
Introduktion til histogram i R
I denne artikel starter vi med det grundlæggende histogram i R-implementering og tilpasninger. Histogram spiller en vigtig rolle i dataanalyser til visualisering af dataene. R-programmering er et specielt miljø til statistisk beregning og grundlæggende data for datavidenskab. I R programmeres datasæt og funktioner sammen i form af pakker. De fleste af de visuelle analyseprogrammer bruger histogrammer og udgør skraldespand som standard. De giver mulighed for hurtigt at forstå indsigt i dataene, som er en primær rolle i datavidenskaben. Her skal vi opbygge et histogram ved hjælp af R-kommandoer.
Hvad er histogram?
Histogrammet er en billedlig repræsentation af en datasætfordeling, som vi let kunne analysere, hvilken faktor der har en højere datamængde og mindst data. Med andre ord tillader histogrammet at udføre kumulative frekvensdiagrammer i x-aksen og y-aksen. Faktisk tager histogrammer både grupperede og ikke-grupperede data. For et grupperet datahistogram konstrueres ved at overveje klassegrænser, hvorimod ugrupperede data er det nødvendigt at danne den grupperede frekvensfordeling. De hjælper med at analysere omfanget og placeringen af dataene effektivt. Nogle fælles strukturer af histogrammer anvendes som normal, skæv klippe under datadistribution.
I modsætning til en søjle har diagramhistogram ikke mellemrum mellem søjlerne, og søjlerne her er navngivet som bakker, med hvilke data er repræsenteret i lige intervaller. Histogram Tar kontinuerlig variabel og opdeles i intervaller, det er nødvendigt at vælge den rigtige skraldebredde. Den største forskel mellem søjlediagram og histogram er førstnævnte bruger nominelle datasæt til plot, mens histogram plotter de kontinuerlige datasæt. R bruger funktionen hist () til at oprette histogrammer. Denne hist () -funktion bruger en vektor af værdier til at plotte histogrammet. Histogram omfatter et x-akses interval af kontinuerlige værdier, y-aksen plotter hyppige dataværdier i x-aksen med bjælker med variationer i højder.
Syntaks:
Syntaks for oprettelse af histogram er
hist (v, main, xlab, xlim, ylim, breaks, col, border)
where v – vector with numeric values
main – denotes title of the chart
col – sets color
border -sets border color to the bar
xlab - description of x-axis
xlim - denotes to specify range of values on x-axis
ylim – specifies range values on y-axis
break – specifies the width of each bar.
Oprettelse af et histogram i R
Til analyse kræver histogram til formål et indbygget datasæt for at importere i R. R, og dets biblioteker har en række grafiske pakker og funktioner. Her bruger vi schweiziske og Air Passengers datasæt. For at beregne et histogram til en given dataværdi fungerer hist () -funktion sammen med et $-tegn til at vælge den bestemte kolonne i en data fra datasættet for at oprette et histogram.
Følgende eksempel beregner et histogram af dataværdien i kolonnen Undersøgelse af datasættet kaldet schweizisk.
Eksempel 1: Lad os oprette et simpelt histogram
Kode:
hist (swiss $Examination)
Produktion:
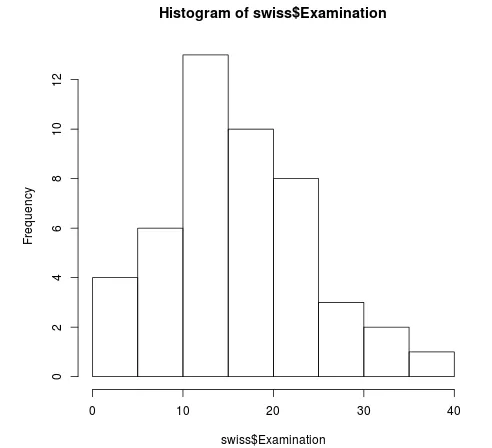
Hist oprettes til et datasæt schweizisk med en kolonneundersøgelse. dette plotter simpelthen en skraldespand med frekvens og x-akse.
Eksempel 2: Histogram med flere argumenter
For at opnå en bedre forståelse af histogrammer er vi nødt til at tilføje flere argumenter til hist-funktionen for at optimere visualiseringen af diagrammet. Ændring af x og y-etiketten til en række værdier xlim og ylim-argumenter føjes til funktionen.
Eksempel:
hist (Air Passengers, xlim=c (150, 600), ylim=c (0, 35))
In the above example x limit varies from 150 to 600 and Y – 0 to 35.
