
Forskellen mellem HBase og Cassandra
HBase er en database, der bruger Hadoop distribuerede filsystem til dens lagring. HBase er en vigtig del af HDFS og kører på toppen af Hadoop Cluster. HBase er ikke en traditionel relationsdatabase, den kræver forskellige datamodelleringsmetoder. Cassandra arbejder på datareplikationsmodellen, så hvis der ikke er nogen node utilgængelighed, vil der ikke være tab af data. Cassandra er en distribueret database, så data kan fås adgang til en klient fra enhver klynge og fra enhver knude
1.1) Cassandra:
Det blev startet af Facebook, for det er altid på applikationskravet. Cassandra blev startet i 2005 og stilles til rådighed for offentligheden i 2008. Cassandra blev udviklet til altid-på applikationer såsom sociale netværk som Facebook & Twitter.
Cassandra arbejder på “altid-på” -arkitektur og har en Active-Active node-model, så der ikke er nogen SPoF (Enkelt mislykket punkt). CQL (Cassandra Query Language) er Cassandras forespørgselssprog, men har syntaks som SQL. Det understøtter alle større OS som Linux, Unix, OSX og windows.
Altid på:
Cassandra er en database med en distributionsmodel, og alle noder er de samme inden for klyngen. Data replikeres på konfigurerbare knudepunkter, så i tilfælde af svigt i nogle nej. af noder vil ikke resultere i tab af data.
(Altid på model)
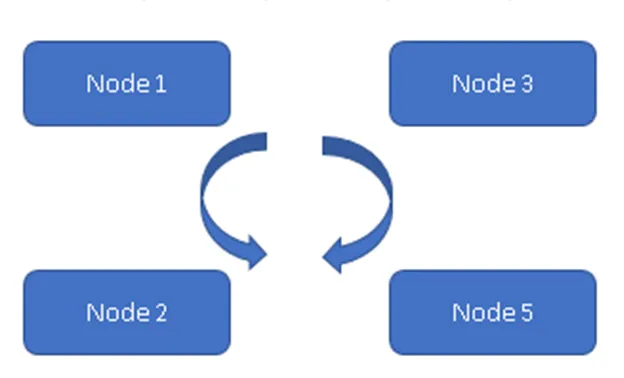
I figur 1 synkroniseres alle de fire noder med hinanden og gentager dataene i klyngen. Alle arbejder på Active-Active Model, så i tilfælde af knudepunktfejl vil det ikke resultere i tab af data. En klient kan læse dataene fra resten af de tilgængelige knudepunkter.
1.2) HBase:
HBase er en NoSQL-baseret database og designet til at behandle forespørgsler i store tabeller med milliarder af rækker med millioner af kolonner og køre på tværs af en klynge med råvare / normal hardware. Det giver dig realtidsforespørgselsfunktioner med hastigheden på en " nøgle / værdi butik " .
HBase er faktisk baseret / arbejder på en fire-dimensionel datamodel.
- Række-id / række-tast
- Kolonne Familie.
- Nøgleværdipar.
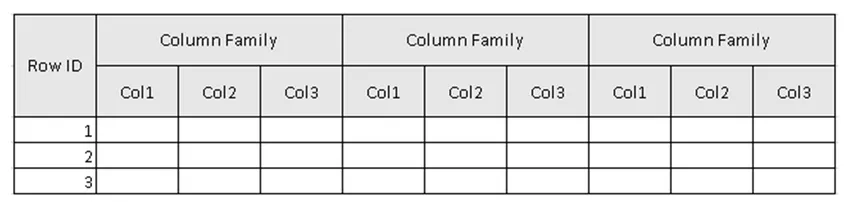
(Figur 2, eksempelskema i tabellen i HBase.)
I figur 2 er tabel samling af kolonnefamilie & kolonnefamilie er samling af kolonner. Kolonner er samlingen af nøgleværdipar
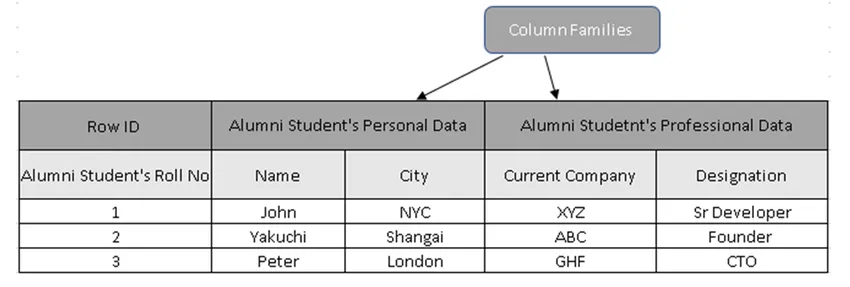
(Figur 3, prøvestabel i HBase)
I figur 3 er søjlefamilier indsamlingen af Alumni-studerendes data, og række-id'er (række nøgler) indeholder studentens rullenr.
