
Definition af middelskiftalgoritme
Gennemsnitlig skiftalgoritme falder ind under uovervåget læring, der er kategoriseret som Clustering-algoritmen. Ideologien med middelskiftalgoritmen er, at den iterativt tildeler datapunkter til klyngerne ved at skifte mod det punkt, der har det højeste densitetspunkt (tilstand). Gennemsnitlig skift underliggende logik er baseret på begrebet estimering af kernetæthed, der omtales som KDE.
Gennemsnitlig skiftalgoritmeklynge
En uovervåget læringsteknik opdaget af Fukunaga og Hostetler for at finde klynger:
- Mean Shift er også kendt som den modus-søgende algoritme, der tildeler datapunkterne til klyngerne på en måde ved at flytte datapunkterne mod området med høj densitet. Den højeste tæthed af datapunkter kaldes modellen i regionen. Mean Shift-algoritme har applikationer, der er vidt brugt inden for computersyn og billedsegmentering.
- KDE er en metode til at estimere fordelingen af datapunkter. Det fungerer ved at placere en kerne på hvert datapunkt. Kernen i matematik er en vægtningsfunktion, der anvender vægte for individuelle datapunkter. Tilføjelse af al den enkelte kerne genererer sandsynligheden.
Kernefunktionen kræves for at opfylde følgende betingelser:
- Det første krav er at sikre, at estimering af kernetæthed er normaliseret.
- Det andet krav er, at KDE er godt forbundet med pladsens symmetri.
To populære kerne-funktioner
Nedenfor er de to populære kernefunktioner, der bruges i det:
- Flad kerne
- Gaussisk kerne
- Baseret på den anvendte Kernel-parametre varierer den resulterende densitetsfunktion. Hvis der ikke nævnes nogen kerneparameter, opfordres Gaussian Kernel som standard. KDE bruger begrebet sandsynlighedsdensitetsfunktion, som hjælper med at finde det lokale maksimum for datafordelingen. Algoritmen fungerer ved at gøre datapunkterne til at tiltrække hinanden, hvilket tillader datapunkterne mod området med høj densitet.
- Datapunkterne, der prøver at konvergere mod de lokale maksima, er af den samme klyngegruppe. I modsætning til K-Means-klyngerealgoritmen, afhænger output af Mean Shift-algoritmen ikke af antagelser om datapunktets form og antallet af klynger. Antallet af klynger bestemmes af algoritmen med hensyn til data.
- For at udføre implementeringen af Mean Shift-algoritmen bruger vi python-pakken SKlearn.
Implementering af den gennemsnitlige skiftalgoritme
Nedenfor er implementeringen af algoritmen:
Eksempel 1
Baseret på Sklearn-tutorial til Mean Shift Clustering Algorithm. Det første kodestykke implementerer en middelskiftalgoritme for at finde klyngerne i det 2-dimensionelle datasæt. Pakker brugt til at implementere middelskiftalgoritmen.
Kode:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
En vigtig ting at bemærke er, at vi vil bruge sklearns make_blobs-bibliotek til at generere datapunkter centreret på 3 steder. For at anvende middelskiftalgoritmen på de genererede punkter, skal vi indstille båndbredden, der repræsenterer interaktionen mellem længden. Sklearns bibliotek har indbyggede funktioner til at estimere båndbredden.
Kode:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
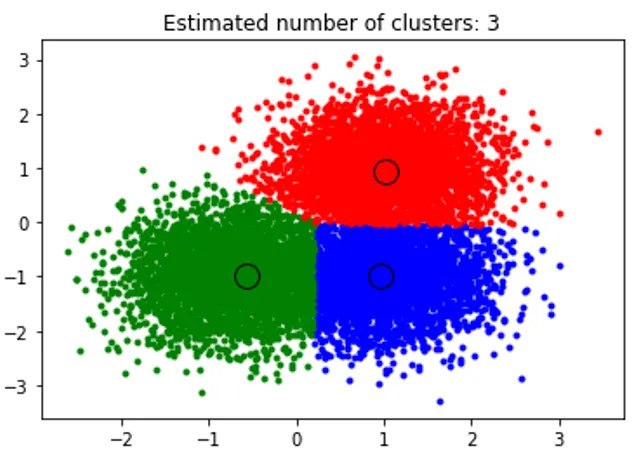
Ovenstående uddrag udfører klynger, og den algoritme, der blev fundet, klynger, der er centreret på hver klod, vi genererede. Vi kan se, at nedenstående billede, der er afbildet af uddraget, viser middelskiftalgoritmen, der er i stand til at identificere det antal klynger, der er behov for i kørselstid, og finde ud af den passende båndbredde til at repræsentere interaktionslængden.
Produktion:
Eksempel 2
Baseret på billedsegmentering i computervision. Det andet uddrag undersøger, hvordan den gennemsnitlige skiftalgoritme, der blev brugt i Deep Learning, til at udføre segmentering af det farvede billede. Vi bruger den gennemsnitlige skiftalgoritme til at identificere de rumlige klynger. Det tidligere uddrag vi brugte 2-D-datasæt, mens i dette eksempel vil udforske 3D-plads. Pixel på billedet behandles som datapunkter (r, g, b). Vi er nødt til at konvertere billedet til arrayformat, så det hver pixel repræsenterer datapunkt i det billede, vi går til segmentet. Clustering af farveværdier i mellemrum returnerer række klynger, hvor pixelene i klyngen ligner RGB-plads. Pakker, der bruges til at implementere middelskiftalgoritme:
Kode:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Nedenfor uddrag for at udføre segmentering af det originale billede:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Det genererede billede siger, at denne tilgang til at identificere figurernes figurer og bestemme de rumlige klynger kan udføres effektivt uden nogen billedbehandling.
Produktion:


Fordele og applikationer betyder skiftalgoritme
Nedenfor er fordelene og anvendelsen af den gennemsnitlige algoritme:
- Det er vidt brugt til at løse computersyn, hvor det bruges til billedsegmentering.
- Klynge af datapunkter i realtid uden at nævne antallet af klynger.
- Præsenterer godt med billedsegmentering og videosporing.
- Mere robust over for outliers.
Fordele ved middelskiftalgoritme
Nedenfor er fordele middel skift algoritmen:
- Output fra algoritmen er uafhængig af initialiseringer.
- Proceduren er effektiv, da den kun har en parameter - Båndbredde.
- Ingen antagelser om antallet af dataklynger og form.
- Det har bedre ydelse end K-Means Clustering.
Ulemper ved middel skiftalgoritme
Nedenfor er ulemperne ved den gennemsnitlige skiftalgoritme:
- Dyrt for store funktioner.
- Sammenlignet med K-Means-klynger er det meget langsomt.
- Algoritmeudgang afhænger af parameterbåndbredden.
- Output afhænger af størrelsen på vinduet.
Konklusion
Selvom det er en ligetil tilgang, der primært bruges til at løse problemer relateret til billedsegmentering, klynger. Det er relativt langsommere end K-Means, og det er beregningsdygtigt dyrt.
Anbefalede artikler
Dette er en guide til den gennemsnitlige skiftalgoritme. Her diskuterer vi problemer relateret til billedsegmentering, klynger, fordele og to kernefunktioner. Du kan også gennemgå vores andre relaterede artikler for at lære mere-
- K- betyder klynge-algoritme
- KNN Algoritme i R
- Hvad er genetisk algoritme?
- Kernemetoder
- Kernemetoder i maskinlæring
- Detalje Forklaring af C ++ Algoritme