
Hvad er lineær regression i R?
Lineær regression er den mest populære og mest anvendte algoritme inden for statistik og maskinlæring. Lineær regression er en modelleringsteknik til at forstå forholdet mellem input- og outputvariabler. Her skal variabler være numeriske. Lineær regression stammer fra det faktum, at outputvariablen er en lineær kombination af inputvariabler. Outputet er normalt repræsenteret med “y”, mens input er repræsenteret med “x”.
Lineær regression i R kan kategoriseres på to måder
-
Si mple Lineær regression
Dette er regressionen, hvor outputvariablen er en funktion af en enkelt inputvariabel. Repræsentation af enkel lineær regression:
y = c0 + c1 * x1
-
Multipel lineær regression
Dette er regressionen, hvor outputvariablen er en funktion af en variabel med flere input.
y = c0 + c1 * x1 + c2 * x2
I begge ovennævnte tilfælde er c0, c1, c2 koefficienten, der repræsenterer regressionsvægte.
Lineær regression i R
R er et meget kraftfuldt statistisk værktøj. Så lad os se, hvordan lineær regression kan udføres i R, og hvordan dens outputværdier kan fortolkes.
Lad os forberede et datasæt til at udføre og forstå lineær regression dybtgående nu.
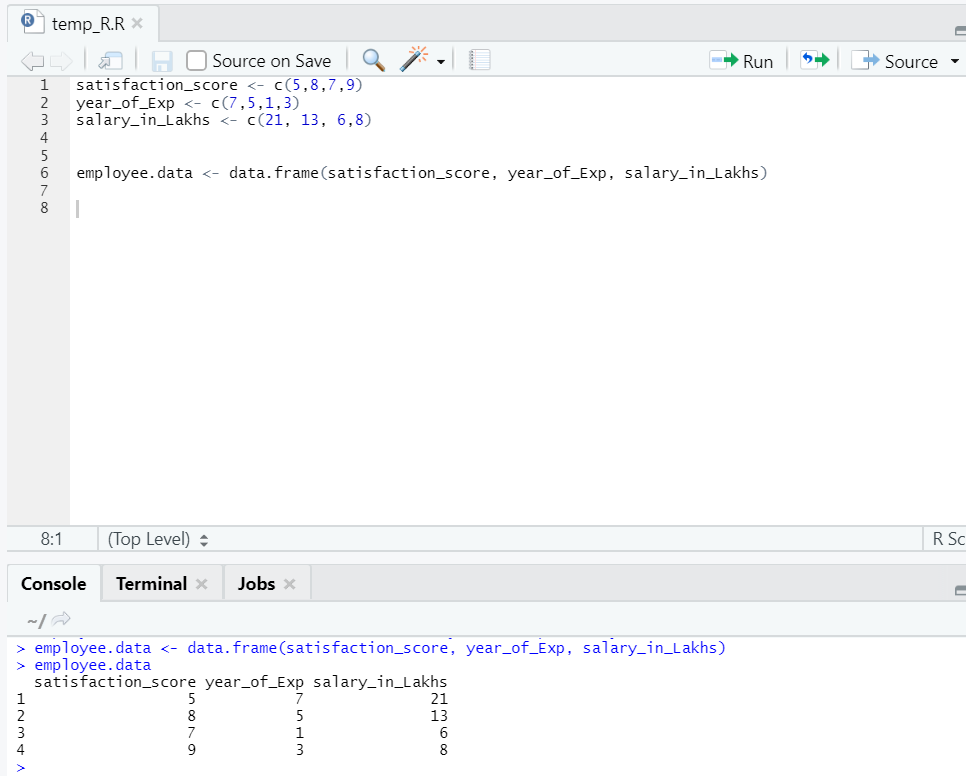
Nu har vi et datasæt, hvor "tilfredshed_score" og "year_of_Exp" er den uafhængige variabel. "Lønn_in_lakhs" er outputvariablen.
Under henvisning til ovennævnte datasæt er problemet, vi ønsker at løse her gennem lineær regression, :
Estimering af en medarbejders løn baseret på hans års erfaring og tilfredshedsresultat i hans virksomhed.
