

Forskellen mellem Data mining og web mining
Data mining : Det er et begreb at identificere et markant mønster ud fra de data, der giver et bedre resultat. Identificere mønstre, hvorfra? Fra de data, der genereres fra systemerne.
Web mining : Processen med at udføre Data mining på nettet kaldes Web mining. Udtræk webdokumenter og opdag mønstre fra det.
Eksempel: Teknikker anvendt til forudsigelig analyse. (Vejrudsigt baseret på identificering af mønstre fra historiedataene)
Lad os forstå den store forskel mellem Data mining og web mining i detaljer i dette indlæg.
analogi
Guld produceres ved processen kaldet guldminedrift. Det ekstraheres og raffineres fra malmen. Det endelige resultat af guldminedrift er det ædelmetal. Ligeledes,
For at få nøgleinformation (data, der er værd) fra en rå kilde, anvendes data mining teknik. Her betragtes det mønster, der blev opdaget fra den rå datakilde, værdifuldt for dataanalytikeren / dataforskerne for at gå videre med de beslutninger, der påvirker forretningsværdien.
Data mining
Kort sagt er datamining et begreb om minedriftviden fra forskellige datasæt. Den udvundne viden bruges yderligere til at give prognoser eller anbefalinger. De data, der skal udvindes, er enten tilgængelige i datalageret eller andre eksterne systemer. Data kan være tilgængelige på forskellige tabeller med deres forskellige adfærd eller attributter. For at identificere mønsteret skal sammenhængen mellem flere datasæt identificeres.
Trin i data mining
Da data mining er et abstrakt, her er listen over involverede trin,
- Forberedelse af data
- Opdagelse af mønster
- Lav modeller til at forudsige / anbefale (for at nævne få tilfælde)
- Resumé af modelværdien
Webmining
Webmining er et abstrakt, da der er tre forskellige typer teknik til minedrift.
- Webindholdsindvinding
- Webstruktur minedrift
- Webbrugsminedrift
Web mining klasser af informationsindsamling 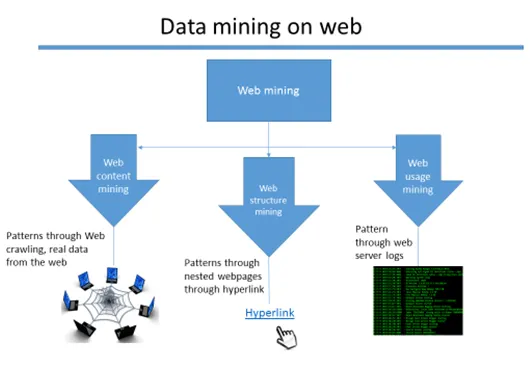
Webindholdsindvinding
Data fra websiderne udvindes for at opdage forskellige mønstre, der giver en betydelig indsigt. Der er mange teknikker til at udtrække data som skrabning af web (for eksempel - skraber og Octoparse er de velkendte værktøjer, der udfører minedriftprocessen for webindhold.
Et af de bedste eksempler - For at gennemføre en begivenhed eller et hvilket som helst program skal organisationen først analysere om lokationerne (hvilket sted der er bedst egnet til at gennemføre programmet, så der er fuld deltagelse). For at udføre disse analyser skal man samle lokalitetsspecifik information om byen, staten og hvor langt begivenheden fra den inviterede befinder sig. Alle lokaliseringsspecifikke data kan udvindes fra Internettet. Det er her, minedrift af webindhold kommer ind i billedet.
Webstruktur minedrift
Data fra hyperlinks, der fører til forskellige sider, er samlet og udarbejdet for at opdage et mønster. For at se en persons offentlige profil fra en blog eller en anden webside, er der chancer for, at de integrerer deres sociale medier. Så dataene udvindes ikke kun fra en enkelt kilde, men også fra de indlejrede sider gennem de hyperlinks, der er knyttet til hver side. Der er forskellige algoritmer til at udføre dette. (Eksempel: PageRank-algoritme)
Webbrugsindvinding:
Når en webapplikation er vært, er der masser af webserverlogfiler, der genereres om applikationens brugerwebaktivitet. Disse logfiler betragtes som en rå data til gengæld meningsfulde data udtrækkes og mønstre identificeres.