// Adding breaks
hist (AirPassengers,
main="Histogram with more Arg",
xlab="Name List",
border="Green",
col="Orange",
xlim=c (100, 600),
ylim=c(0, 40),
breaks=5)
Produktion:
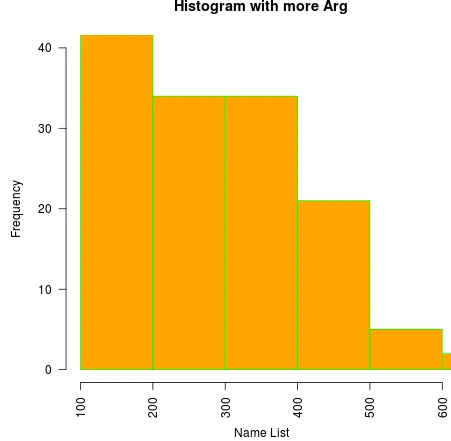
Ovenfor kode tegner et histogram for værdierne fra datasættet Air Passengers, giver titlen som "Histogram for more arg", x-aksemærket som "Navneliste", med en grøn kant og en gul farve til bjælkerne ved at begrænse værdi som 100 til 600, værdierne udskrives på y-aksen med 2 og gør bakkebredden til 5.
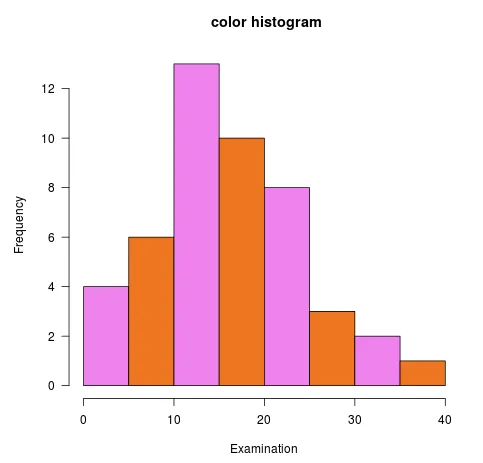
Tilføje to forskellige farver til baren
hist (swiss$Examination, col=c ("violet”, "Chocolate2"), xlab="Examination”, las =1, main=" color histogram")
Produktion:
Tilføjelse af flere søjler til histogrammet
hist (swiss$Education, breaks=40, col="violet", xlab="Education", main=" Extra bar histogram")
Produktion:
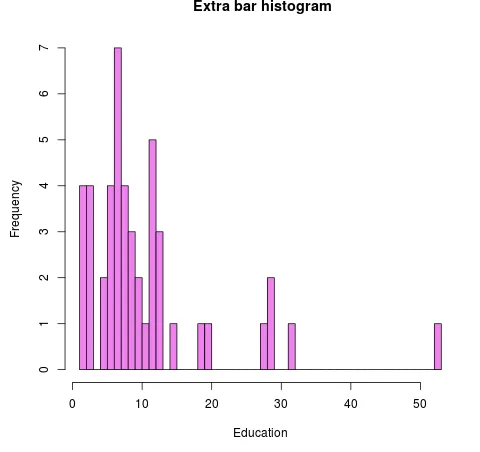
Eksempel 3: Histogram i R Det returnerer en værdi
Air <- AirPassengers
hist (Air)
h <- hist (Air)
h
$breaks
Produktion:
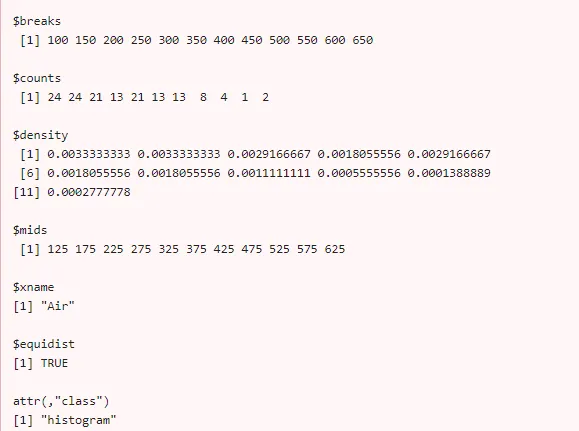
Eksempel 4: Brug af break-argument til at ændre skraldebredden
For at have flere brudpunkter mellem bredden foretrækkes det at bruge værdien i funktionen c ().
hist (AirPassengers, breaks=c (100, seq (200, 700, 150)))
Produktion:
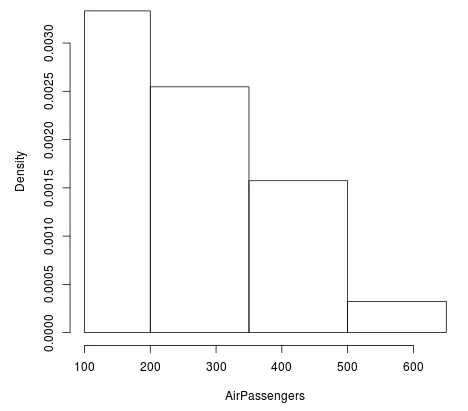
Ovenstående graf tager bredden af bjælken gennem sekvensværdier.
