

Hvad er Naive Bayes algoritme?
Naive Bayes algoritme er en teknik, der hjælper med at konstruere klassificeringsmaskiner. Klassificeringsmaskiner er de modeller, der klassificerer problemtilfældene og giver dem klassetiketter, der er repræsenteret som vektorer af forudsigere eller funktionsværdier. Det er baseret på Bayes sætning. Det kaldes naive Bayes, fordi det antager, at værdien af en funktion er uafhængig af den anden funktion, dvs. ændring af værdien af en funktion ville ikke påvirke værdien af den anden funktion. Det kaldes også som idiot Bayes af samme grund. Denne algoritme fungerer effektivt til store datasæt, og dermed bedst egnet til realtidsprognoser.
Det hjælper med at beregne den bagerste sandsynlighed P (c | x) ved hjælp af den forudgående sandsynlighed for klasse P (c), den forudgående sandsynlighed for forudsigelse P (x) og sandsynligheden for forudsigelse givet klasse, også kaldet som sandsynlighed P (x | c ).
Formlen eller ligningen til beregning af posterior sandsynlighed er:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Hvordan Naive Bayes algoritme fungerer?
Lad os forstå funktionen af Naive Bayes algoritme ved hjælp af et eksempel. Vi antager et træningsdatasæt for vejr og målvariablen 'At gå på shopping'. Nu klassificerer vi, om en pige går på indkøb baseret på vejrforhold.
Det givne datasæt er:
| Vejr | Går ud og handler |
| Solrig | Ingen |
| Regnfuld | Ja |
| Overskyet | Ja |
| Solrig | Ja |
| Overskyet | Ja |
| Regnfuld | Ingen |
| Solrig | Ja |
| Solrig | Ja |
| Regnfuld | Ingen |
| Regnfuld | Ja |
| Overskyet | Ja |
| Regnfuld | Ingen |
| Overskyet | Ja |
| Solrig | Ingen |
Følgende trin udføres:
Trin 1: Lav frekvensborde ved hjælp af datasæt.
| Vejr | Ja | Ingen |
| Solrig | 3 | 2 |
| Overskyet | 4 | 0 |
| Regnfuld | 2 | 3 |
| Total | 9 | 5 |
Trin 2: Lav en sandsynlighedstabel ved at beregne sandsynligheden for hver vejrforhold og gå på indkøb.
| Vejr | Ja | Ingen | Sandsynlighed |
| Solrig | 3 | 2 | 5/14 = 0, 36 |
| Overskyet | 4 | 0 | 4/14 = 0, 29 |
| Regnfuld | 2 | 3 | 5/14 = 0, 36 |
| Total | 9 | 5 | |
| Sandsynlighed | 9/14 = 0, 64 | 5/14 = 0, 36 |
Trin 3: Nu skal vi beregne den bagerste sandsynlighed ved hjælp af Naive Bayes ligning for hver klasse.
Probleminstans: En pige går på shopping, hvis vejret er overskyet. Er denne erklæring korrekt?
Løsning:
- P (Ja | Overskyet) = (P (Overskyet | Ja) * P (Ja)) / P (Overskyet)
- P (overskyet | Ja) = 4/9 = 0, 44
- P (Ja) = 9/14 = 0, 64
- P (overskyet) = 4/14 = 0, 39
Læg nu alle de beregnede værdier i ovenstående formel
- P (Ja | Overskyet) = (0, 44 * 0, 64) / 0, 39
- P (Ja | Overskyet) = 0, 722
Den klasse, der har størst sandsynlighed, ville være resultatet af forudsigelsen. Ved anvendelse af samme tilgang kan der forudsiges sandsynligheder for forskellige klasser.
Hvad bruges Naive Bayes algoritme til?
1. Realtidsprognose: Naive Bayes algoritme er hurtig og altid klar til at lære, og dermed bedst egnet til realtidsprognoser.
