

Splunk Interview Spørgsmål og svar - Introduktion
Så du har endelig fundet dit drømmejob i Splunk, men spekulerer på, hvordan du sprækker Splunk-interviewet, og hvad der kan være de sandsynlige Splunk-interviewspørgsmål for 2018. Hvert interview er anderledes, og omfanget af et job er også anderledes. Med dette i tankerne har vi designet de mest almindelige Splunk Interview Spørgsmål og svar for 2018 for at hjælpe dig med at få succes i dit interview.Nedenfor er de mest nyttige Splunk Interview Spørgsmål og svar. Disse topspørgsmål er opdelt i to dele er som følger:
Del 1 - Splunk Interview Spørgsmål (Grundlæggende)
Denne første del dækker grundlæggende Splunk Interview Spørgsmål og svar.
1. Hvad er Splunk? Hvorfor bruges Splunk til analyse af maskindata?
Svar:
Et af de mest anvendte analyseværktøjer derude er Microsoft Excel, og ulempen med det er, at Excel kun kan indlæse op til 1048576 rækker, og maskindataene er generelt enorme. Splunk er praktisk ved håndtering af maskingenererede data (big data), dataene fra servere, enheder eller netværk kan nemt indlæses i Splunk og kan analyseres for at kontrollere for eventuel trusselsynlighed, overholdelse, sikkerhed osv. Det kan også bruges til applikationsovervågning.
2. Forklar, hvordan Splunk fungerer
Svar:
Dette er de almindelige Splunk-interviewspørgsmål, der stilles i et interview. Data indlæses i Splunk ved hjælp af forwarderen, der fungerer som en grænseflade mellem Splunk-miljøet og omverdenen, derefter videresendes disse data til en indekser, hvor dataene enten gemmes lokalt eller på en sky. Indeksøren indekserer maskinens data og gemmer dem på serveren. Search Head er den GUI, der leveres af Splunk til søgning og analyse (søger, visualiserer, analyserer og udfører forskellige andre funktioner) dataene.
Deployeringsserver administrerer alle komponenter i Splunk som indexer, speditør og søgehoved i Splunk miljø. 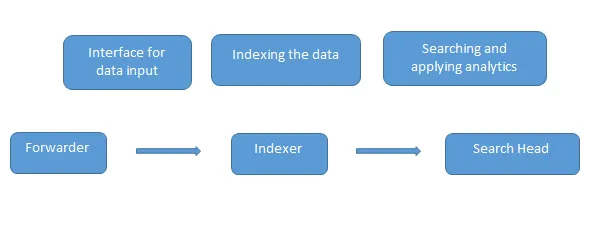
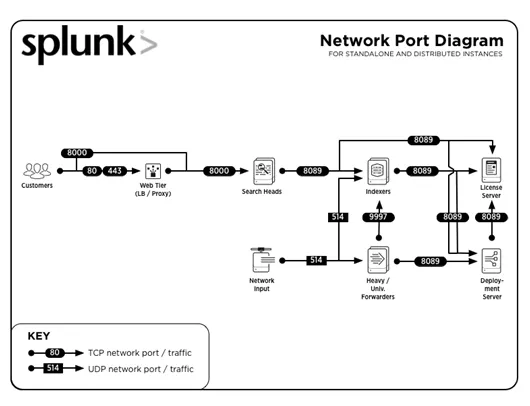
3. Hvad er almindelige portnumre brugt af Splunk?
Svar :
Almindelige portnumre, som tjenester køres på (som standard) er:
| Service | Portnummer |
| Management / REST API | 8089 |
| Søgehoved / indekser | 8000 |
| Søg hoved | 8065, 8191 |
| Indexer klynge peer node / Search head cluster medlem | 9887 |
| Indexer | 9997 |
| Indexer / Forwarder | 514 |
Lad os gå til de næste Splunk-interviewspørgsmål.
4. Hvorfor kun bruge Splunk?
Svar:
Der er mange alternativer til Splunk, der giver meget konkurrence for det, nogle af dem er som nedenfor:
• ELK / Logstash (open source)
Elasticsearch bruges til at søge, det er som søgehovedet i Splunk, Log stash er til dataindsamling, der ligner den speditør, der bruges i Splunk, og Kibana bruges til datavisualisering (søgehoved gør det samme i Splunk)
• Graylog (open source med kommerciel version)
Graylog er endnu et værktøj, der blev navngivet sidste år med udgivelsen 1.0. I lighed med ELK-stakken har Graylog også forskellige komponenter, den bruger Elasticsearch som sin kernekomponent, men dataene gemmes i Mongo DB og bruger Apache Kafka. Det har to versioner, en kerneversion, der er tilgængelig gratis og virksomhedsversionen, der leveres med funktioner som arkivering.
• Sumo Logic (skytjeneste)
Så hvad der gør Splunk bedst blandt alle, er at Splunk kommer som en enkelt pakke med dataindsamleren, opbevaring såvel som det indbyggede analyseværktøj. Splunk er også skalerbar og yder support / professionel hjælp til sin virksomhedsudgave.