Faktisk rækketaster har den unikke værdi over for kolonnefamiliedataene. Ved at bruge Row Key kan man udtrække hele detaljerne, årsager til, at søjleorienterede databaser er meget hurtigere end traditionelle databaser.
Apache HBase kan bruges til tilfældig læse / skriveadgang, og det giver fejlstøtte. Det understøtter også replikering og arbejde med distributionsdatabasemodellen.
Sammenligning af hoved til hoved mellem HBase og Cassandra (Infografik)
Nedenfor er top 9 forskellen mellem HBase vs Cassandra
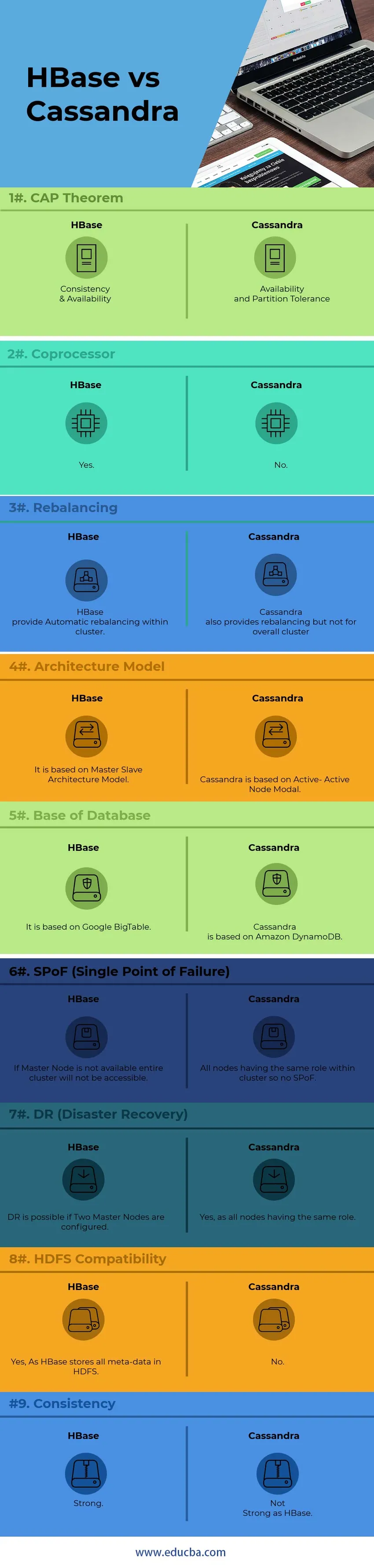 Vigtige forskelle mellem HBase vs Cassandra
Vigtige forskelle mellem HBase vs Cassandra
Nedenfor er lister over punkter, der beskriver de vigtigste forskelle mellem HBase og Cassandra:
1) Ved intern knudekommunikation bruger Cassandra GOSSIP-protokol, mens HBase er baseret på Zookeeper. Tjenester ved GOSSIP Protocol er integreret med Cassandra på anden siden. Zookeeper er en helt separat distributionsapplikation.
2) I Cassandra-arkitektur fungerer alle noder som Active Node, mens HBase-arkitekt følger Master-Slave Node-modellen. I Active-Active Node-modellen er der ingen SPoF (Single Point of Failure). I HBase, vil Master-noden gå ned, vil hele klyngen ikke være tilgængelig.
3) HBase-støtte Binær træsøgningsmodel, mens Cassandra ikke understøtter B-træmodel Uden B-træ, kan du ikke søge i brugers kolonne Familie til alle med en jubilæum i april, mens du kan søge efter alle, der bor i Beijing med en Jubilæum i april.
4) HBase, support C, C ++, Java, Python, Scala scripting sprog, mens Cassandra også understøtter JavaScript & Ruby.
5) HBase har en funktion kaldet coprocessorer, mens Cassandra ikke har en sådan funktion som nu. Koprocessorer tilvejebringer et bibliotek og et kørselsmiljø til eksekvering af brugerkode på HBase-regionens server og masterprocesser.