R-kode for lineær regression:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Output fra ovenstående kode vil være:
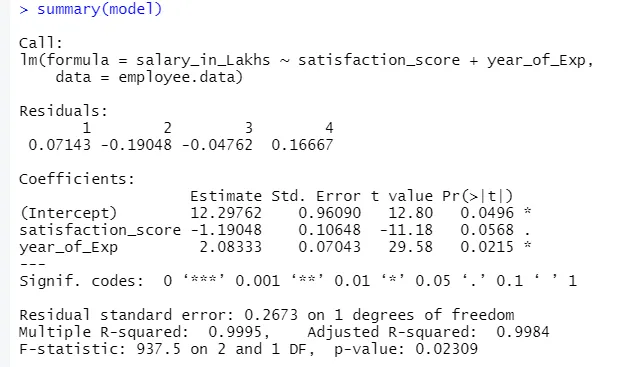
Formel for regression bliver
Y = 12, 29-1, 19 * tilfredshed_score + 2, 08 × 2 * år_of_Exp
I tilfælde af at man har flere input til modellen.
Så kan R-kode være:
model <- lm (lønn_in_Lakhs ~., data = medarbejder.data)
Men hvis nogen ønsker at vælge variabel ud af flere inputvariabler, er der flere teknikker som "Backward Elimination", "Forward Selection" osv. Er tilgængelige for at gøre det også.
Fortolkning af lineær regression i R
Nedenfor er nogle fortolkninger af lineær regression i r, som er som følger:
1.Residuals
Dette henviser til forskellen mellem den faktiske respons og den forudsagte respons fra modellen. Så for hvert punkt vil der være et faktisk svar og et forudsagt svar. Derfor vil rester være så mange som observationer. I vores tilfælde har vi fire observationer, deraf fire rester.

2.Coefficients
Når vi går videre, finder vi koefficientsafsnittet, der viser afskærmningen og hældningen. Hvis man ønsker at forudsige en medarbejders løn baseret på hans erfarings- og tilfredshedsresultat, skal man udvikle en modelformel baseret på hældning og aflytning. Denne formel hjælper dig med at forudsige løn. Afskærmningen og hældningen hjælper en analytiker med at finde frem til den bedste model, der passer til datapunkter passende.
Hældning: Viser linjens stejlhed.
Afskæring: Det sted, hvor linjen skærer aksen.
Lad os forstå, hvordan formeldannelse udføres baseret på hældning og aflytning.
Lad os sige afskærmning er 3 og hældningen er 5.
Så formlen er y = 3 + 5x . Dette betyder, at hvis x øges med en enhed, øges y med 5.
a.Koefficient - estimering
I dette angiver interceptet gennemsnitsværdien af outputvariablen, når al input bliver nul. Så i vores tilfælde er lønnen i lakhs 12, 29Lakhs, da gennemsnittet i betragtning af tilfredshedsscore og erfaring er nul. Her repræsenterer hældningen ændringen i outputvariablen med en enhedsændring i inputvariablen.
b.Koefficient - Standardfejl
Standardfejlen er estimeringen af fejl, som vi kan få, når vi beregner forskellen mellem den faktiske og forudsagte værdi af vores responsvariabel. Dette fortæller igen om tilliden til relaterede input- og outputvariabler.
c.Koefficient - t-værdi
Denne værdi giver tillid til at afvise nulhypotesen. Jo større værdien væk fra nul, desto større er tilliden til at afvise nulhypotesen og etablere forholdet mellem output og inputvariabel. I vores tilfælde er værdien også væk fra nul.
d.Koefficient - Pr (> t)
Dette forkortelse afbilder grundlæggende p-værdien. Jo tættere det er på nul, jo lettere kan vi afvise nulhypotesen. Den linje, vi ser i vores tilfælde, denne værdi er tæt på nul, vi kan sige, at der findes et forhold mellem lønpakke, tilfredshedsresultat og år med oplevelser.

Reststandardfejl
Dette viser fejlen i forudsigelsen af responsvariablen. Jo lavere den er, jo højere er nøjagtigheden af modellen.
