

Introduktion til Hive-installation
I Hive Installation er der nogle forudsætninger, der skal gøres inden installationen.
Hadoop-komponenter som Hive, Hbase, Pig osv. Understøtter alle Linux-miljøet. Derfor anbefales det at have et Linux-operativsystem på din enhed. Hvis det ikke er tilfældet, og du vil øve dig på bikube, mens du har windows på dit system. Hvad du kan gøre er at installere CDH-maskinen på dit system og bruge den som en platform til at udforske Hadoop. Dette kræver mindst 4 GB ram på dit system, eller du kan have en CDH-maskine i dit penedrev og bruge den.
Under alle omstændigheder kan du altid have en løsning på dit spørgsmål, måske før end senere.
Forudsætninger for at installere Hive
Der er nogle forudsætninger for at installere hive på enhver maskine:
- Java-installation
- Hadoop installation
Trin 1
- Bekræft, at Java er installeret.
- Åbn terminalen, og skriv kommandoen.
Java-version
- Hvis java er installeret på systemet, giver det dig versionen ellers en fejl. I mit tilfælde er Java allerede installeret, og nedenfor er output af kommandoen.

- I tilfælde af at Java ikke er installeret i dit system. Du kan besøge nedenstående link og downloade java og installere det.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Java-installation
- Uddrag det downloadede.
- Flyt den til “/ usr / local /”.
- Indstil variabler til PATH og JAVA_HOME.
Trin 2
- Bekræft, at Hadoop er installeret.
- Åbn terminalen, og skriv kommandoen.
Hadoop-version
- Hvis Hadoop allerede er installeret, giver denne kommando dig versionen ellers en fejl.
- I mit tilfælde har Hadoop allerede installeret og dermed den nedenstående output.
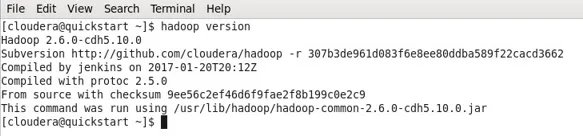
- Du kan nu se, at jeg arbejder med en CDH5-maskine.
- Hvis Hadoop ikke er installeret, skal du downloade Hadoop fra Apache-software foundation.
Hadoop installation
1. Opsætning Hadoop
2. Konfigurer Hadoop
Filer, der kræves redigeret for at konfigurere Hadoop, er:
- kerne-site.xml
- HDFS-site.xml
- garn-site.xml
- mapred-site.xml
3. Indstil Namenode ved hjælp af kommandoen:
Hdfs namenode -format
4. Start dfs ved hjælp af følgende kommando:
start -dfs.sh
5. Start garn ved hjælp af kommandoen:
Start -yarn.sh
Sådan installeres Hive?
Under punkterne hjælper du med at installere bikub:
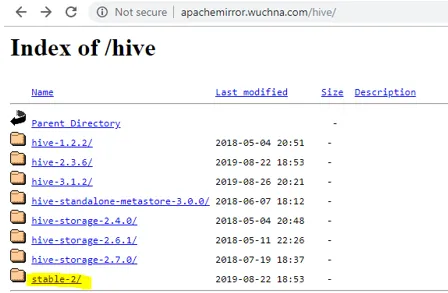
- Den første ting, vi skal gøre, er at downloade bikiveudgivelsen, som kan udføres ved at klikke på linket nedenfor: http://apachemirror.wuchna.com/hive/
- Over linket giver det link, hvorfra du skal vælge stabil-2 fremhævet nedenfor med gult:
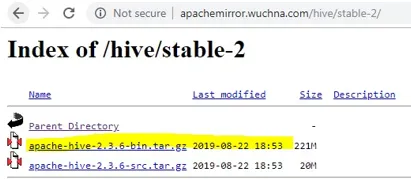
- Efter åbning af stable-2 skal du vælge papirkurefilen (fremhævet gult på skærmbilledet) og højreklikke og “kopiere linkadresse”.
Trin til installation af Hive
Nedenfor er trinnene til installation af hive:
Trin 1: Download tarefilen.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Trin 2: Udpak filen.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Trin 3: Flyt apache-filer til / usr / local / hive-bibliotek.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Trin 4: Indstil Hive-miljøet ved at tilføje følgende linjer til ~ / .bashrc-filen
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Trin 5: Udfør bashrc-filen.
$ source ~/.bashrc
Trin 6: Hive Configuration- Rediger hive-env.sh-filen for at tilføje denne:
export HADOOP_HOME=/usr/local/Hadoop
Trin 7: Rediger ved hjælp af nedenstående kommandoer:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- For at bekræfte, at bikuben er installeret eller ej, skal du bruge kommandohive-versionen.
- Her kommer hive-version ind i bikubskallen, hvilket betyder, at bikuben er installeret. Men i mit tilfælde er det den ældre version, der giver advarslen.

Konklusion - Hive installation
Hive åbner store data for mange mennesker på grund af dets lethed og lighed med SQL som forespørgselssprog og grænseflader. Hive er bygget på Hadoop-kernen, da den bruger Mapreduce til udførelse. Meget let at hente dataene og udføre behandling af Big Data.
Anbefalede artikler
Dette er en guide til Hive-installation. Her diskuterer vi nogle forudsætninger for at installere hive på enhver maskine, og hvordan man installerer hive i trin for bedre forståelse. Du kan også gennemgå vores andre relaterede artikler for at lære mere-
- Hvad er en bikube?
- Hive-kommandoer
- Sådan installeres Hive
- Hvad er gris?