
Introduktion til Poisson Regression i R
Poisson-regression er en type regression, der ligner multiple lineær regression, bortset fra at responsen eller den afhængige variabel (Y) er en tællervariabel. Den afhængige variabel følger Poisson-fordelingen. Prediktoren eller uafhængige variabler kan være kontinuerlige eller kategoriske. På en måde ligner det logistisk regression, som også har en diskret responsvariabel. Forudgående forståelse af Poisson-distributionen og dens matematiske form er meget vigtig for at udnytte den til forudsigelse. I R kan Poisson-regression implementeres på en meget effektiv måde. R tilbyder et omfattende sæt af funktionaliteter til dets implementering.
Implementering af Poisson-regression
Vi fortsætter nu med at forstå, hvordan modellen anvendes. Følgende afsnit giver en trinvis procedure for det samme. Til denne demonstration overvejer vi "galla" datasættet fra pakken "fjern". Det angår artsdiversiteten på Galapagosøerne. Der er i alt 7 variabler i datasættet. Vi bruger Poisson-regression til at definere et forhold mellem antallet af plantearter (arter) med andre variabler i datasættet.
1. Læg først den "fjerne" pakke. I tilfælde af at pakken ikke er til stede, skal du downloade den ved hjælp af funktionen install.packages ().
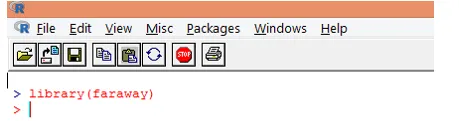
2. Når pakken er indlæst, skal du indlæse "gala" datasættet i R ved hjælp af data () -funktionen som vist nedenfor.
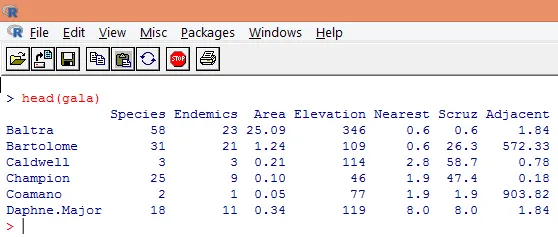
3. De indlæste data skal visualiseres for at studere variablen og kontrollere, om der er nogen uoverensstemmelser. Vi kan visualisere enten hele dataene eller bare de første par rækker med dem ved hjælp af funktionen hoved () som vist på nedenstående skærmbillede.
4. For at få mere indsigt i datasættet kan vi bruge hjælpefunktionalitet i R som nedenfor. Det genererer R-dokumentationen som vist på skærmbilledet efter nedenstående skærmbillede.


5. Hvis vi studerer datasættet som nævnt i de foregående trin, kan vi finde ud af, at arter er en responsvariabel. Vi vil nu studere en grundlæggende oversigt over prediktorvariablerne.
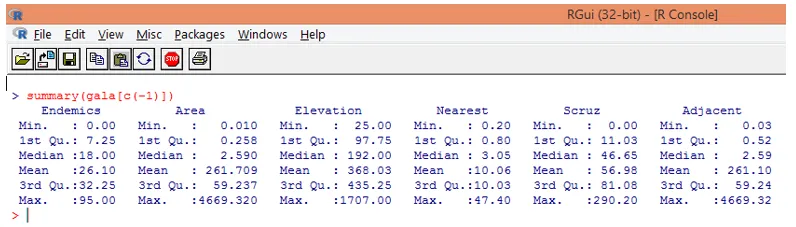
Bemærk, som vi kan se ovenfor, har vi udeladt variablen Arter. Oversigtsfunktionen giver os grundlæggende indsigt. Bare observer medianværdierne for hver af disse variabler, og vi kan konstatere, at der er en enorm forskel, hvad angår værdiområdet, mellem den første halvdel og den anden halvdel, f.eks. For Arealvariabel medianværdi er 2, 59, men den maksimale værdi er 4669.320.
6. Nu hvor vi er færdig med en grundlæggende analyse, genererer vi et histogram for arter for at kontrollere, om variablen følger Poisson-fordelingen. Dette illustreres nedenfor.

