

Introduktion til dataindvindingsmetoder
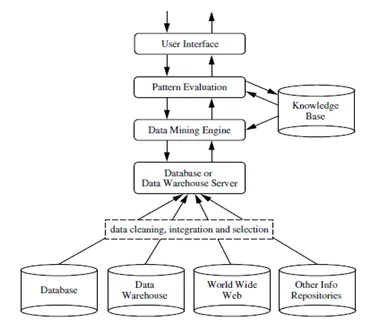
Data stiger dagligt i enorm skala. Men alle indsamlede eller indsamlede data er ikke nyttige. Meningsfulde data skal adskilles fra støjende data (meningsløse data). Denne separationsproces udføres ved data mining.
Hvad er datamining?
Data mining er en proces med at udtrække nyttig information eller viden fra en enorm mængde data (eller big data). Kløften mellem data og information er blevet reduceret ved hjælp af forskellige data mining tools. Data mining kan også kaldes Knowledge discovery fra data eller KDD .
Kilder: - www.ques10.com
Data mining kan udføres på forskellige typer databaser og informationslagre som relationelle databaser, datavarehuse, transaktionsdatabaser, datastrømme og mange flere.
Forskellige dataindvindingsmetoder:
Der er mange metoder, der bruges til Data Mining, men det afgørende trin er at vælge den passende metode blandt dem i henhold til virksomheden eller problemklaringen. Disse dataindvindingsmetoder hjælper med at forudsige fremtiden og derefter tage beslutninger i overensstemmelse hermed. Disse hjælper også med at analysere markedsudviklingen og øge virksomhedens indtægter.
Nogle dataindvindingsmetoder er:
- Association
- Klassifikation
- Clustering-analyse
- Forudsigelse
- Sekventielle mønstre eller mønstersporing
- Beslutningstræer
- Tidligere analyse eller anomalieanalyse
- Neural Network
Lad os forstå alle dataindvindingsmetoder én efter én.
1. Forening:
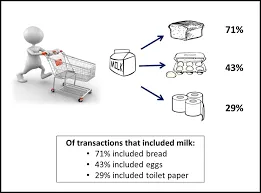
Det er en metode, der bruges til at finde en sammenhæng mellem to eller flere elementer ved at identificere det skjulte mønster i datasættet og dermed også kaldet som relationsanalyse . Denne metode bruges i markedskurveanalyse til at forudsige kundens opførsel.
Antag, at marketingchef i et supermarked ønsker at bestemme, hvilke produkter der ofte købes sammen.
Som et eksempel,
Køber (x, "øl") -> køber (x, "chips") (support = 1%, tillid = 50%)
- Her repræsenterer x en kunde, der køber øl og chips sammen.
- Tillid viser sikkerhed for, at hvis en kunde køber en øl, er der en 50% chance for, at han / hun også køber chips.
- Support betyder, at 1% af alle de analyserede transaktioner viste, at øl og chips blev købt sammen.
Mange lignende eksempler som brød og smør eller computer og software kan overvejes.
Der er to typer associeringsregler:
- Enkeldimensionel associeringsregel: Disse regler indeholder en enkelt attribut, der gentages.
- Multidimensionel associeringsregel: Disse regler indeholder flere attributter, der gentages.
https://bit.ly/2N61gzR
2. Klassificering:
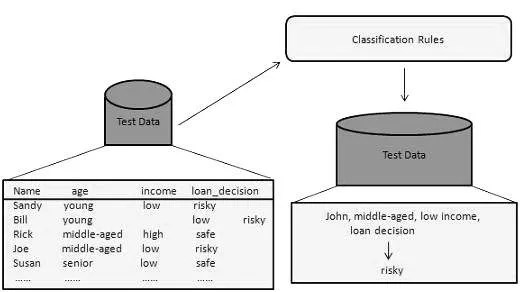
Denne dataindvindingsmetode bruges til at skelne emnerne i datasættet i klasser eller grupper. Det hjælper med at præcist forudsige opførsel af genstande i gruppen. Det er en to-trins proces:
- Læringstrin (træningsfase): I denne bygger en klassificeringsalgoritme klassificeren ved at analysere et træningssæt.
- Klassificeringstrin: Testdata bruges til at estimere nøjagtigheden eller nøjagtigheden af klassificeringsreglerne.
F.eks. Bruger et bankselskab til at identificere låneansøgere med lave, mellemstore eller høje kreditrisici. Tilsvarende analyserer en medicinsk forsker kræftdata for at forudsige hvilken medicin, der skal ordineres til patienten.
Kilder: - www.tutorialspoint.com
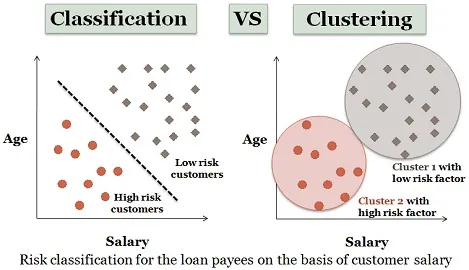
3. Clustering-analyse:
Clustering ligner næsten klassificering, men i denne klynger foretages afhængighed af lighedene mellem dataelementer. Forskellige klynger har forskellige eller ikke-relaterede genstande. Det kaldes også som datasegmentering, da det opdeler store datasæt i klynger i henhold til lighederne.
