

Introduktion til svinekommandoer
Apache Pig et værktøj / platform, der bruges til at analysere store datasæt og udføre lange serier af datafunktioner. Gris bruges sammen med Hadoop. Alle svineskripter internt konverteres til kortreducerende opgaver og udføres derefter. Det kan håndtere strukturerede, semistrukturerede og ustrukturerede data. Svin lagrer sit resultat i HDFS. I denne artikel lærer vi de flere typer svinekommandoer.
Her er nogle karakteristika ved svin:
- Selvoptimering: Gris kan optimere udførelsesopgaver, brugeren har friheden til at fokusere på semantik.
- Nem at programmere: Gris giver sprog / dialekt på højt niveau, der kaldes Pig Latin, som er let at skrive. Pig Latin leverer mange operatører, som programmerer kan bruge til at behandle dataene. Programmereren har også fleksibiliteten til at skrive deres egne funktioner.
- Udvidelig: Gris letter oprettelsen af brugerdefineret funktion, der kaldes UDF'er (Brugerdefinerede funktioner), der gør programmerere i stand til at opnå ethvert behandlingsbehov hurtigt og nemt. Grismanuskript kører på en skal kaldet gryntet.
Hvorfor svinekommandoer?
Programmerere, der ikke har det godt med Java, kæmper normalt med at skrive programmer i Hadoop, dvs. at skrive kortreducerende opgaver. For dem er svine-latin, der ligner SQL-sprog, en velsignelse. Dens multi-forespørgsel tilgang reducerer længden af koden.
Så alt i alt sin kortfattede og effektive måde at programmere på. Svinekommandoer kan påkalde kode på mange sprog som JRuby, Jython og Java.
Arkitekturen af svinekommandoer
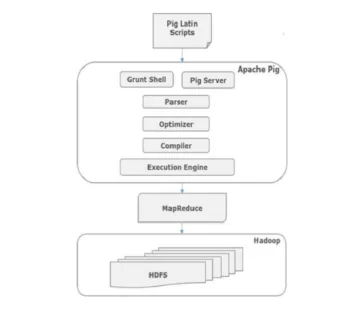
Alle scripts skrevet i svin-latin over grynt skal går til parseren for at kontrollere syntaks og andre diverse kontroller sker også. Udgangssignalet fra parseren er en DAG. Denne DAG overføres derefter til Optimizer, der derefter udfører logisk optimering såsom projektion og skubber ned. Derefter overholder kompilatoren den logiske plan til MapReduce-job. Endelig indsendes disse MapReduce-job til Hadoop i sorteret rækkefølge. Disse job udføres og giver de ønskede resultater.
Svin-latin datamodel er fuldt indlejret, og den tillader komplekse datatyper som kort og tuple.
Enhver enkelt værdi af Latin-sprog (uanset datatype) kaldes Atom.
Grundlæggende svinekommandoer
Lad os se på nogle af de grundlæggende svin-kommandoer, der er givet nedenfor: -
1. Fs: Dette viser alle filerne i HDFS
grynt> fs –ls
2. Ryd: Dette rydder det interaktive Grunt-shell.
grynt> klart
3. Historie:
Denne kommando viser de kommandoer, der er udført indtil videre.
grynt> historie
4. Læse data: Forudsat at dataene ligger i HDFS, og vi er nødt til at læse data til Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
BRUGER PigStorage (', ')
som (id: int, fornavn: chararray, efternavn: chararray, telefon: chararray,
by: chararray);
PigStorage () er den funktion, der indlæser og gemmer data som strukturerede tekstfiler.
5. Lagring af data: Store operatør bruges til at gemme de behandlede / indlæste data.
grynt> BUTIK college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Her er “/ pig_Output /” det bibliotek, hvor relation skal gemmes.
6. Dump Operator: Denne kommando bruges til at vise resultaterne på skærmen. Det hjælper normalt med debugging.
grynt> Dump college_studenter;
7. Beskriv operatør: Det hjælper programmereren med at se skemaet for relationen.
grynt> beskriv college_studenter;
8. Forklar: Denne kommando hjælper med at gennemgå de logiske, fysiske og kortreducerende eksekveringsplaner.
grynt> forklar college_studenter;
9. Illustrer operatøren: Dette giver trinvis udførelse af udsagn i svinekommandoer.
grynt> illustrer college_studenter;
Mellemliggende svinekommandoer
1. Gruppe: Denne svin-kommando fungerer mod gruppering af data med den samme nøgle.
grunt> group_data = GROUP college_studenter ved fornavn;
2. COGROUP: Det fungerer på samme måde som gruppeoperatøren. Den største forskel mellem Group & Cogroup-operatøren er den gruppeoperatør, der normalt bruges med en relation, mens cogroup bruges med mere end en relation.