Ovenstående kode genererer et histogram for variablen Art sammen med en densitetskurve, der er lagt ovenover.
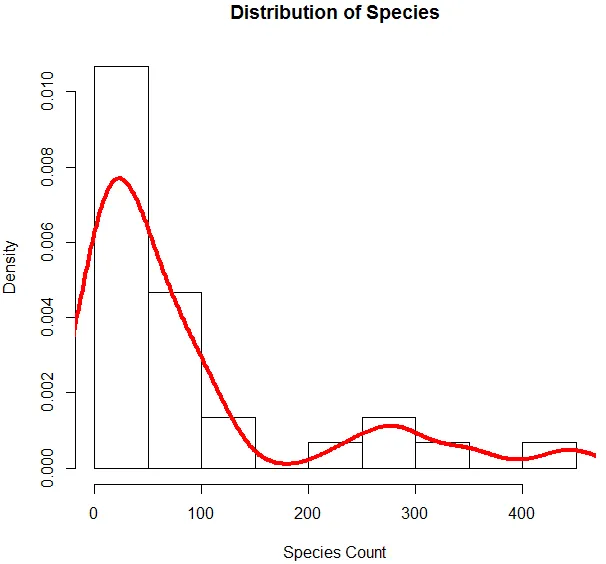
Ovenstående visualisering viser, at arter følger en Poisson-distribution, da dataene er ret skæve. Vi kan også generere en boksplot for at få mere indsigt i fordelingsmønsteret som vist nedenfor.
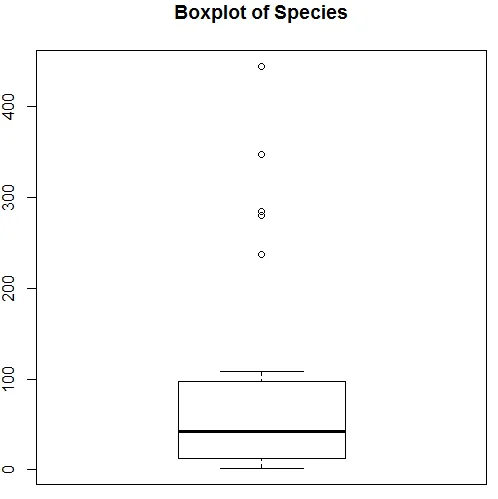
7. Når vi er færdig med den foreløbige analyse, anvender vi nu Poisson-regression som vist nedenfor
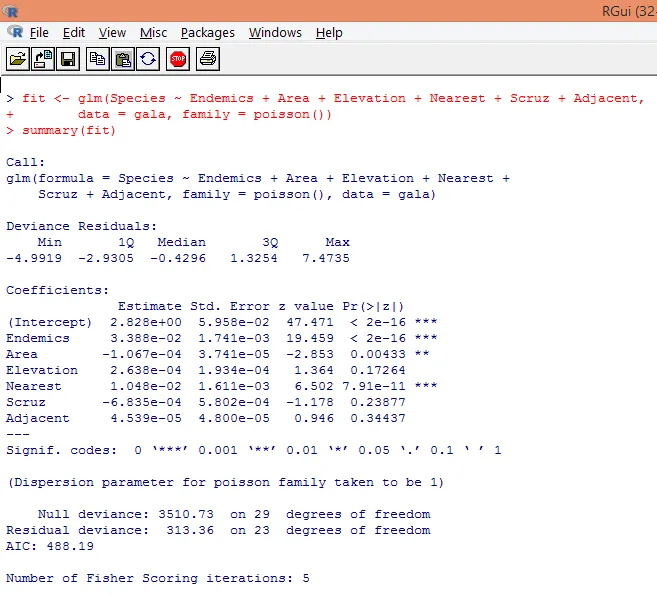
Baseret på ovenstående analyse finder vi, at variabler Endemik, område og nærmeste er signifikante, og at kun deres inkludering er tilstrækkelig til at oprette den rigtige Poisson-regressionsmodel.