Flere R-firkanter, Justeret R-kvadrat
R-kvadrat er et meget vigtigt statistisk mål for at forstå, hvor tæt dataene har passet ind i modellen. Derfor i vores tilfælde, hvor godt vores model, der er lineær regression, repræsenterer datasættet.
R-kvadratværdien ligger altid mellem 0 og 1. Formlen er:

Jo nærmere værdien er 1, jo bedre beskrives modellen datasættene og dens varians.
Når mere end en inputvariabel kommer ind i billedet, foretrækkes den justerede R-kvadratværdi imidlertid.
F-Statistik
Det er et stærkt mål at bestemme forholdet mellem input og responsvariabel. Jo større værdien er end 1, jo højere er tilliden til forholdet mellem input- og outputvariablen.
I vores tilfælde er det “937, 5”, som er relativt større i betragtning af datastørrelsen. Derfor bliver afvisning af nulhypotesen lettere.
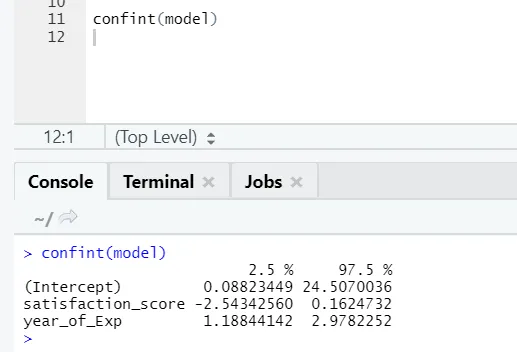
Hvis nogen ønsker at se tillidsintervallet for modellens koefficienter, er her måden at gøre det på: -
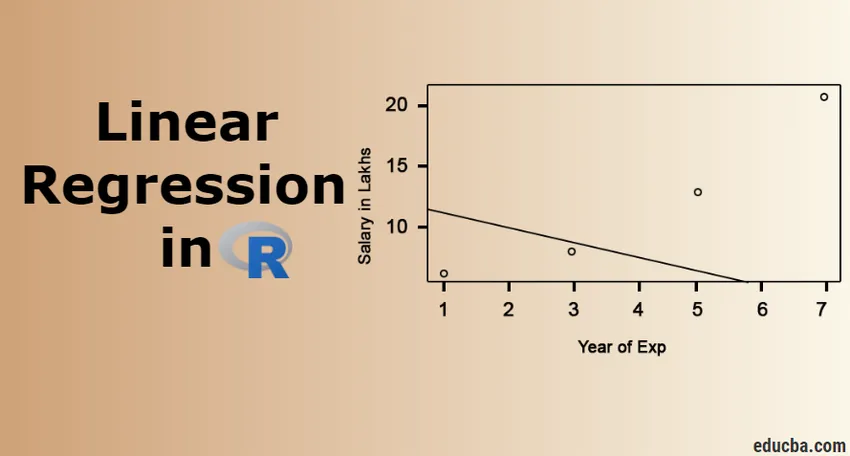
Visualisering af regression
R-kode:
plot (lønn_in_Lakhs ~ tilfredshed_score + år_of_Exp, data = medarbejder.data)
abline (model)
Det er altid bedre at samle flere og flere point, før de passer til en model.
Konklusion - Lineær regression i R
Lineær regression er enkel, let at montere, let at forstå og alligevel meget kraftfuld model. Vi så, hvordan lineær regression kan udføres på R. Vi forsøgte også at tolke resultaterne, hvilket kan hjælpe dig i optimeringen af modellen. Når man først er fortrolig med enkel lineær regression, bør man prøve multiple lineær regression. Sammen med dette, da lineær regression er følsom over for outliers, skal man undersøge den, inden man springer direkte ind i passende til lineær regression.
Anbefalede artikler
Dette er en guide til Lineær regression i R. Her har vi drøftet, hvad der er lineær regression i R? kategorisering, visualisering og fortolkning af R. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Forudsigelig modellering
- Logistisk regression i R
- Beslutningstræ i R
- R Interview spørgsmål
- Topforskelle mellem regression vs klassificering
- Vejledning til beslutningstræ i maskinlæring
- Lineær regression vs logistisk regression | Topforskelle