

Introduktion til Data Engineer Interview Spørgsmål og svar
Datateknik er et udtryk, hvor alle er opmærksomme på det og er ret populære inden for Big Data. Datateknik henviser til datainfrastruktur eller dataarkitektur. Rå data genereret fra forskellige kilder, såsom sociale medier, mobiltelefoner, www (internet), skal transformeres, renses, profileres og aggregeres til forretningsbehov. Disse rå data betegnes også som mørke data. Praksisen med at designe, arkivere og implementere dataprocesystemet hjælper med at konvertere dataene til et stykke passende information eller datasæt, sådan information eller datasæt kaldes Data Engineering.
Nedenfor er listen over de vigtigste 2019 Data Engineer Interview spørgsmål og svar:
Hvis du leder efter et job, der er relateret til Data Engineer, er du nødt til at forberede dig til 2019 Interview Engineer-interviewspørgsmål. Selvom alle spørgsmål fra Data Engineer Interview er forskellige, og omfanget af et job er også anderledes, kan vi hjælpe dig med de bedste Data Engineer Interview spørgsmål med svar, som vil hjælpe dig med at tage spranget og få din succes i din Data Engineer Interview.
1. Hvad er datateknik?
Svar:
Datateknik er et udtryk, der er meget populært inden for Big Data, og det refererer hovedsageligt til datainfrastruktur eller dataarkitektur.
Data genereret af mange kilder som sociale medier, mobiltelefoner, www (internet) er rå data. Det skal transformeres, renses, profileres og aggregeres til forretningsbehov. Vi kan kalde disse rå data som Dark Data, som vi vil skinne lyset på for at gøre disse Dark Data nyttige. Praksisen med at designe, arkivere og implementere dataprocesystemet, som vil hjælpe med at gøre dataene konverteret til nyttige oplysninger kaldes Data Engineering.
2. Forklar det daglige arbejde hos en dataingeniør?
Svar:
Dataingeniør dagligt job består af:
en. håndtering af datatilsyn i organisationen
b. håndtering og vedligeholdelse af kildesystemer til data og iscenesættelsesområder
c. gør ETL eller ELT og datatransformation
d. forenkling af datarensning og forbedring af dataduplicering og opbygning
e. laver ad-hoc dataforespørgselsopbygning og -ekstraktion
Se visualisering nedenfor, der informerer om de ting, som en dataingeniør arbejder på: - 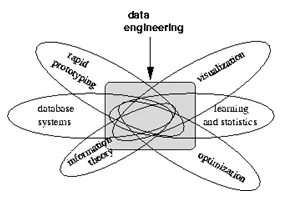
3. Har du erfaring med datamodellering?
Svar:
Man kan sige, at han / hun har arbejdet på et projekt for en finans / sundhedsforsikringsklient, hvor de har brugt ETL-værktøjer som Informatica / Talend / Pentaho osv. Til at transformere og behandle data hentet fra en MySQL / RDS / SQL-database og sender ud disse oplysninger til leverandører, der kan hjælpe med at øge deres indtægter. Man kan vise under højt niveau arkitektur af datamodel. Det består af en primær nøgle, enhed, attributter, forhold, begrænsninger osv.
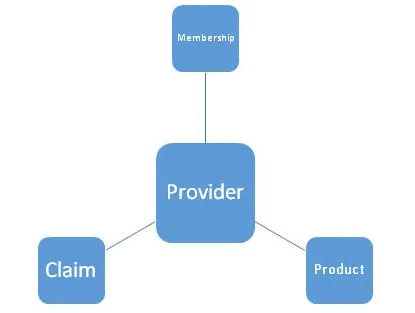
4. Hvad er forskellige typer designskemaer i datamodellering? Forklar med et eksempel?
Svar:
Der er to typer skemaer i datamodellering:
en. Stjerneskema
Dette skema er opdelt i to, en er faktatabel og den anden er dimensionstabel, hvor alle dimensionstabeller er forbundet til en faktabord. Faktisk fremmed-nøglen refererer til de primære nøgler, der findes i dimensionstabeller. Se nedenstående arkitektur af stjerneskema:
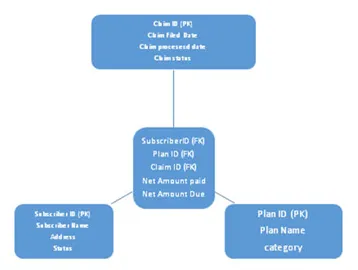
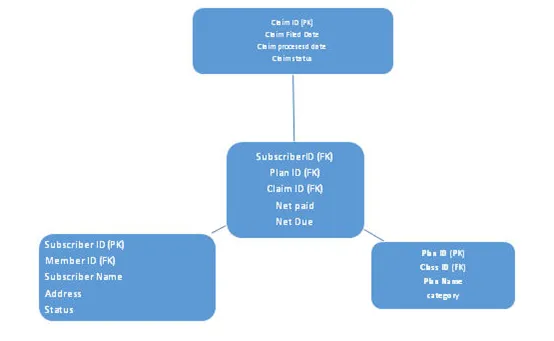
b. Snowflake-skema
I dette skema øges niveauet for normalisering, her vil faktatabellen forblive den samme som for stjerneskema, her normaliseres dimensionstabeller. På grund af mange lag dimensionstabeller ser det ud som et snefnug, således navnet snefnugskema. Se arkitektur nedenfor: -