8. Vi opbygger en modificeret Poisson-regressionsmodel under hensyntagen til tre variabler, dvs. Endemik, område og nærmeste. Lad os se, hvilke resultater vi får.
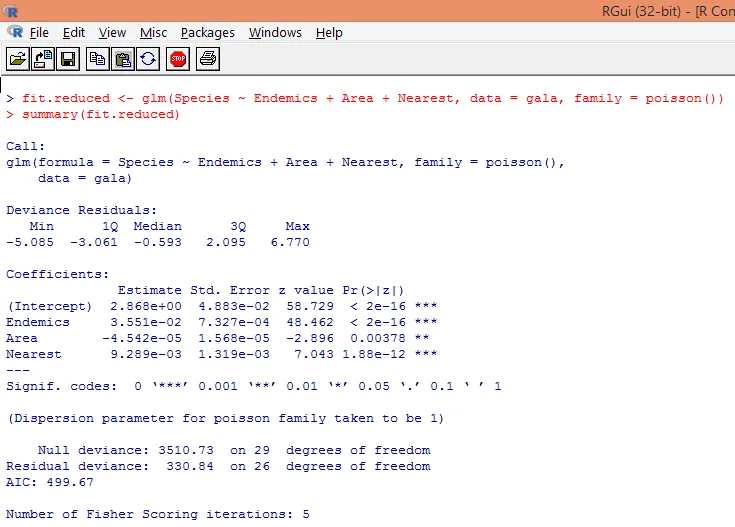
Outputet producerer afvigelser, regressionsparametre og standardfejl. Vi kan se, at hver af parametrene er signifikant på p <0, 05 niveau.
9. Det næste trin er at fortolke modelparametrene. Modelkoefficienterne kan opnås enten ved at undersøge koefficienter i ovenstående output eller ved at bruge coef () -funktionen.
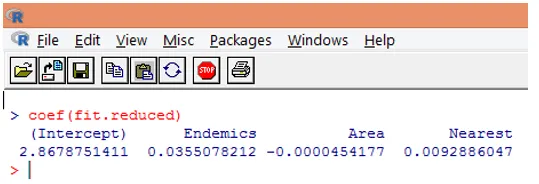
I Poisson-regression modelleres den afhængige variabel som loggen for den betingede gennemsnitlige log (l). Regressionsparameteren på 0, 0355 for Endemics indikerer, at en enheds stigning i variablen er forbundet med en 0, 04 stigning i det logiske gennemsnitlige antal arter, der holder andre variabler konstant. Afskærmningen er et log-middelantal af arter, når hver af prediktorerne er lig med nul.
10. Det er imidlertid meget lettere at fortolke regressionskoefficienterne i den oprindelige skala for den afhængige variabel (antal arter i stedet for lognummer af arter). Eksponentieringen af koefficienterne tillader en let fortolkning. Dette gøres som følger.
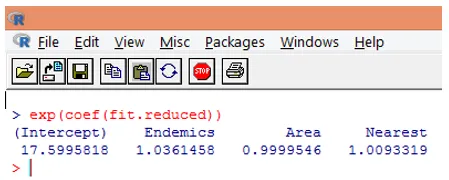
Fra de ovennævnte fund kan vi sige, at en enhedsstigning i område multiplicerer det forventede antal arter med 0, 9999, og en enhedsforøgelse i antallet af endemiske arter repræsenteret af Endemics multiplicerer antallet af arter med 1.0361. Det vigtigste aspekt af Poisson-regression er, at eksponentierede parametre har en multiplikativ snarere end en additiv effekt på responsvariablen.
11. Ved hjælp af ovenstående trin opnåede vi en Poisson-regressionsmodel til forudsigelse af antallet af plantearter på Galapagosøerne. Det er dog meget vigtigt at kontrollere for overdispersion. I Poisson-regression er variansen og midlerne ens.
Overdispersion forekommer, når den observerede varians af responsvariablen er større end forventet af Poisson-fordelingen. Analyse af overdispersion bliver vigtig, da det er almindeligt med tælledata, og det kan have negativ indflydelse på de endelige resultater. I R kan overdispersion analyseres ved hjælp af pakken “qcc”. Analysen er illustreret nedenfor.
