

Introduktion til Hadoop Architecture
Hadoop Architecture er en open source ramme, der hjælper med let at behandle store datasæt. Det hjælper med at oprette applikationer, der behandler enorme data med mere hastighed. Den gør brug af de distribuerede computerkoncepter, hvor data spredes over forskellige knudepunkter i en klynge. De applikationer, der er bygget ved hjælp af Hadoop gør brug af råvarecomputere. Disse computere er let tilgængelige på markedet til billige priser. Dette resultat opnår større computerkraft til en lav pris. Alle data, der findes i Hadoop, ligger på HDFS i stedet for et lokalt filsystem. HDFS er et Hadoop distribueret filsystem. Denne model er baseret på datalokalitet, hvor beregningslogikken sendes til de noder, der findes i en klynge, der indeholder dataene. Denne logik er intet andet end en logik, der kompilerer programmet.
Hadoop Arkitektur
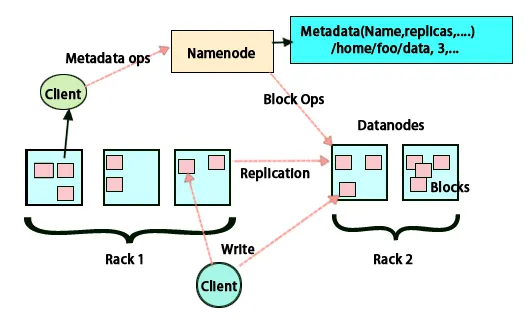
Den grundlæggende idé med denne arkitektur er, at hele lagring og behandling foregår på to trin og på to måder. Det første trin er behandling, der udføres ved hjælp af Map reducering-programmering, og det andet-vejs trin er at lagre de data, der udføres på HDFS. Det har en master-slave-arkitektur til opbevaring og databehandling. Hovednoden til datalagring i Hadoop er navnetoden. Der er også en masternode, der udfører arbejdet med at overvåge og parallelle databehandling ved at bruge Hadoop Map Reduce. Slaverne er andre maskiner i Hadoop-klyngen, som hjælper med at lagre data og også udføre komplekse beregninger. Hver slaveknude er tildelt en task tracker, og en dataknudepunkt har en job tracker, som hjælper med at køre processerne og synkronisere dem effektivt. Denne type system kan indstilles enten på sky eller på stedet. Navneknudepunktet er et enkelt mislykkelsespunkt, når det ikke kører i tilstand med høj tilgængelighed. Hadoop-arkitekturen har også mulighed for at opretholde en stand by Name-knude for at beskytte systemet mod fejl. Tidligere var der sekundære navneknudepunkter, der fungerede som en sikkerhedskopi, når den primære navneknudepunkt var nede.
FSimage og rediger log
FSimage og redigeringslog sikrer vedholdenhed af filsystemmetadata for at følge med al information og navneknap gemmer metadataene i to filer. Disse filer er FSimage og redigeringsloggen. FSimages job er at bevare et komplet snapshot af filsystemet på et givet tidspunkt. De ændringer, der konstant foretages i et system, skal holdes oversigt over. Disse trinvise ændringer som omdøbning eller tilføjelse af detaljer til filen gemmes i redigeringsloggen. Rammen giver en bedre mulighed for snarere end at oprette en ny FSimage hver gang, en bedre mulighed for at kunne gemme dataene, mens en ny fil til FSimage. FSimage opretter et nyt snapshot, hver gang der foretages ændringer, hvis Navneknudepunkt mislykkes, kan det gendanne sin tidligere tilstand. Den sekundære navenode kan også opdatere dens kopi, når der er ændringer i FSimage og redigere logfiler. Således sikrer det, at selvom navneknuden er nede, vil der i nærvær af sekundær navneknap ikke være noget tab af data. Navneknudepunkt kræver ikke, at disse billeder skal genindlæses på den sekundære navneknudepunkt.