Der er forskellige klyngemetoder, der bruges:
- Hierarkiske agglomerative metoder
- Netbaserede metoder
- Opdelingsmetoder
- Modelbaserede metoder
- Tæthedsbaserede metoder
Lignende eksempel på låneansøgere kan også overvejes her. Der er nogle forskelle, der er afbildet i figuren herunder.
https://bit.ly/2N6aZpP
4. Forudsigelse:
Denne metode bruges til at forudsige fremtiden baseret på tidligere og nuværende tendenser eller datasæt. Forudsigelse bruges mest med kombinationen af andre dataindvindingsmetoder såsom klassificering, mønster matching, trendanalyse og relation.
For eksempel, hvis salgsdirektøren i et supermarked gerne vil forudsige størrelsen af indtægterne, som hver vare genererer baseret på tidligere salgsdata. Det modellerer kontinuerlig værdsat funktion, der forudser manglende numeriske dataværdier.

Kilder: - data-mining.philippe-fournier
Regressionsanalyse er det bedste valg at udføre forudsigelse. Det kan bruges til at indstille et forhold mellem uafhængige variabler og afhængige variabler.
5. Sekventielle mønstre eller mønstersporing:
Denne dataindvindingsmetode bruges til at identificere mønstre, der ofte forekommer over en bestemt periode.
For eksempel ser salgschef for tøjfirma, at salget af jakker ser ud til at stige lige før vintersæsonen, eller salget i bageri stiger i løbet af jul eller nytårsaften.
Lad os se på et eksempel med en graf
Kilder: - data-mining.philippe-fournier-viger
6. Beslutningstræer:
Et beslutningstræ er en træstruktur (som navnet antyder), hvor
- Hver interne knude repræsenterer en test på attributten.
- Filial angiver resultatet af testen.
- Terminalnoder holder klassemærket.
- Den øverste knude er rodnoden, der har det enkle spørgsmål, der har to eller flere svar. Følgelig vokser træet, og der dannes et rutediagram som en struktur.
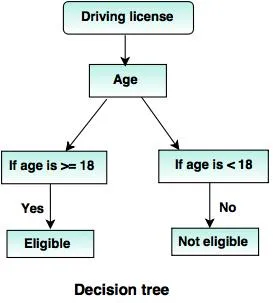
Kilder: - www.tutorialride.com
I denne beslutning klassificerer træregeringen borgere under 18 år eller over 18 år. Dette vil hjælpe dem med at beslutte, om en licens skal udstedes til en bestemt borger eller ej.
7.Oudlier-analyse eller anomali-analyse:
Denne dataindvindingsmetode bruges til at identificere de dataelementer, der ikke overholder det forventede mønster eller den forventede opførsel. Disse uventede dataelementer betragtes som outliers eller støj. De er nyttige på mange domæner som kreditkortbedrageri, detektion af indtrængen, fejldetektering osv. Dette kaldes også for Outlier Mining .
Lad os for eksempel antage, at nedenstående graf er afbildet ved hjælp af nogle datasæt i vores database.
Så den bedste pasform trækkes. De punkter, der ligger i nærheden af linjen, viser forventet opførsel, mens punktet langt fra linjen er en Outlier.
Dette vil hjælpe med at opdage anomalierne og tage mulige handlinger i overensstemmelse hermed.
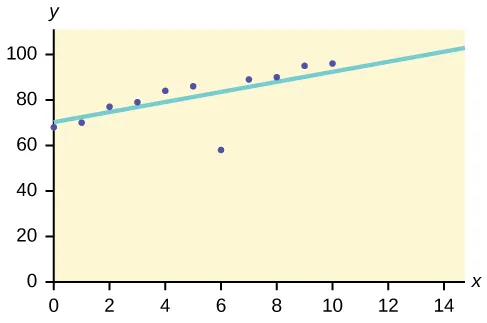
https://bit.ly/2GrgjDP
8. Neural netværk:
Denne dataindvindingsmetode eller -model er baseret på biologiske neurale netværk. Det er en samling af neuroner som behandlingsenheder med vægtede forbindelser mellem dem. De bruges til at modellere forholdet mellem input og output. Det bruges til klassificering, regressionsanalyse, databehandling osv. Denne teknik fungerer på tre søjler-
- Model
- Læringsalgoritme (overvåget eller uden opsyn)
- Aktiveringsfunktion
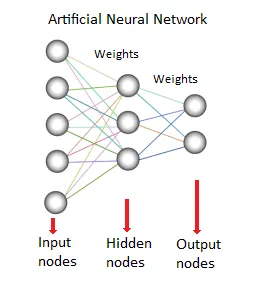
Kilder: - www.saedsayad.com
Anbefalede artikler
Dette har været en vejledning til Data Mining Methods Her har vi drøftet Hvad er Data Mining og forskellige typer Data Mining metode med eksemplet. Du kan også se på de følgende artikler for at lære mere -
- Big Data Analytics-software
- Spørgsmål om datastrukturinterview
- Vigtige dataindvindingsmetoder
- Datamineringsarkitektur