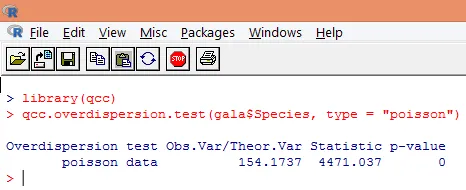
Ovennævnte signifikante test viser, at p-værdien er mindre end 0, 05, hvilket kraftigt antyder tilstedeværelsen af overdispersion. Vi prøver at montere en model ved hjælp af funktionen glm () ved at udskifte familie = “Poisson” med familie = “quasipoisson”. Dette illustreres nedenfor.
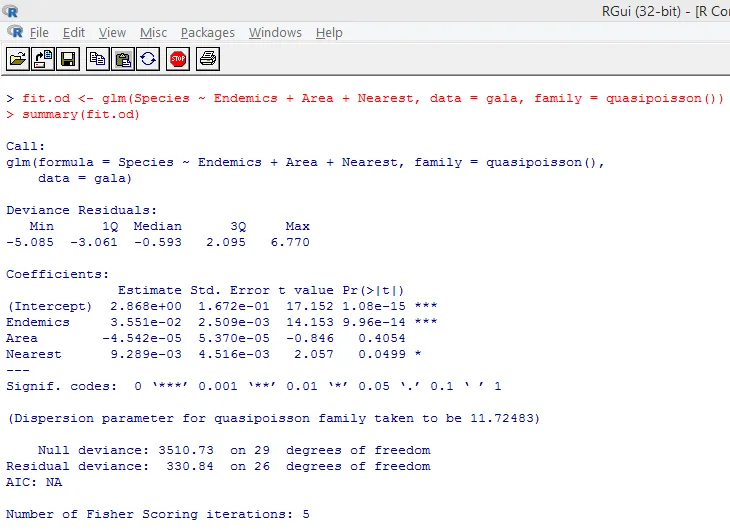
Ved tæt at studere ovennævnte output kan vi se, at parameterestimaterne i quasi-Poisson-fremgangsmåden er identiske med dem, der er produceret af Poisson-fremgangsmåden, skønt standardfejlene er forskellige for begge fremgangsmåder. Desuden er p-værdien for Area for p-værdien større end 0, 05, hvilket skyldes større standardfejl.
Betydningen af Poisson-regression
- Poisson-regression i R er nyttig til korrekte forudsigelser af den diskrete / tællende variabel.
- Det hjælper os med at identificere de forklarende variabler, der har en statistisk signifikant effekt på responsvariablen.
- Poisson-regression i R er bedst egnet til begivenheder af ”sjælden” art, da de har en tendens til at følge en Poisson-distribution i forhold til almindelige begivenheder, der normalt følger en normal fordeling.
- Det er velegnet til anvendelse i tilfælde, hvor responsvariablen er et lille heltal.
- Det har brede applikationer, da en forudsigelse af diskrete variabler er afgørende i mange situationer. I medicin kan det bruges til at forudsige lægemidlets indvirkning på helbredet. Det bruges stærkt i overlevelsesanalyse som død af biologiske organismer, svigt i mekaniske systemer osv.
Konklusion
Poisson-regression er baseret på begrebet Poisson-distribution. Det er en anden kategori, der hører til sættet med regressionsteknikker, der kombinerer egenskaberne af både lineære såvel som logistiske regressioner. I modsætning til logistisk regression, der kun genererer binær output, bruges den til at forudsige en diskret variabel.
Anbefalede artikler
Dette er en guide til Poisson Regression i R. Her diskuterer vi introduktionen Implementering af Poisson Regression og betydningen af Poisson Regression. Du kan også gennemgå vores andre foreslåede artikler for at lære mere–
- GLM i R
- Tilfældig nummergenerator i R
- Regressionsformel
- Logistisk regression i R
- Lineær regression vs logistisk regression | Topforskelle