6) HBase er designet til at understøtte datavarehus, mens Cassandra er perfekt til programmer, der kører hele tiden som web- og mobilapplikationer.
7) HBase-forespørgselssprog er et brugerdefineret sprog, der skal læres, mens Cassandra bruger sit eget udviklede CQL (Cassandra Query Language), som er SQL-lignende sprog
8) At styre Cassandra er meget lettere end HBase. I Cassandra skal der køres en enkelt Java-proces pr. Knude, mens der er behov for HBase, fuldt operationel HDFS, flere HBase-processer og et Zookeeper-system.
9) HBase gør ende til ende kontrolsum og automatisk rebalansering, mens Cassandra ikke understøtter rebalansering af klyngen samlet.
10) Baseret på “ CAP Theorem” arbejder Cassandra på AP Model, mens HBase er CP Model.
CAP-sætning
Dette sætning bruges til distribuerede systemer. C står for Konsistens, A betyder Tilgængelighed & P er partitionstolerance. CAP-sætning forklaret nedenfor:
C (Konsistens): Konsistens betyder, at hvis nogen har skrevet en værdi til en database, kan andre straks læse den samme værdi.
A (Tilgængelighed) : Tilgængelighed betyder, at hvis nogle noder ikke er tilgængelige i din klynge (Noder Gik ned / ikke bor i klyngen på grund af noget problem), vil det ikke påvirke hele klyngen, og Distribueret system / database vil være tilgængelig for at få adgang til dataene. Klyngen er tilgængelig for alle slags opgaver.
P (Partition Tolerance): Partition Tolerance betyder, at hvis One Data Center går ned, skal det ikke påvirke de præsenterede data på knudepunkterne, og alle data skal være tilgængelige på ethvert tidspunkt. Det betyder, at partitionstolerance tillader bedre replikering af data til andre Data Center såvel som i klyngemiljøet.
HBase vs Cassandra sammenligningstabel
| Points | HBase | Cassandra |
| CAP-sætning | Konsistens og tilgængelighed | Tilgængelighed og partitionstolerance |
| Coprocessor | Ja | Ingen |
| rebalancering | HBase giver automatisk rebalansering inden for en klynge. | Cassandra leverer også rebalansering, men ikke for den samlede klynge |
| Arkitekturmodel | Den er baseret på Master-Slave Architecture Model | Cassandra er baseret på Active-Active Node Modal |
| Base af databasen | Det er baseret på Google BigTable | Cassandra er baseret på Amazon DynamoDB |
| SPoF (Enkelt mislykket punkt) | Hvis Master Node ikke er tilgængelig, vil hele klyngen ikke være tilgængelig | Alle knudepunkter, der har den samme rolle inden for klyngen, så ingen SPoF |
| DR (Disaster Recovery) | DR er mulig, hvis to masternoder er konfigureret. | Ja, da alle noder har samme rolle |
| HDFS-kompatibilitet | Ja, da HBase gemmer alle metadata i HDFS | Ingen |
| Konsistens | Stærk | Ikke stærk som HBase |
Konklusion - HBase vs Cassandra
Facebook og en anden side af socialt netværk foretrækker HBase (tidligere brugte begge Cassandra, henvis Facebook-post) på grund af dens tilgængelighed, som andre sider bankdomænesektor ser efter sikkerhed for hver sin økonomiske transaktion, så de ville vælge Cassandra over HBase.
Cassandra nøgleegenskaber involverer Høj tilgængelighed, minimal administration og Intet SPoF (Single Point of Failure) på anden siden HBase er god til hurtigere læsning og skrivning af data med lineær skalerbarhed.
Virksomheder som Verizon, Bloomberg, Bank of America og meget mere bruger HBase og Cassandra bruges af store sociale netværkssider som Twitter, Facebook osv.…
Vi kan ikke konkludere, hvilken der er bedst, HBase og Cassandra har begge deres egen fordel og ulemper. Faktisk udførelse af både HBase- og Cassandra-databaser kan ses i produktionsmiljøet.
Anbefalede artikler:
Dette har været en guide til HBase vs Cassandra, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Hadoop vs Apache Spark - Interessante ting, du har brug for at vide
- Hvordan knækker Hadoop-udviklerintervjuet?
- Top 5 Big Data Trends
- 5 udfordringer med Big Data Analytics