Eksempel 5: Implementering af den normale distributionskurve i histogram
Vi skal bruge datasættet 'schweizisk' til dataværdierne til at tegne en graf. Her bruges funktionskurven () til at vise fordelingslinjen.
Kode:
curve (dnorm(x, mean=mean(swiss$Education), sd=sd(swiss$Education)), add=TRUE, col="red")
Produktion:
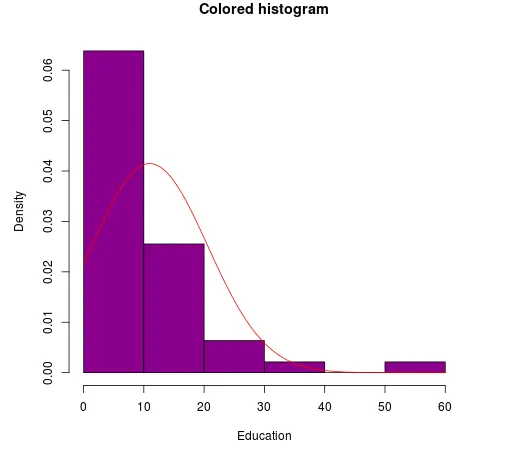
Eksempel 6: Plotning af sandsynlighedsfordeling
hist (AirPassengers,
main="Histogram ",
xlab="Passengers",
border="Yellow",
col="pink",
xlim=c(100, 600),
las=2,
breaks=6,
prob = TRUE)
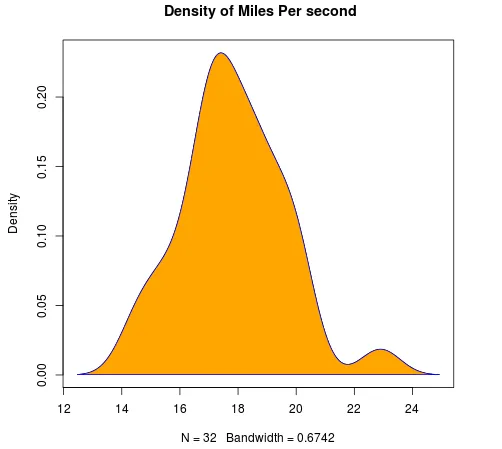
Oprettelse af densitetsplaner i histogram i R
Fordelingen af en variabel oprettes ved hjælp af funktionstæthed (). Nedenfor er eksemplet med datasættet mtcars. Tæthedsplaner hjælper med fordelingen af formen.
density () // this function returns the density of the data
library(ggplot2)
d <- density (mtcars $qsec)
plot (d, main=" Density of Miles Per second")
polygon (d, col="orange",>
Produktion:
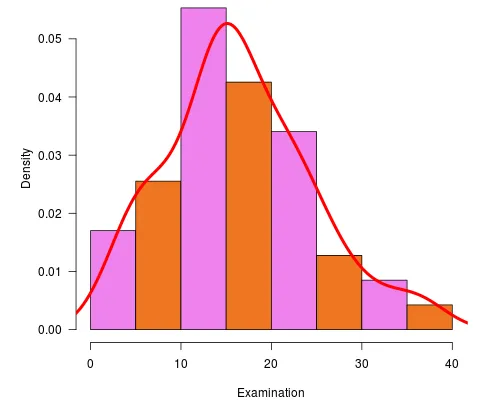
Using Line () function
hist (swiss$Examination, freq = FALSE, col=c ("violet”, "Chocolate2"),
xlab="Examination”, las =1, main=" Line Histogram")
lines(density(swiss$Examination), lwd = 4, col = "red")
Det følgende histogram i R viser højden som en undersøgelse på x-aksen og densitet er afbildet på y-aksen.
Produktion:
Konklusion
Det handler om histogrammet, og netop histogram er den nemmeste måde at forstå dataene på. Som vi har set med et histogram, kunne vi tegne enkeltstående, flere diagrammer ved hjælp af skraldebredde, akse korrektion, skiftende farver osv. Histogrammet hjælper med at visualisere de forskellige former for data. Endelig har vi set, hvordan histogrammet tillader analyse af datasæt og midtpunkter bruges som etiketter i klassen. Histogrammet hjælper med at skifte intervaller til at producere en forbedret beskrivelse af dataene og fungerer, især med numeriske data. histogrammer er mere foretrukne i analysen på grund af deres fordel ved at vise et stort datasæt. Baseret på output kunne vi visuelt skjule dataene og let at gøre nogle antagelser.
Anbefalede artikler
Dette har været en guide til Histogram i R. Her har vi drøftet konceptet, syntaks og hvordan man opretter et histogram i R med eksempler. Du kan også se på de følgende artikler for at lære mere -
- Histogrameksempler
- Karriere inden for R-programmering
- Gantt-diagram i Tableau
- Karriere inden for computerprogrammering
- Sådan opretter du en linjegraf i R?