
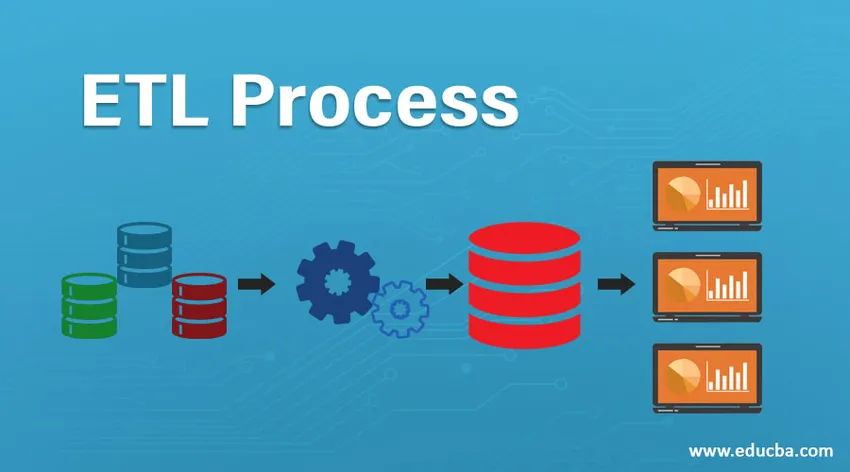
Introduktion af ETL-processen
ETL er en af de vigtige processer, der kræves af Business Intelligence. Business Intelligence er afhængig af de data, der er gemt i datalager, hvorfra mange analyser og rapporter genereres, hvilket hjælper med at opbygge mere effektive strategier og fører til taktiske og operationelle indsigter og beslutningstagning.
ETL henviser til Extract, Transform og Load processen. Det er et slags dataintegrationstrin, hvor data, der kommer fra forskellige kilder, udvindes og sendes til datalager. Data udvindes fra forskellige ressourcer, der først transformeres for at konvertere dem til et specifikt format i henhold til forretningskrav. Forskellige værktøjer, der hjælper med at udføre disse opgaver er -
- IBM DataStage
- Abinitio
- Informatica
- Tableau
- Talend
ETL-proces
Hvordan virker det?
ETL-processen er en 3-trins proces, der starter med at udtrække data fra forskellige datakilder og derefter gennemgå rådata forskellige transformationer for at gøre dem egnede til opbevaring i datavarehus og indlæse dem i datavarehaller i det krævede format og gøre dem klar til analyse.
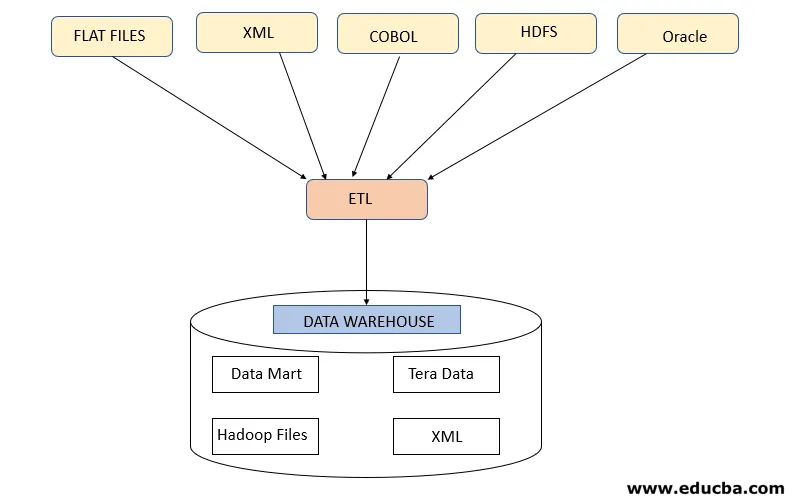
Trin 1: Uddrag
Dette trin henviser til hentning af de krævede data fra forskellige kilder, der er til stede i forskellige formater, såsom XML, Hadoop-filer, flade filer, JSON osv. De ekstraherede data gemmes i det mellemliggende område, hvor yderligere transformationer udføres. Således kontrolleres data grundigt, før de flyttes til datalager, ellers vil det blive en udfordring at vende ændringerne i datalager.
Der kræves et ordentligt datakort mellem kilde og mål, før dataekstraktion finder sted, da ETL-processen har brug for at interagere med forskellige systemer som Oracle, hardware, mainframe, realtidssystemer som ATM, Hadoop osv., Mens data hentes fra disse systemer .
Bemærk - Men man skal passe på, at disse systemer skal forblive upåvirket under ekstraktion.
Dataekstraktionsstrategier
- Fuld udtrækning: Dette følges, når hele data fra kilder indlæses i datavarehuse, der viser, at enten datavarehus befolkes første gang, eller der ikke er udarbejdet nogen strategi for dataekstraktion.
