
Introduktion til grafer i R
En graf er et værktøj, der gør en væsentlig forskel for analysen. Grafer i sjældne vigtige, da de hjælper med at præsentere resultater på den mest interaktive måde. R, som en statistisk programmeringspakke, tilbyder omfattende muligheder for at generere en række grafer.
Nogle af graferne i R er tilgængelige i basisinstallationen, men andre kan bruges ved at installere nødvendige pakker. Det unikke ved grafer i R er, at de forklarer indviklede statistiske fund gennem visualiseringer. Så det er i det væsentlige som at bevæge et trin over den traditionelle måde at visualisere dataene på. R tilbyder således en out-of-the-box tilgang til drevanalyse.
Typer af grafer i R
En række forskellige grafer er tilgængelig i R, og brugen styres udelukkende af sammenhængen. Undersøgelsesanalyse kræver dog anvendelse af visse grafer i R, som skal bruges til analyse af data. Vi skal nu undersøge nogle af sådanne vigtige grafer i R.
Til demonstration af forskellige diagrammer vil vi bruge "træerne" datasættet, der er tilgængeligt i basisinstallationen. Flere detaljer om datasættet kan opdages ved hjælp af? træer kommandoer i R.
1. Histogram
Et histogram er et grafisk værktøj, der fungerer på en enkelt variabel. Talrige variable værdier er grupperet i bins, og et antal værdier, der kaldes som hyppigheden, beregnes. Denne beregning bruges derefter til at plotte frekvensbjælker i de respektive bønner. Højden på en bjælke er repræsenteret ved frekvens.
I R kan vi bruge hist () -funktionen som vist nedenfor for at generere histogrammet. Et simpelt histogram over træhøjder er vist nedenfor.
Kode:
hist(trees$Height, breaks = 10, col = "orange", main = "Histogram of Tree heights", xlab = "Height Bin")
Produktion:

For at forstå frekvensudviklingen kan vi tilføje et tætheds plot over ovenstående histogram. Dette giver mere indsigt i datadistribution, skævhed, kurtose osv. Følgende kode gør dette, og output vises efter koden.
Kode:
hist(trees$Height, breaks = 10, col = "orange",
+ main = "Histogram of Tree heights with Kernal Denisty plot",
+ xlab = "Height Bin", prob = TRUE)
Produktion:

2. Scatterplot
Dette plot er en simpel korttype, men meget afgørende, der har enorm betydning. Diagrammet giver ideen om en sammenhæng mellem variabler og er et praktisk værktøj i en sonderende analyse.
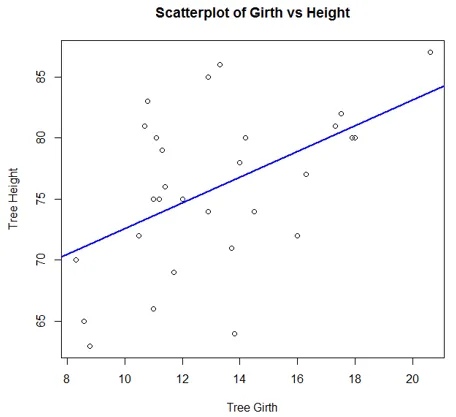
Følgende kode genererer et simpelt Scatterplot-diagram. Vi har tilføjet en trendlinje til det, for at forstå tendensen repræsenterer dataene.
Kode:
attach(trees)
plot(Girth, Height, main = "Scatterplot of Girth vs Height", xlab = "Tree Girth", ylab = "Tree Height")
abline(lm(Height ~ Girth), col = "blue", lwd = 2)
Produktion:
Diagrammet oprettet med følgende kode viser, at der findes en god sammenhæng mellem træomkrets og trævolumen.
Kode:
plot(Girth, Volume, main = "Scatterplot of Girth vs Volume", xlab = "Tree Girth", ylab = "Tree Volume")
abline(lm(Volume ~ Girth), col = "blue", lwd = 2)
Produktion:

Scatterplot Matrix
R giver os mulighed for at sammenligne flere variabler ad gangen på grund af at de bruger scatterplot-matrixer. Implementeringen af visualiseringen er ganske enkel og kan opnås ved hjælp af funktionen par () som vist nedenfor.
Kode:
pairs(trees, main = "Scatterplot matrix for trees dataset")
Produktion:

Scatterplot3d
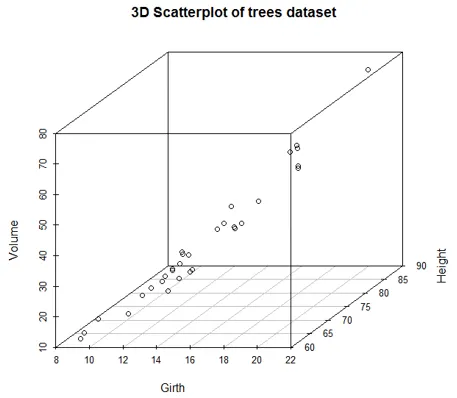
De muliggør visualisering i tre dimensioner, som kan hjælpe med at forstå forholdet mellem flere variabler. Så for at gøre scatterplots tilgængelig i 3d, skal for det første scatterplot3d-pakken installeres. Så genererer følgende kode en 3d graf som vist under koden.
Kode:
library(scatterplot3d)
attach(trees)
scatterplot3d(Girth, Height, Volume, main = "3D Scatterplot of trees dataset")
Produktion:
Vi kan tilføje droplinjer og farver ved hjælp af nedenstående kode. Nu kan vi nemt skelne mellem forskellige variabler.
Kode:
scatterplot3d(Girth, Height, Volume, pch = 20, highlight.3d = TRUE,
+ type = "h", main = "3D Scatterplot of trees dataset")
Produktion:

3. Boxplot
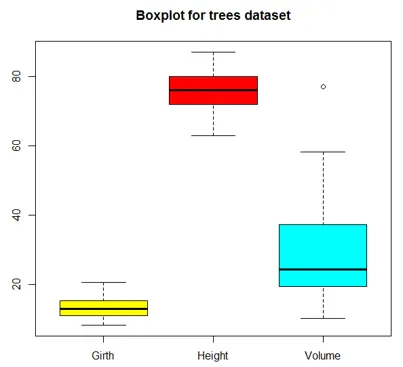
Boxplot er en måde at visualisere data gennem bokse og whiskers. For det første sorteres variable værdier i stigende rækkefølge, og derefter opdeles dataene i kvartaler.
Boksen i plottet er de midterste 50% af dataene, kendt som IQR. Den sorte linje i boksen repræsenterer medianen.
Kode:
boxplot(trees, col = c("yellow", "red", "cyan"), main = "Boxplot for trees dataset")
Produktion:
En variant af kasseplottet med hak er som vist nedenfor.
Kode:
boxplot(trees, col = "orange", notch = TRUE, main = "Boxplot for trees dataset")
Produktion:

