

Introduktion af tilbagevendende neurale netværk (RNN)
Et tilbagevendende neuralt netværk er en type af et kunstigt neuralt netværk (ANN) og bruges i anvendelsesområder for naturlig sprogbehandling (NLP) og talegenkendelse. En RNN-model er designet til at genkende datasekvensegenskaber og derefter bruge mønstrene til at forudsige det kommende scenarie.
Arbejde med tilbagevendende neurale netværk
Når vi taler om traditionelle neurale netværk, er alle output og input uafhængige af hinanden som vist i nedenstående diagram:
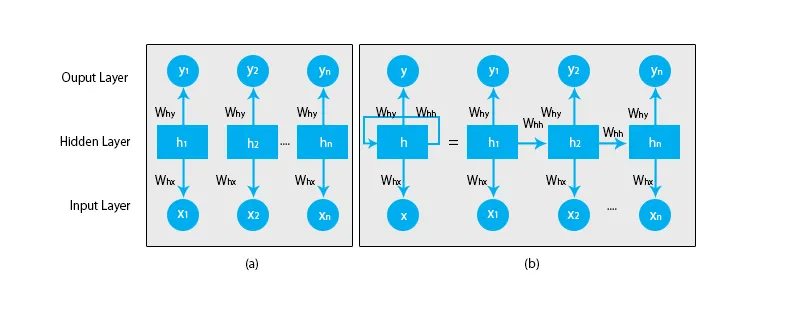
Men i tilfælde af tilbagevendende neurale netværk, mates output fra de foregående trin til input fra den aktuelle tilstand. For at forudsige det næste bogstav i et hvilket som helst ord eller for at forudsige det næste ord i sætningen er der et behov for at huske de foregående bogstaver eller ordene og gemme dem i en form for hukommelse.
Det skjulte lag er det, der husker nogle oplysninger om sekvensen. Et simpelt virkelighedseksempel, som vi kan forholde RNN til, er, når vi ser en film, og i mange tilfælde er vi i stand til at forudsige, hvad der vil ske dernæst, men hvad nu, hvis nogen netop kom med i filmen, og han bliver bedt om at forudsige, hvad sker der næste? Hvad bliver hans svar? Han eller hun vil ikke have nogen anelse, fordi de ikke er opmærksomme på de foregående begivenheder i filmen, og de har ikke nogen hukommelse om det.
En illustration af en typisk RNN-model er vist nedenfor:
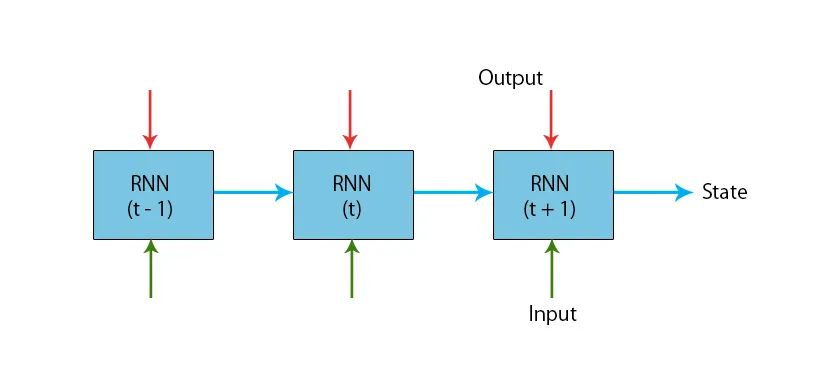
RNN-modellerne har en hukommelse, der altid husker, hvad der blev gjort i tidligere trin, og hvad der er beregnet. Den samme opgave udføres på alle input, og RNN bruger den samme parameter for hver af inputene. Da det traditionelle neurale netværk har uafhængige sæt input og output, er de mere komplekse end RNN.
Lad os nu prøve at forstå det tilbagevendende neurale netværk ved hjælp af et eksempel.
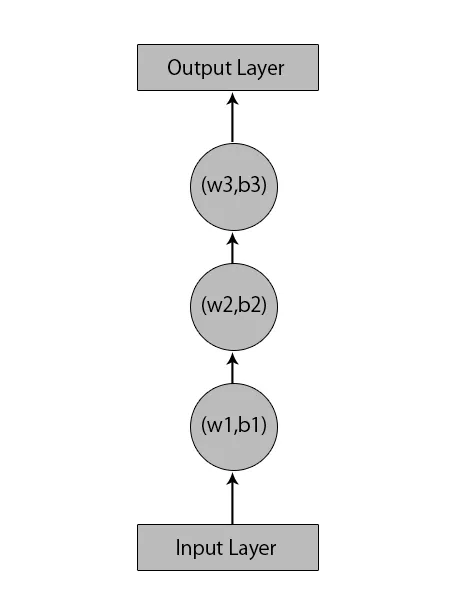
Lad os sige, vi har et neuralt netværk med 1 inputlag, 3 skjulte lag og 1 outputlag.
Når vi taler om andre eller de traditionelle neurale netværk, vil de have deres egne sæt af forspændinger og vægte i deres skjulte lag som (w1, b1) for skjult lag 1, (w2, b2) til skjult lag 2 og (w3, b3) ) for det tredje skjulte lag, hvor: w1, w2 og w3 er vægterne og, b1, b2 og b3 er forspændelserne.