5. Hvilket ETL-værktøj, du bruger, og hvordan det bedst sammenlignes med andre?
Svar:
Man kan sige, at han / hun har brugt Informatica som ETL-værktøjet på grund af mange punkter, først og fremmest er, at pr. Gartner Magic Quadrant for Data Integration Tools er Informatica positioneret som en leder i det 10. år i træk. Det er let at bruge og lære og har funktioner til at forbinde med en anden række kildedata og datatyper, genanvendelige komponenter og funktioner, der gør det mest favorit for ETL-udviklere. Det har også sin egen scheduler, der er en anden fordel, hvor andre ETL-værktøjer skal bruge en ekstern scheduler til at planlægge jobene.
6. Hvilke teknologier / programmeringssprog skal man have / Lær at være en dataingeniør?
Svar:
Matematik (lineær algebra og sandsynlighed)
Statistik (sammenfattende statistik)
Teknikker til maskinindlæring
R- og SAS-sprog
SQL-databaser, Hive QL
Python (mest brugt)
Bortset fra disse skal man have problemløsning, analytisk og arkitektonisk viden om databasen.
7. Hvad er nogle almindelige problemer, som dataingeniører står overfor?
Svar:
1. Real-time integration / Kontinuerlig integration
2. Opbevaring af enorm datamængde er et problem, oplysningerne fra disse data er et andet problem.
3. Hvilke værktøjer der kan bruges, der giver den bedste ydelse, opbevaring, effektivitet og resultater.
4. Er lagringsskalaen? Antag, hvordan man ved det til behandling af hele datasættet, hvor lang tid det vil tage?
5. Overvej processorer og RAM-konfiguration
6. Hvordan skal man håndtere fejl, er fejltolerance der eller ej?
8. Hvordan adskiller Data Architect fra Data Engineer?
Svar:
Data Architect er den person, der administrerer dataene, især når man beskæftiger sig med forskellige numre af en række datakilder. Man skal have indgående kendskab til, hvordan en database fungerer, hvordan data relateres til forretningsproblemer, og hvordan ændringerne vil forstyrre organisationens dataanvendelse, og derefter vil dataarkitekt manipulere / transformere dataarkitekturen i henhold til dem.
Dataarkitits hovedansvar arbejder med datalagring, udvikling af dataarkitektur eller virksomhedsdatahub / lager.
Mens en datatekniker hjælper med installation af datalagerløsninger, datamodellering, udvikling og test af databasearkitektur.
9. Beskriv et tidspunkt, hvor du fandt en ny brugssag til eksisterende database, der havde en positiv indflydelse på virksomheden?
Svar:
Mens i ælden med Big Data, der har SQL, vil der ikke være funktioner under:
en. RDBMS er skemaorienteret DB, så det er bedre for strukturerede data ikke for semistrukturerede eller ustrukturerede data.
b. Ikke i stand til at behandle uforudsigelige og ustrukturerede data.
c. Det er ikke vandret skalerbart, dvs. parallel udførelse og opbevaring er ikke mulig i SQL.
d. Det lider af ydelsesproblemer, når et antal brugere stiger.
e. Det bruges hovedsageligt til online transaktionsbehandling.
For at overvinde disse ulemper kan vi bruge NoSQL DB, dvs. ikke kun SQL.
Så i projektet kan man bruge forskellige typer NoSQL DB som Cassandra, Mongo DB, Graph DB, HBase osv.
10. Har du erfaring med at arbejde i et cloud computing-miljø? Hvilke fordele kan du se, at du arbejder i en?
Svar:
Man kan sige ja Cloud Computing Environment er klar til at flytte miljø til produktion, udvikling og test uden at tænke på at integrere mange instanser / Linux / windows-servere sammen. Der er forskellige cloud computing-tjenester på et marked som AWS (Amazon webtjenester), Azure (Microsoft), GCP (Google Cloud Platform). Cloud computing-service giver nedenstående funktioner som fleksibilitet, dvs. miljøet skaleres op efter behov, Katastrofegendannelse ved at tage sikkerhedskopier og snapshots, Arbejd overalt med VPN'er, Sikker miljø og miljøvenlig, da det fungerer på råvareshardware, dvs. generelle computere, som har lave omkostninger.
Konklusion
I ovennævnte blog har vi opbevaret de mest stillede interviewspørgsmål om Data Engineer, og hvordan man kan besvare dette ved at give funktionspunkter.
Anbefalet artikel:
Dette har været en omfattende vejledning til Data Engineer Interview Spørgsmål og svar, så kandidaten let kan nedbryde disse Data Engineer Interview Spørgsmål. denne artikel består af alle topspørgsmål og svar på Data Engineer Interviews. Du kan også se på de følgende artikler for at lære mere -
- Vigtigste Azure Paas vs Iaas
- Spørgsmål om Big Data-interview
- 5 vigtigste Elasticsearch-spørgsmål
- PIG-interviewspørgsmål og svar
- Top 5 mest værdifulde spørgsmål om datavidenskab