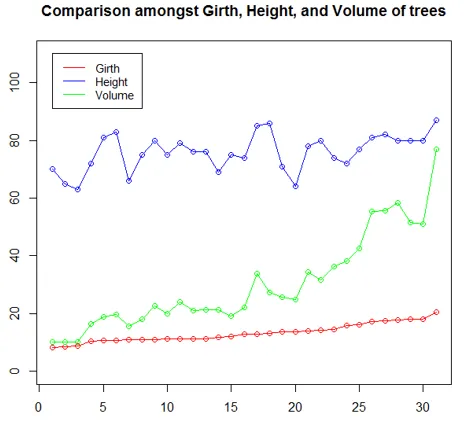
4. Linjediagram
Linjediagrammer er nyttige, når man sammenligner flere variabler. De hjælper os med forholdet mellem flere variabler i et enkelt plot. I den følgende illustration vil vi forsøge at forstå tendensen med tre træfunktioner. Så som vist i nedenstående kode oprindeligt, og linjediagrammet for Omkransning er afbildet ved hjælp af funktionen plot (). Derefter plottes linjediagrammer for Højde og lydstyrke på det samme plot ved hjælp af linjefunktionen.
"Ylim" -parameteren i plot () -funktionen har været, for at imødekomme alle tre linjediagrammer korrekt. At have legende er vigtigt her, da det hjælper med at forstå, hvilken linje repræsenterer hvilken variabel. I legenden betyder "lty = 1: 1" -parameter, at vi har den samme linjetype for alle variabler, og "cex" repræsenterer størrelsen på punkterne.
Kode:
plot(Girth, type = "o", col = "red", ylab = "", ylim = c(0, 110),
+ main = "Comparison amongst Girth, Height, and Volume of trees")
lines(Height, type = "o", col = "blue")
lines(Volume, type = "o", col = "green")
legend(1, 110, legend = c("Girth", "Height", "Volume"),
+ col = c("red", "blue", "green"), lty = 1:1, cex = 0.9)
Produktion:
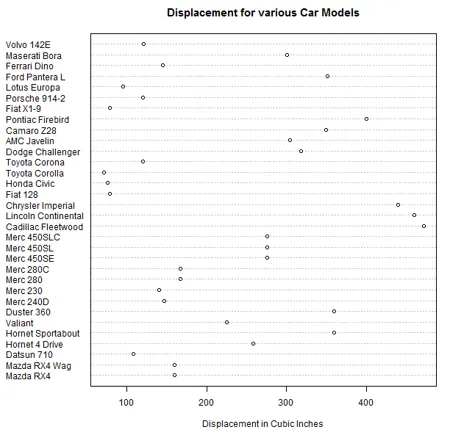
5. Dot plot
Dette visualiseringsværktøj er nyttigt, hvis vi vil sammenligne flere kategorier med en bestemt foranstaltning. Til nedenstående illustration er mtcars datasæt brugt. Funktionen dotchart () viser forskydningen for forskellige bilmodeller som nedenfor.
Kode:
attach(mtcars)
dotchart(disp, labels = row.names(mtcars), cex = 0.75,
+ main = "Displacement for various Car Models", xlab = "Displacement in Cubic Inches")
Produktion:
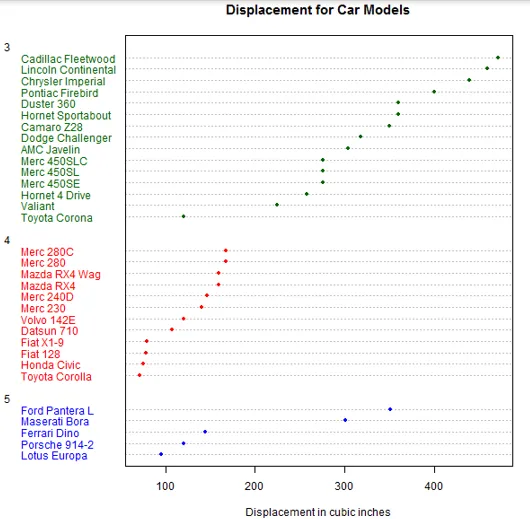
Så nu sorterer vi datasættet på forskydningsværdier og derefter plot dem med forskellige gear ved hjælp af dotchart () -funktionen.
Kode:
m <- mtcars(order(mtcars$disp), ) m$gear <- factor(m$gear)
m$color(m$gear == 3) <- "darkgreen"
m$color(m$gear == 4) <- "red"
m$color(m$gear == 5) <- "blue"
dotchart(m$disp, labels = row.names(m), groups = m$gear, color = m$color, cex = 0.75, pch = 20,
+ main = "Displacement for Car Models", xlab = "Displacement in cubic inches")
Produktion:
Konklusion
Analytics i ægte forstand er kun udnyttet gennem visualiseringer. R, som et statistisk værktøj, tilbyder stærke visualiseringsfunktioner. Så de mange muligheder, der er forbundet med diagrammer, er det, der gør dem specielle. Hvert af diagrammerne har sin egen anvendelse, og kortet skal studeres, inden det anvendes til et problem.
Anbefalede artikler
Dette er en vejledning til grafer i R. Her diskuterer vi introduktion og typer af grafer i R såsom histogram, scatterplot, boxplot og meget mere sammen med eksempler og implementering. Du kan også se på de følgende artikler for at lære mere -
- R Datatyper
- R-pakker
- Introduktion til Matlab
- Grafer vs diagrammer