- Delvis udvinding (med opdateringsmeddelelse): Denne strategi er også kendt delta, hvor kun de data, der ændres, udvindes og opdaterer datalager
- Delvis udvinding (uden opdateringsmeddelelse): Denne strategi refererer til at udtrække specifikke krævede data fra kilder i henhold til belastning i datalagerne i stedet for at udtrække hele data.
Trin 2: Transform
Dette trin er det vigtigste trin i ETL. I dette trin udføres mange transformationer for at gøre data klar til indlæsning i datalager ved anvendelse af nedenstående transformationer: -
A. Grundlæggende transformationer: Disse transformationer anvendes i alle scenarier, da de er et grundlæggende behov, mens de data, der er ekstraheret fra forskellige kilder, indlæses i datalagrene
- Rengøring af data eller berigelse: Det henviser til rengøring af uønskede data fra iscenesættelsesområdet, så forkerte data ikke indlæses fra datalagrene.
- Filtrering: Her filtrerer vi de krævede data ud af en stor mængde data til stede i henhold til forretningskrav. For f.eks. At generere salgsrapporter behøver man kun salgsrekorder for det pågældende år.
- Konsolidering: De ekstraherede data konsolideres i det krævede format, inden de indlæses i datalagrene.4.
- Standardiseringer: Datafelter transformeres for at bringe det i det samme krævede format for f.eks. Datafeltet skal specificeres som MM / DD / ÅÅÅÅ.
B. Avancerede transformationer: Disse typer transformationer er specifikke for forretningskravene.
- Forbindelse: I denne operation kombineres data fra 2 eller flere kilder t genererer data med kun ønskede kolonner med rækker, der er relateret til hinanden
- Datatærskelvalideringskontrol: Værdier, der findes i forskellige felter, kontrolleres, om de er korrekte eller ikke, f.eks. Ikke nul bankkontonummer i tilfælde af bankdata.
- Brug opslag til at flette data: Forskellige flade filer eller andre filer bruges til at udtrække de specifikke oplysninger ved at udføre opslag på dette.
- Brug af en hvilken som helst kompleks datavalidering: Mange komplekse valideringer anvendes til kun at udtrække gyldige data fra kildesystemerne.
- Beregnede og afledte værdier: Forskellige beregninger anvendes til at omdanne dataene til nogle krævede oplysninger
- Duplikation: Duplicerede data, der kommer fra kildesystemerne, analyseres og fjernes, inden de indlæses i datalagrene.
- Nøgleomstrukturering: I tilfælde af indsamling af langsomt skiftende data skal forskellige surrogatnøgler genereres for at strukturere dataene i det krævede format.
Bemærk - MPP-massiv parallelbehandling bruges undertiden til at udføre nogle grundlæggende handlinger, såsom filtrering eller rensning af data i iscenesættelsesområdet for at behandle en stor mængde data hurtigere.
Trin 3: Indlæs
Dette trin henviser til indlæsning af de transformerede data i datalageret, hvorfra de kan bruges til at generere mange analytiske beslutninger såvel som rapportering.
1. Indledende indlæsning: Denne type belastning opstår, mens data indlæses i datavarehaller for første gang.
2. Trinvis belastning: Dette er den type belastning, der udføres for at opdatere datalageret med jævne mellemrum med ændringer, der forekommer i kildesystemdata.
3. Fuld opdatering: Denne type belastning henviser til situationen, når komplette data i tabellen slettes og indlæses med friske data.
Datalageret tillader derefter OLAP- eller OLTP-funktioner.
Ulemper ved ETL-processen
- Forøgelse af data - Der er en grænse for data, der udvindes fra forskellige kilder ved hjælp af ETL-værktøjet og skubbes til datavarehaller. Med stigningen i data bliver det således besværligt at arbejde med ETL-værktøjet og datalager.
- Tilpasning - Dette henviser til de hurtige og effektive løsninger eller svar på de data, der genereres af kildesystemer. Men ved hjælp af ETL-værktøjet her bremser denne proces.
- Dyrt - At bruge et datalager til at gemme en stigende mængde data, der genereres med jævne mellemrum, er en høj pris, som en organisation skal betale.
Konklusion - ETL-proces
ETL-værktøjet består af ekstrakt, transformering og indlæsningsprocesser, hvor det hjælper med at generere information fra data indsamlet fra forskellige kildesystemer. Dataene fra kildesystemet kan komme i alle formater og kan indlæses i ethvert ønsket format i datavarehuse, og derfor skal ETL-værktøj understøtte forbindelse til alle typer af disse formater.
Anbefalede artikler
Dette er en guide til en ETL-proces. Her diskuterer vi introduktionen, hvordan fungerer det ?, ETL-værktøjer og dets ulemper. Du kan også gennemgå vores andre foreslåede artikler for at lære mere–
- Informatica ETL-værktøjer
- ETL-testværktøjer
- Hvad er ETL?
- Hvad er ETL-test?