For enhver e-handelsvirksomhed, når de ønsker at øge omfanget af forretningen eller tilføje en forbedring for bedre kundeoplevelse, overvåges brugerens webaktivitet gennem applikationslogfilerne, og dataudvinding anvendes til den.
Web mining og data mining er mere eller mindre lignende teknikker, men web mining er alt om analyse på nettet. Data mining er ikke begrænset til internettet. Det er en traditionel proces, der finder sted for enhver dataanalyse.
Når vi taler om dataene fra internettet, er der forskellige data, der kan observeres. Det kan være strukturerede data (databasedata trækkes gennem API, hvis de frigives til offentligheden). Semistrukturerede data - alle webaktivitetsrelaterede eller endda serverlogfiler. Eller endda ustrukturerede data som billeder osv. (Hvis der udføres en analyse på billeder)
Sammenligning fra hoved til hoved mellem datamining mod web-minedrift (Infographics)
Nedenfor er de Top 7 sammenligninger mellem data mining og web mining

Vigtige forskelle mellem datamining mod web-minedrift
Følgende er forskellen mellem Data mining og Web mining er som følger
Web mining og data mining er begge næsten ens når det gælder identificering af mønstre. Men hvor og hvad er forskellen i webmining fra data mining. Hvilken type data og data udvindes hvorfra? Dette er de to ultimative aspekter, der bringer forskellen mellem Data mining og Web mining.
Webmining hører under data mining, men dette er begrænset til webrelaterede data og identificering af mønstre. Data mining er et stort koncept, der involverer flere trin, der starter med at forberede dataene, indtil validering af slutresultaterne, der fører til en beslutningsproces for en organisation.
Data mining vs Web mining Comparision Table
| Grundlag for sammenligning | Data mining | Webmining |
| Koncept | Mønsteridentifikation fra data tilgængelige i ethvert system. | Mønsteridentifikation fra webdata. |
| Anvendelses- / brugssager | Vejrudsigt ved hjælp af historiske vejrrapporter | Datacrawling HITS / PageRank teknikker |
| Hvem gør dette? | Data forskere Dataingeniører | Dataforskere / Dataanalytikere Dataingeniører |
| Behandle | Dataekstraktion -> Opdagelse af mønster -> Udvikle funktionen / løse den (algoritme) | Samme proces, men på nettet ved hjælp af webdokumenter |
| Værktøj | Maskinlæringsalgoritmer | Scrappy, Side rank, Apache-logfiler |
| Hvor markant | Mange organisationer er afhængige af datavidenskabelige resultater til beslutningstagning. | Webrelateret data pull vil påvirke den eksisterende data mining proces. |
| Skills | Datarensningsteknikker, maskinlæringsalgoritmer, statistik, sandsynlighed | Viden om applikationsniveau, Datateknik, statistik, sandsynlighed |
Konklusion - Data mining vs web mining
Enhver minedriftsteknologi med dataene er at opdage viden og hvor godt den kunne bruges til at opnå et bedre resultat. Organisationer, der er opsat på at forbedre deres forretninger og opnå en høj fortjeneste, har brug for mange beslutninger, der skal træffes, baseret på de data, der stort set er tilgængelige i deres systemer, der er genereret i en enorm mængde. Ikke alle data anses for at give viden og indsigt. Hvilke, hvorfor og hvad er de vigtigste spørgsmål, som forskere / dataanalytikere skal tænke på, når de forbereder sig på at identificere mønstrene. I en meget lægmandsperiode er datamining som en proces med at snurde mælken til at fremstille smør.
Anbefalet artikel
Dette har været en guide til Data mining vs Web mining, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Data Mining Vs statistik - Hvilken der er bedre
- 10 Kraftige trin til effektiv planlægning af webdesign
- Data mining vs Machine learning - 10 bedste ting, du skal vide
- Bedste 3 ting at lære om datamining min tekstminedrift
- Værktøjer og teknikker, der bruges i datamineringsprocessen