I betragtning af dette kan vi sige, at hvert lag ikke er afhængigt af noget andet, og at de ikke kan huske noget om det forrige input:
Hvad en RNN nu vil gøre, er følgende:
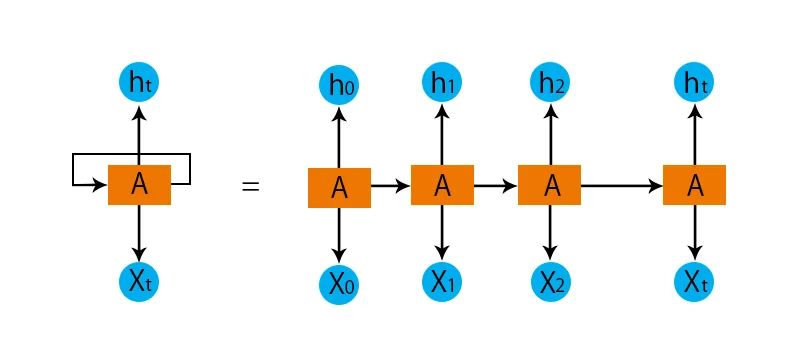
- De uafhængige lag konverteres til det afhængige lag. Dette gøres ved at give de samme lag de samme forspændinger og vægte. Dette reducerer også antallet af parametre og lag i det tilbagevendende neurale netværk, og det hjælper RNN med at huske den forrige output ved at udlæse tidligere output som input til det kommende skjulte lag.
- For at opsummere kan alle de skjulte lag sammenføjes til et enkelt tilbagevendende lag, så vægterne og forspændingerne er ens for alle de skjulte lag.
Så et tilbagevendende neuralt netværk vil se sådan ud som nedenfor:
Nu er det tid til at håndtere nogle af ligningerne for en RNN-model.
- Til beregning af den aktuelle tilstand,
h t= f (h t-1, x t ),
Hvor:
x t er inputtilstanden
h t-1 er den forrige tilstand,
h t er den aktuelle tilstand.
- Til beregning af aktiveringsfunktionen
h t= tanh (W hh h t-1 +W xh x t ),
Hvor:
W xh er vægten ved inputneuron,
Whh er vægten ved tilbagevendende neuron.
- Til beregning af output:
Y t =W hy h t.
Hvor,
Y t er output og,
W er vægten ved outputlaget.
Trin til træning af et tilbagevendende neuralt netværk
- I inputlagene sendes den indledende input, hvor alle har samme vægt og aktiveringsfunktion.
- Ved hjælp af den aktuelle input og den forrige statusoutput beregnes den aktuelle tilstand.
- Nu vil den aktuelle tilstand h t blive h t-1 for andet gangstrin.
- Dette fortsætter med at gentage for alle trin, og for at løse et bestemt problem, kan det gå så mange gange at deltage i oplysningerne fra alle de foregående trin.
- Det sidste trin beregnes derefter af den aktuelle tilstand for den endelige tilstand og alle andre tidligere trin.
- Nu genereres der en fejl ved at beregne forskellen mellem den faktiske output og den output, der genereres af vores RNN-model.
- Det sidste trin er, når processen med backpropagation forekommer, hvor fejlen backpropagates for at opdatere vægtene.
Fordele ved tilbagevendende neurale netværk
- RNN kan behandle input af enhver længde.
- En RNN-model er modelleret til at huske hver information igennem hele tiden, hvilket er meget nyttigt i enhver tidsseries forudsigelse.
- Selv hvis inputstørrelsen er større, øges ikke modelstørrelsen.
- Vægtene kan deles på tværs af tidstrinnene.
- RNN kan bruge deres interne hukommelse til at behandle den vilkårlige række af input, hvilket ikke er tilfældet med feedforward neurale netværk.
Ulemper ved tilbagevendende neurale netværk
- På grund af dens tilbagevendende karakter er beregningen langsom.
- Uddannelse af RNN-modeller kan være vanskelig.
- Hvis vi bruger relu eller tanh som aktiveringsfunktioner, bliver det meget vanskeligt at behandle sekvenser, der er meget lange.
- Tilbøjelig til problemer såsom eksplodering og gradient forsvinden.
Konklusion
I denne artikel har vi lært en anden type kunstigt neuralt netværk kaldet tilbagevendende neuralt netværk, vi har fokuseret på den vigtigste forskel, der gør, at RNN skiller sig ud fra andre typer neurale netværk, de områder, hvor det kan bruges vidt, såsom i talegenkendelse og NLP (Natural Language Processing). Endvidere har vi gået bag arbejdet med RNN-modeller og funktioner, der bruges til at opbygge en robust RNN-model.
Anbefalede artikler
Dette er en guide til tilbagevendende neurale netværk. Her diskuterer vi introduktionen, hvordan det fungerer, trin, fordele og ulemper ved RNN osv. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -- Hvad er neurale netværk?
- Rammer for maskinlæring
- Introduktion til kunstig intelligens
- Introduktion til Big Data Analytics
- Implementering af neurale netværk