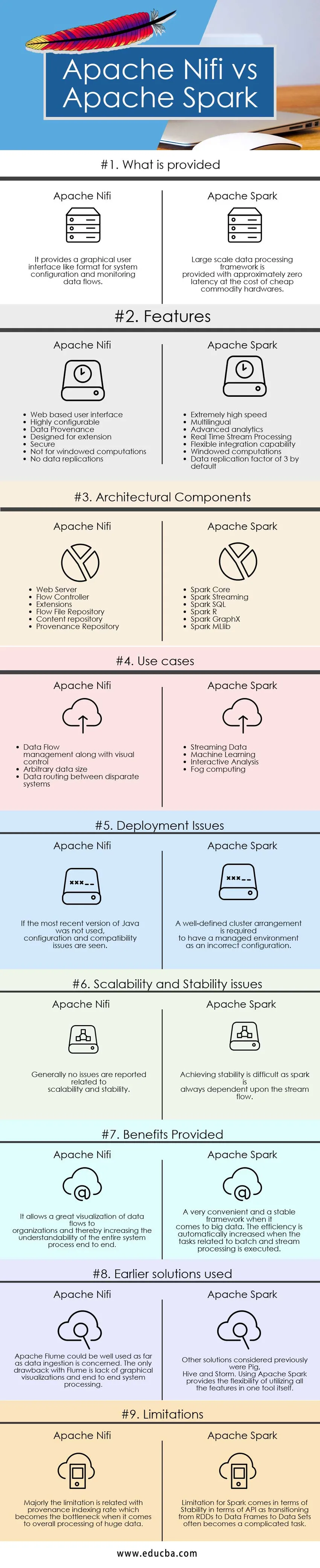
Vigtige forskelle mellem Apache Nifi vs Apache Spark
Forskellene mellem Apache Nifi og Apache Spark forklares i nedenstående punkter:
- Apache Nifi er et dataindtagelsesværktøj, der bruges til at levere et let at bruge, kraftfuldt og et pålideligt system, så behandling og distribution af data over ressourcer bliver let, hvorimod Apache Spark er en ekstremt hurtig klynge computerteknologi, der er designet til hurtigere beregning af effektiv anvendelse af interaktive forespørgsler i hukommelsesstyring og strømbehandlingsfunktioner.
- Apache Nifi fungerer i standalone mode og en cluster mode, mens Apache Spark fungerer godt i lokal eller standalone mode, Mesos, Garn og andre former for big data cluster tilstande.
- Funktioner i Apache Nifi inkluderer garanteret levering af data, effektiv datapuffering, Prioriteret kø, Flow Specific QoS, Data Provenance, Recovery af rullebuffer, Visuel kommando og kontrol, Flow skabeloner, Sikkerhed, Parallel Streaming kapaciteter, mens funktioner i apache gnist inkluderer lynet hurtigt hastighedsbearbejdningsmulighed, flersproget, in-memory computing, effektiv udnyttelse af hardware hardware systemer, avanceret analyse, effektiv integration kapacitet.
- Apache Nifi giver en bedre læsbarhed og generel forståelse af systemet ved at tilvejebringe visualiseringsfunktioner og træk og slip-funktioner. Dataflyten kan let styres og styres ved hjælp af konventionelle teknikker og processer, hvorimod i tilfælde af Apache Spark for at se disse slags visualiseringer er der behov for et klyngestyringssystem som Ambari. Apache Spark giver i sig selv ikke visualiseringsfunktioner og er kun god for så vidt angår programmering. Det er langt et meget praktisk og stabilt system til behandling af enorme mængder data.
- Begrænsningen med Apache Nifi er relateret til, hvad der er dens fordel. Den eneste træk-og-slip-funktion giver en begrænsning af, at det ikke er i stand til at skalere og give robusthed, når det kommer til at integrere det med andre komponenter og værktøjer, mens i tilfælde af Apache Spark kommer den primære begrænsning sammen med brugen af omfattende råvareshardware og håndtering af dem bliver til tider en kedelig opgave. Den anden rapporterede begrænsning kommer sammen med dens streamingfunktioner relateret til Diskretiseret strøm og Windowed eller batch-strøm, hvor omdannelsen af RDD'er til dataramme og datasæt giver en årsag til ustabilitet til tider.
Apache Nifi vs Apache gnist-sammenligningstabel
| Grundlag for sammenligning | Apache Nifi | Apache gnist |
| Hvad der leveres | Det giver en grafisk brugergrænseflade som et format til systemkonfiguration og overvågning af datastrømme. | Storskala databehandlingsrammer er forsynet med omtrent nul forsinkelse til prisen for billig råvarehardware. |
| Funktioner |
|
|
| Arkitektoniske komponenter |
|
|
| Brug sager |
|
|
| Problemer med implementering | Hvis den seneste version af Java ikke blev brugt, ses konfigurations- og kompatibilitetsproblemer | En veldefineret klyngeordning kræves for at have et administreret miljø som en forkert konfiguration |
| Problemer med skalerbarhed og stabilitet | Generelt rapporteres der ingen problemer i forbindelse med skalerbarhed og stabilitet | At opnå stabilitet er vanskeligt, da en gnist altid er afhængig af strømmen. |
| Forudsatte fordele | Det giver en stor visualisering af datastrømme til organisationer og derved øger forståelsen af hele systemprocessen ende til ende | En meget praktisk og stabil ramme, når det kommer til big data. Effektiviteten øges automatisk, når opgaverne relateret til batch- og strømbehandling udføres. |
| Tidligere anvendte løsninger | Apache Flume kunne bruges godt, hvad angår indtagelse af data. Den eneste ulempe med Flume er manglen på grafiske visualiseringer og ende til ende systembehandling | Andre tidligere betragtede løsninger var Gris, Hive og Storm. Brug af Apache Spark giver fleksibiliteten ved at bruge alle funktionerne i et værktøj i sig selv. |
| Begrænsninger | Stort set er begrænsningen forbundet med oprindelsesindekseringshastighed, der bliver flaskehalsen, når det kommer til den samlede behandling af enorme data | Begrænsning for gnist kommer med hensyn til stabilitet med hensyn til API, da overgang fra RDD'er til datarammer til datasæt ofte bliver en kompliceret opgave. |
Konklusion - Apache Nifi vs Apache Spark
For at afslutte indlægget kan det siges, at Apache Spark er en tung warhorse, hvorimod Apache Nifi er en kvikk racehest. Begge har deres egne fordele og begrænsninger, der skal bruges på deres respektive områder. Du skal beslutte det rigtige værktøj til din virksomhed. Hold øje med vores blog for flere artikler relateret til nyere teknologier til big data.
Anbefalet artikel
Dette har været en guide til Apache Nifi vs Apache Spark, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Apache Hadoop vs Apache Spark | Top 10 sammenligninger, du skal vide!
- Apache Storm vs Apache Spark - Lær 15 nyttige forskelle
- 7 vigtige ting ved Apache-gnist (guide)
- De 15 bedste ting, du skal vide om MapReduce vs Spark