

Introduktion til Apache Flume
Apache Flume er Data Ingestion Framework, der skriver begivenhedsbaserede data til Hadoop Distribueret filsystem. Det er et kendt faktum, at Hadoop behandler Big data, der opstår et spørgsmål, hvordan dataene, der genereres fra forskellige webservere, overføres til Hadoop File System? Svaret er Apache Flume. Flume er designet til indtagelse af højvolumen til Hadoop af begivenhedsbaserede data.
Overvej et scenario, hvor antallet af webservere genererer logfiler, og disse logfiler skal transmitteres til Hadoop-filsystemet. Flume indsamler disse filer som begivenheder og indtager dem i Hadoop. Selvom Flume bruges til at transmittere til Hadoop, er der ingen stiv regel om, at destinationen skal være Hadoop. Flume er i stand til at skrive til andre rammer som Hbase eller Solr.
Flume Arkitektur
Generelt er Apache Flume-arkitektur sammensat af følgende komponenter:
- Flume Source
- Flume Channel
- Flume Vask
- Flume Agent
- Flume-begivenhed
Lad os tage et kort kig på hver Flume-komponent
1. Flume Source
En Flume Source findes på datageneratorer som Face book eller Twitter. Kilde indsamler data fra generatoren og overfører disse data til Flume Channel i form af Flume Events. Flume understøtter forskellige typer kilder, såsom Avro Flume Source - forbinder på Avro-port og modtager begivenheder fra Avro-ekstern klient, Thrift Flume Source-forbindes på Thrift-port og modtager begivenheder fra eksterne Thrift-klientstrømme, Spooling Directory Source og Kafka Flume Source.
2. Flume Channel
En mellemlager, der buffrer begivenheder, der er sendt af Flume Source, indtil de er forbrugt af Sink, kaldes Flume Channel. Channel fungerer som en mellembro mellem Source og Sink. Flume-kanaler er transaktionsmæssige.
Flume giver support til filkanalen og hukommelseskanalen. Filkanalen er holdbar, hvilket betyder, at når dataene er skrevet til kanal, vil de ikke gå tabt, selvom agenten genstarter. I hukommelsen gemmes kanalbegivenheder i hukommelsen, så det er ikke holdbart, men meget hurtigt i karakter.
3. Flume Vask
En Flume Sink er til stede på datareponier som HDFS, HBase. Flume sink forbruger begivenheder fra Channel og gemmer dem til Destination butikker som HDFS. Der er ingen sådan regel, at vasken skal levere begivenheder til Store, i stedet kan vi konfigurere den på en sådan måde, at en vask kan levere begivenheder til en anden agent. Flume understøtter forskellige dræn, såsom HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
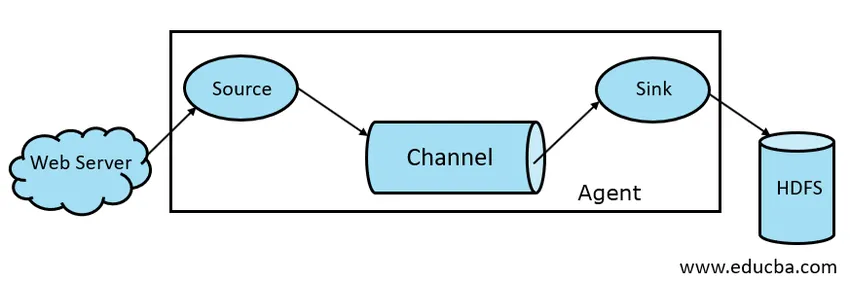
Fig. 1.1 Grundlæggende flume-arkitektur
4. Flume Agent
En Flume-agent er en langvarig Java-proces, der kører på Source - Channel - Sink Combination. Flume kan have mere end et middel. Vi kan betragte Flume som en samling af tilsluttede Flume-agenter, der er distribueret i naturen.
5. Flume-begivenhed
En begivenhed er den dataenhed, der transporteres i Flume . Generel repræsentation af Data Object i Flume kaldes Event. Arrangementet består af en nyttelast fra et byte-array med valgfri overskrifter.
Arbejde med flume
En Flume-agent er en java-proces, der består af Source - Channel - Sink i sin enkleste form. Kilde indsamler data fra datagenerator i form af Begivenheder og leverer dem til Channel. En kilde kan leveres til flere kanaler pr. Krav. Fan out er processen, hvor en enkelt kilde vil skrive til flere kanaler, så de kan levere til flere dræn.
En begivenhed er den basale enhed af data, der transmitteres i Flume. Channel buffer dataene, indtil de indtages af Sink. Sink indsamler dataene fra Channel og leverer dem til centraliseret datalagring som HDFS eller Sink kan videresende disse begivenheder til et andet Flume-agent som pr. Krav.
Flume understøtter transaktioner. For at opnå pålidelighed bruger Flume separate transaktioner fra kilde til kanal og fra kanal til synke. Hvis der ikke leveres begivenheder, rulles transaktionen tilbage og senere leveres igen.
For at forstå brugen af Flume, lad os tage et eksempel på Flume-konfiguration, hvor kilden spooler biblioteket og vasken er Hdfs. I dette eksempel er Flume-agent i den enkleste form, dvs. topkilde - kanal - synketopologi, der er konfigureret ved hjælp af en Java-egenskabsfil.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
I ovenstående konfigurationseksempel er agent den base, som vi definerer andre egenskaber med. source1 og sink1 og channel1 er navnene på henholdsvis kilde, vask og kanal, og deres typer og placering er også nævnt i overensstemmelse hermed.
Fordele ved Apache Flume
- Flume er skalerbar, pålidelig og fejltolerant. Disse egenskaber diskuteres detaljeret nedenfor
- Skalerbar - Flume er skalerbar vandret, dvs. vi kan tilføje nye knudepunkter ifølge vores krav
- Pålidelig - Apache Flume har support til transaktioner og sikrer, at ingen data går tabt i processen med datatransmission. Det har forskellige transaktioner fra kilde til kanal og fra kanal til kilde.
- Flume kan tilpasses og giver support til forskellige kilder og dræn, såsom Kafka, Avro, spooling directory, Thrift osv.
- I Flume kan en enkelt kilde transmittere data til flere kanaler, og disse kanaler vil igen sende dataene til flere synke, således at en enkelt kilde kan transmittere data til flere synke. Denne mekanisme kaldes Fan out. Flume understøtter også til ventilator ud.
- Flume giver den jævne strøm af datatransmission, dvs. hvis datalæsningshastigheden øges, og datahastigheden også øges.
- Selvom Flume generelt skriver data til centraliseret opbevaring som HDFS eller Hbase, kan vi konfigurere Flume ifølge vores krav, så Sink kan skrive data til en anden agent. Dette viser Flume fleksibilitet
- Apache Flume er open source i naturen.
Konklusion
I denne Flume-artikel diskuteres komponenter i Flume og bearbejdning af Flume i detaljer. Flume er en fleksibel, pålidelig og skalerbar platform til transmission af data til en centraliseret butik som HDFS. Dens evne til at integrere med forskellige applikationer som Kafka, Hdfs, Thrift gør det til en bæredygtig mulighed for indtagelse af data.
Anbefalede artikler
Dette har været en guide til Apache Flume. Her diskuterer vi arkitektur, funktion og fordele ved Apache Flume. Du kan også se på de følgende artikler for at lære mere -
- Hvad er Apache Flink?
- Forskellen mellem Apache Kafka vs Flume
- Big Data Arkitektur
- Hadoop Værktøjer
- Lær de forskellige JavaScript-begivenheder