Datareplikering
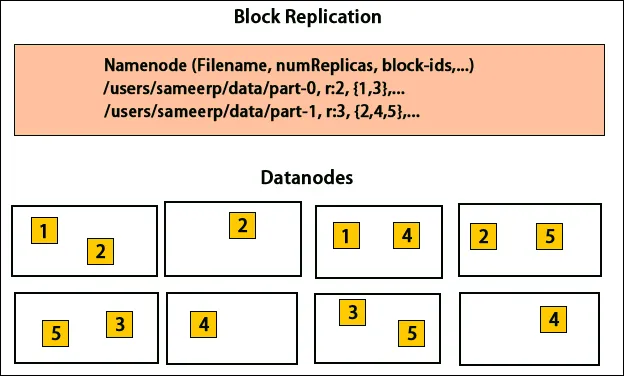
HDFS er designet til at behandle data hurtigt og levere pålidelige data. Det gemmer data på tværs af maskiner og i store klynger. Alle filer gemmes i en række blokke. Disse blokke replikeres for fejltolerance. Blokstørrelsen og replikationsfaktoren kan afgøres af brugerne og konfigureres i henhold til brugerens krav. Som standard er replikationsfaktoren 3. Replikeringsfaktoren kan specificeres på tidspunktet for filoprettelsen, og den kan ændres senere. Alle beslutninger vedrørende disse kopier træffes med navnet knudepunkt. Navneknuten sender fortsat hjerteslag og blokeringsrapport med regelmæssige intervaller for alle dataknudepunkter i klyngen. Modtagelse af hjerteslag indebærer, at dataknuden fungerer korrekt. Blokrapport specificerer listen over alle blokke, der findes på dataknuden.
Placering af kopier
Placering af kopier er en meget vigtig opgave i Hadoop for pålidelighed og ydeevne. Alle de forskellige datablokke placeres på forskellige stativer. Implementeringen af replikplacering kan udføres pr. Pålidelighed, tilgængelighed og anvendelse af netværksbåndbredde. Computerklyngen kan spredes over forskellige stativer. Der kan ikke placeres mere end to noder på samme rack. Den tredje kopi bør placeres på et andet rack for at sikre mere pålidelighed af data. De to knudepunkter på stativet kommunikerer gennem forskellige kontakter. Navneknudepunktet har rack-id for hver dataknudepunkt. Men at placere alle noder på forskellige stativer forhindrer tab af data og tillader brug af båndbredde fra flere stativer. Det skærer også inter-rack-trafikken og forbedrer ydelsen. Risikoen for rackfejl er også meget mindre sammenlignet med knudepunktfejl. Det reducerer den samlede netværksbåndbredde, når data læses fra to unikke stativer i stedet for tre.
Kort reducere
Map Reduce bruges til behandling af data, der er gemt på HDFS. Det skriver distribuerede data på tværs af distribuerede applikationer, som sikrer effektiv behandling af store datamængder. De behandler på store klynger og kræver vare, der er pålidelig og fejlagtolerant. Kernen i Map-reducering kan være tre operationer som kortlægning, samling af par og blanding af de resulterende data.
Konklusion - Hadoop Architecture
Hadoop er en open source-ramme, der hjælper med et fejltolerant system. Det kan gemme store mængder data og hjælper med at lagre pålidelige data. De to dele til lagring af data i HDFS og behandling af dem gennem kortreducerende hjælp til at arbejde korrekt og effektivt. Det har en arkitektur, der hjælper med at styre alle blokke af data og også have den seneste kopi ved at gemme dem i FSimage og redigere logfiler. Replikeringsfaktoren hjælper også med at have kopier af data og få dem tilbage, når der er en fejl. HDFS flytter også fjernede filer til papirkurven for optimal brug af plads.
Anbefalede artikler
Dette har været en guide til Hadoop Architecture. Her har vi drøftet Arkitektur, Kortreducering, Placering af replikaer, Datareplikering. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Bliv en Hadoop-udvikler
- Introduktion til Android
- Hvad er Tableau? | Et overblik
- Hvad er MapReduce i Hadoop?