

Introduktion til gnistkommandoer
Apache Spark er en ramme bygget oven på Hadoop til hurtige beregninger. Det udvider konceptet MapReduce i det klyngebaserede scenarie til effektivt at udføre en opgave. Gnistkommando er skrevet i Scala.
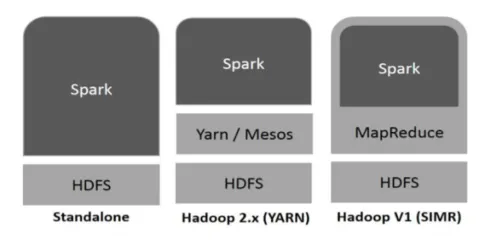
Hadoop kan bruges af Spark på følgende måder (se nedenfor):
Fig
https://www.tutorialspoint.com/
- Standalone: Gnist direkte indsat på toppen af Hadoop. Gnistjob kører parallelt på Hadoop og Spark.
- Hadoop YARN: Spark kører på garn uden behov for nogen forinstallation.
- Spark in MapReduce (SIMR): Spark in MapReduce bruges til at starte gnistjob, ud over selvstændig installation. Med SIMR kan man starte Spark og kan bruge dens shell uden administrativ adgang.
Komponenter i gnist:
- Apache gnistkerne
- Gnist SQL
- Gnist streaming
- MLib
- GraphX
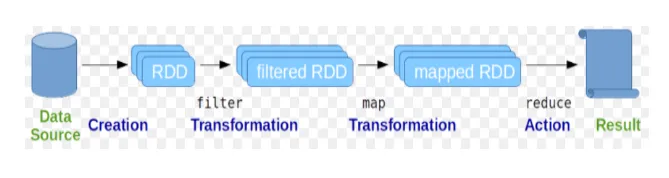
Resilient Distribuerede datasæt (RDD) betragtes som den grundlæggende datastruktur for Spark-kommandoer. RDD er uforanderlig og skrivebeskyttet. Alle former for beregninger i gnistkommandoer udføres gennem transformationer og handlinger på RDD'er.
Fig
Google-billede
Gnisteskal giver et medium for brugere til at interagere med dens funktionaliteter. Gnistkommandoer har en masse forskellige kommandoer, som kan bruges til at behandle data på den interaktive skal.
Grundlæggende gnistkommandoer
Lad os se på nogle af de grundlæggende gnistkommandoer, der er givet nedenfor: -
-
Sådan starter du gnistskallen:

Fig. 3
-
Læs fil fra det lokale system:

Her er "sc" gnistkontekst. I betragtning af “data.txt” findes i hjemmekataloget, læses det sådan, ellers skal man angive den fulde sti.
-
Opret RDD gennem parallelisering

NewData er RDD nu.
-
Tæl varer i RDD

-
Indsamle
Denne funktion returnerer alt RDD's indhold til driverprogrammet. Dette er nyttigt til fejlfinding på forskellige trin i skriveprogrammet.
-
Læs de første 3 artikler fra RDD

-
Gem output / behandlede data i tekstfilen

Her er "output" -mappen den aktuelle sti.
Mellemliggende gnistkommandoer
1. Filtrer på RDD
Lad os oprette ny RDD til elementer, der indeholder “ja”.

Transformation filter skal kaldes på eksisterende RDD for at filtrere på ordet "ja", hvilket vil skabe nyt RDD med den nye liste over varer.
2. Kædedrift

Her handlede filtertransformation og tællehandling sammen. Dette kaldes kædedrift.
3. Læs det første emne fra RDD

4. Tæl RDD-partitioner
Som vi ved, er RDD lavet af flere partitioner, der opstår behovet for at tælle nej. af partitioner. Da det hjælper med tuning og fejlfinding, mens du arbejder med gnistkommandoer.

Som standard er minimum nr. pf-partition er 2.
5. slutte sig til
Denne funktion forbinder to tabeller (tabelelement er parvis) baseret på den fælles nøgle. I parvis RDD er det første element nøglen, og det andet element er værdien.
6. Cache en fil
Cache er en optimeringsteknik. Caching RDD betyder, at RDD bor i hukommelsen, og al fremtidig beregning vil blive udført på disse RDD i hukommelsen. Det sparer disklæstiden og forbedrer forestillingerne. Kort sagt reducerer det tiden for adgang til dataene.