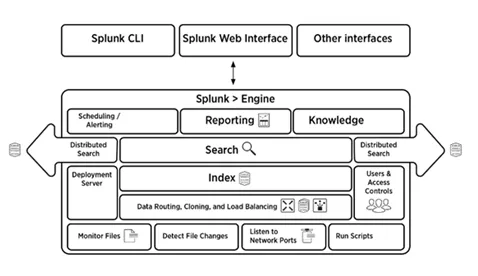
5. Forklar kort fortalt Splunk-arkitekturen
Svar:
Nedenstående billede giver en kort oversigt over Splunk-arkitekturen og dens komponenter.
Del 2 - Splunkede interviewspørgsmål (Avanceret)
Lad os nu se på de avancerede Splunk-interviewspørgsmål.
6. Hvad er komponenterne i Splunk-arkitektur?
Svar:
Der er fire komponenter i Splunk-arkitekturen. De er:
- Indekser : Indekserer maskindata
- Speditør: Videresend logger til indeks
- Søgehoved: Giver GUI til søgning
- Distributionsserver: Administrerer Splunk-komponenter (indekser, speditør og søgehoved) i et distribueret miljø
7. Giv et par brugstilfælde af videnobjekter.
Svar :
Dette er de ofte stillede Splunk-interviewspørgsmål i et interview. Videnobjekter kan bruges i mange domæner. Få eksempler er:
Applikationsovervågning: Dette kan bruges til at overvåge applikationer i realtid med konfigurerede alarmer, som vil underrette administratorerne / brugerne, når et program går ned.
Fysisk sikkerhed: I tilfælde af oversvømmelse / vulkan osv. Kan dataene bruges til at få indsigt, hvis din organisation har at gøre med sådanne data.
Netværkssikkerhed: Du kan oprette et sikkert miljø ved at sortliste IP'en af ukendte enheder og derved reducere datalækager i enhver organisation.
Medarbejderledelse: Medarbejderudslip er en af de udfordringer, som enhver organisation står overfor, og i løbet af opsigelsesperioden kan medarbejderens aktivitet spores for at beskytte organisationens data og derved overvåge deres aktivitet og begrænse enhver anden medarbejder i opsigelsesperioden til ikke at gøre det samme .
8.Explain Search Factor (SF) & Replication Factor (RF)
Svar:
Dette er de terminologier, der bruges i Splunk-klyngeteknikker. Indexer cluster er en specielt konfigureret gruppe af Splunk Enterprise-indeksere, der replikerer eksterne data og bruges til katastrofegendannelse.
Med hensyn til Splunk-dokumentationssøgning kan faktoren beskrives som “Antallet af søgbare kopier af data, som en indekserklynge opretholder. Standardværdien af søgefaktor er 2 ”, mens replikationsfaktoren er defineret som antallet af kopier af data, som klyngen opretholder.
Indexer-klyngen har både en søgefaktor og en replikationsfaktor, mens søgehovedklyngen kun har en søgefaktor
Lad os gå til de næste Splunk-interviewspørgsmål.
9. Hvad er Splunk spande? Forklar spandens livscyklus.
Svar:
De mapper, hvor de indekserede data er gemt, kaldes Splunk-spande, og disse har begivenheder i den bestemte periode. Livscyklus for Splunk spand inkluderer fire trin varme, varme, kolde, frosne og optøede.
- Hot - Denne spand indeholder de nyligt indekserede data og er åben til skrivning.
- Varm - Når dataene er faldet i varm spand afhængigt af dine datapolitikker, flyttes de til varme spande
- Kold - Det næste trin efter varm er det kolde trin, hvor dataene ikke kan redigeres.
- Frozen - Som standard sletter indeksøren dataene fra frosne spande, men disse kan også arkiveres.
- Optøet - Indhentning af information fra arkiverede filer (frosset spand) kaldes optøning.
10. Hvorfor skal vi bruge Splunk Alert? Hvad er de forskellige indstillinger, mens du indstiller advarsler?
Svar:
At være opmærksom på enhver mulig fejl er kendt som alarm, og i Splunk kan miljøalarmer opstå på grund af eventuelle forbindelsesfejl eller sikkerhedsovertrædelser eller brud på eventuelle brugeroprettede regler.
For eksempel at sende underretninger eller en rapport fra de brugere, der ikke har logget ind efter at have anvendt deres tre forsøg i en portal til applikationsadministratoren.
Forskellige muligheder, der er tilgængelige under opsætning af advarsler, er:
- En webhook kan oprettes for at skrive alarmerne til hipchat eller GitHub.
- Tilføj resultater, .csv eller pdf eller i tråd med meddelelsens krop, så rodens årsag til alarmen kan identificeres.
- Billetter kan oprettes, og alarmer kan udløses fra en maskine eller en IP.
Anbefalet artikel
Dette har været en guide til Liste over Splunk Interview Spørgsmål og svar, så kandidaten let kan nedbryde disse Splunk Interview Spørgsmål og svar. Du kan også se på følgende artikel for at lære mere -
- SAS System Interview Interview - Top 10 nyttige spørgsmål
- 10 fremragende Tableau-interviewspørgsmål, du skal vide
- 15 mest succesrige Oracle-interviewspørgsmål og svar
- Spørgsmål om netværkssikkerhedsinterview - Top og mest stillede
- Splunk vs Nagios