2. Multiklasse-forudsigelse: Sandsynligheden for multiklasser for en hvilken som helst målvariabel kan forudsiges ved hjælp af en Naive Bayes-algoritme.
3. Anbefalingssystem: Naive Bayes-klassifikator ved hjælp af Collaborative Filtering bygger et anbefalingssystem. Dette system bruger dataindvinding og maskinindlæringsteknikker til at filtrere de oplysninger, der ikke er set før, og derefter forudsige, om en bruger vil sætte pris på en given ressource eller ej.
4. Tekstklassificering / sentimentanalyse / spamfiltrering: På grund af dens bedre ydeevne med flerklasseproblemer og dens uafhængighedsregel klarer Naive Bayes algoritme bedre eller har en højere succesrate i tekstklassificering, derfor bruges den i sentimentanalyse og Spamfiltrering.
Fordele ved Naive Bayes algoritme
- Let at implementere.
- Hurtig
- Hvis antagelsen om uafhængighed gælder, fungerer den mere effektivt end andre algoritmer.
- Det kræver mindre træningsdata.
- Det er meget skalerbart.
- Det kan give sandsynlige forudsigelser.
- Kan håndtere både kontinuerlige og diskrete data.
- Ufølsom over for irrelevante funktioner.
- Det kan arbejde let med manglende værdier.
- Let at opdatere ved ankomsten af nye data.
- Bedst egnet til tekstklassificeringsproblemer.
Ulemper ved Naive Bayes algoritme
- Den stærke antagelse om, at funktionerne skal være uafhængige, hvilket næppe er sandt i applikationer i det virkelige liv.
- Dataknapphed.
- Chancerne for tab af nøjagtighed.
- Nulfrekvens, dvs. hvis kategorien af en kategorisk variabel ikke ses i træningsdatasæt, tildeler model en nul-sandsynlighed til den kategori, og derefter kan en forudsigelse ikke foretages.
Sådan bygger du en grundlæggende model ved hjælp af Naive Bayes algoritme
Der er tre typer Naive Bayes-modeller, dvs. Gaussian, Multinomial og Bernoulli. Lad os diskutere hver enkelt af dem kort.
1. Gaussian: Gaussian Naive Bayes algoritme antager, at de kontinuerlige værdier, der svarer til hver funktion, er fordelt i henhold til Gaussisk distribution, også kaldet Normal distribution.
Sandsynligheden eller forudgående sandsynlighed for forudsigelse af den givne klasse antages at være gaussisk, derfor kan betinget sandsynlighed beregnes som:
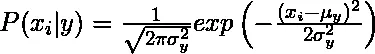
2. Multinomial: Frekvenserne for forekomsten af visse begivenheder repræsenteret af funktionsvektorer genereres ved hjælp af multinomial distribution. Denne model er vidt brugt til dokumentklassificering.
3. Bernoulli: I denne model er inputene beskrevet af funktionerne, der er uafhængige binære variabler eller Booleans. Dette er også meget brugt i dokumentklassifikation som Multinomial Naive Bayes.
Du kan bruge en hvilken som helst af de ovennævnte modeller, som det kræves til at håndtere og klassificere datasættet.
Du kan opbygge en gaussisk model ved hjælp af Python ved at forstå nedenstående eksempel:
Kode:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Produktion:
((3, 4))
Konklusion
I denne artikel lærte vi detaljerne om begreberne Naive Bayes algoritme. Det bruges mest i tekstklassificering. Det er let at implementere og hurtigt at udføre. Dens største ulempe er, at det kræver, at funktionerne skal være uafhængige, hvilket ikke er tilfældet i applikationer i det virkelige liv.
Anbefalede artikler
Dette har været en guide til Naive Bayes algoritme. Her drøftede vi det grundlæggende koncept, arbejde, fordele og ulemper ved den Naive Bayes algoritme. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Boosting Algoritme
- Algoritme i programmering
- Introduktion til algoritme