Data cacher imidlertid ikke, hvis du kører over funktionen. Dette kan bevises ved at besøge websiden:
http: // localhost: 4040 / opbevaring
RDD vil blive cache, når handlingen er udført. For eksempel:

En yderligere funktion, der fungerer som cache (), er vedvarende (). Persist giver brugerne fleksibilitet til at give argumentet, hvilket kan hjælpe data, der cache i hukommelse, disk eller off-heap hukommelse. Vedvarer uden noget argument fungerer det samme som cache ().
Avancerede gnistkommandoer
Lad os se på nogle af de avancerede gnistkommandoer, der er givet nedenfor: -
-
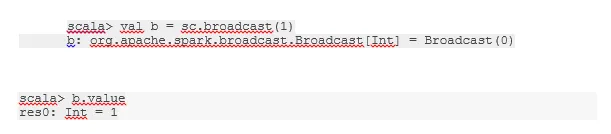
Send en variabel
Broadcast-variabel hjælper programmereren med at læse den eneste variabel, der er cache-cache på hver maskine i klyngen, snarere end at sende kopi af den variabel med opgaver. Dette hjælper med at reducere kommunikationsomkostninger.
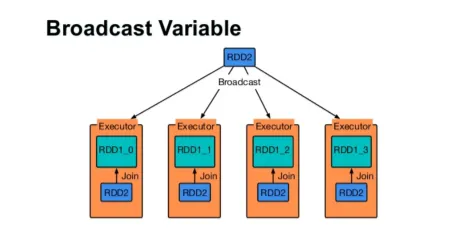
Fig. 4
Google-billede
Kort sagt er der tre hovedfunktioner i den udsendte variabel:
- uforanderlige
- Monter i hukommelsen
- Fordelt over klyngen
-
akkumulatorer
Akkumulatorer er de variabler, der tilføjes til tilknyttede operationer. Der er mange anvendelser til akkumulatorer som tællere, summer osv.

Navnet på akkumulatoren i koden kunne også ses i Spark UI.
-
Kort
Kortfunktion hjælper med at iterere over hver linje i RDD. Funktionen, der bruges på kortet, anvendes til alle elementer i RDD.
For eksempel, i RDD (1, 2, 3, 4, 6), hvis vi anvender “rdd.map (x => x + 2)”, får vi resultatet som (3, 4, 5, 6, 8).
-
Flatmap
Flatmap fungerer som kortet, men kortet returnerer kun et element, mens flatmap kan returnere listen over elementer. Derfor skal opsætning af sætninger i ord kræves flatmap.
-
Flyder sammen
Denne funktion hjælper med at undgå blanding af data. Dette anvendes i den eksisterende partition, så mindre data blandes. På denne måde kan vi begrænse brugen af noder i klyngen.
Tip og tricks til brug af gnistkommandoer
Nedenfor er de forskellige tip og tricks med gnistkommandoer: -
- Begyndere af gnist kan bruge gnistskal. Da gnistkommandoer er bygget på Scala, er det bestemt at bruge scala-gnistskal fantastisk. Imidlertid er python-gnistskal også tilgængelig, så selv at også noget man kan bruge, der er velbevandret med python.
- Gnisteskal har mange muligheder for at styre ressourcerne i klyngen. Nedenfor kommando kan hjælpe dig med det:

- I Spark er det at arbejde med lange datasæt den sædvanlige ting. Men ting går galt, når der tages dårlige input. Det er altid en god ide at slippe dårlige rækker ved hjælp af filterfunktionen til Spark. Det gode sæt input vil være en god chance.
- Spark vælger en egen partition til dine data. Men det er altid en god praksis at holde øje med skillevægge, inden du starter dit job. At prøve forskellige partitioner hjælper dig med parallelismen i dit job.
Konklusion - Gnistkommandoer:
Spark-kommando er en revolutionerende og alsidig big data-maskine, der kan fungere til batch-behandling, realtidsbehandling, cache-data osv. Spark har et rigt sæt Machine Learning-biblioteker, der kan gøre det muligt for dataforskere og analytiske organisationer at opbygge stærke, interaktive og hurtige applikationer.
Anbefalede artikler
Dette har været en guide til gnistkommandoer. Her har vi drøftet både grundlæggende såvel som avancerede gnistkommandoer og nogle øjeblikkelige gnistkommandoer. Du kan også se på den følgende artikel for at lære mere -
- Adobe Photoshop-kommandoer
- Vigtige VBA-kommandoer
- Tableau-kommandoer
- Snyd ark SQL (kommandoer, gratis tip og tricks)
- Typer af sammenføjninger i Spark SQL (eksempler)
- Gnistkomponenter | Oversigt og top 6-komponenter