3. Deltag: Dette bruges til at kombinere to eller flere relationer.
Eksempel: For at udføre selvforbindelse, lad os sige, at relation “kunde” indlæses fra HDFS tp svinekommandoer i to relationskunder1 & kunder2.
grynt> kunder3 = BLING MED kunder1 BY id, kunder2 BY id;
Deltag kunne være selvforbindelse, indvendig sammenføjning, ydre tilslutning.
4. Kors: Denne svinekommando beregner krydsproduktet af to eller flere relationer.
grynt> cross_data = CROSS kunder, ordrer;
5. Union: Det fusionerer to forbindelser. Betingelsen for fusion er, at både relationens kolonner og domæner skal være identiske.
grynt> studerende = UNION-studerende1, studerende2;
Avancerede svinekommandoer
Lad os se på nogle af de avancerede svin-kommandoer, der er givet nedenfor:
1. Filter: Dette hjælper med at filtrere tuplerne ud af forhold, baseret på visse betingelser.
filter_data = FILTER college_students BY city == 'Chennai';
2. Distinct: Dette hjælper med at fjerne overflødige tuples fra forholdet.
grynt> distinkt data = DISTINCT college_studenter;
Denne filtrering vil skabe nyt relation navn "distinkte data"
3. Foreach: Dette hjælper med at generere datatransformation baseret på kolonnedata.
grynt> foreach_data = FOREACH student_detaljer GENERATE id, alder, by;
Dette vil få hver elevs id, alder og byværdier fra forholdet student_detaljer og vil derfor gemme det i en anden relation med navnet foreach_data.
4. Bestil efter: Denne kommando viser resultatet i en sorteret rækkefølge baseret på et eller flere felter.
grunt> order_by_data = BESTIL college_studenter efter aldersbeskrivelse;
Dette vil sortere forholdet "college_studenter" i faldende rækkefølge efter alder.
5. Begrænsning: Denne kommando bliver begrænset nr. af tupler fra relationen.
grynt> limit_data = LIMIT student_detaljer 4;
Tips og tricks
Nedenfor er de forskellige tip og tricks i svinekommandoer: -
1. Aktivér komprimering på dit input og output:
sæt input.compression.enabled sand;
sæt output.compression.enabled sand;
Ovenfor nævnte kodelinjer skal være i begyndelsen af scriptet, så det gør det muligt for svinekommandoer at læse komprimerede filer eller generere komprimerede filer som output.
2. Deltag i flere relationer:
For at udføre venstre sammenføjning på sige tre relationer (input1, input2, input3), skal man vælge SQL. Det skyldes, at ydre sammenføjning ikke understøttes af gris på mere end to borde.
Snarere udfører du venstre for at deltage i to trin som:
data1 = JOIN input1 BY tast VENSTRE, input2 BY key;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Dette betyder to kortreducerende job.
For at udføre ovennævnte opgave mere effektivt kan man vælge “Cogroup”. Cogroup kan deltage i flere relationer. Cogroup er som standard ekstern sammenføjning.
Konklusion
Gris er et proceduresprog, der generelt bruges af dataforskere til at udføre ad-hoc-behandling og hurtig prototype. Det er et fantastisk ETL og store databehandlingsværktøj. Svine-scripts kan påberåbes af andre sprog og vice versa. Derfor kan svinekommandoer bruges til at bygge større og komplekse applikationer.
Anbefalede artikler
Dette har været en guide til svinekommandoer. Her har vi drøftet grundlæggende såvel som avancerede svinekommandoer og nogle øjeblikkelige svinekommandoer. Du kan også se på den følgende artikel for at lære mere -
- Adobe Photoshop-kommandoer
- Tableau-kommandoer
- Snyd ark SQL (kommandoer, gratis tip og tricks)
- VBA-kommandoer - efterbehandling
- Forskellige operationer relateret til tuples