

Introduktion til datavidenskabsteknikker
I dagens verden, hvor data er det nye guld, er der forskellige slags analyser tilgængelige for en virksomhed at gøre. Resultatet af et datavidensprojekt varierer meget med typen af tilgængelige data, og konsekvensen er derfor også en variabel. Da der er mange forskellige slags analyser til rådighed, bliver det bydende nødvendigt at forstå, hvad der er nødvendigt at vælge nogle få baseline-teknikker. Det grundlæggende mål med datavidsteknikker er ikke kun at søge efter relevant information, men også opdage svage links, der har tendens til at få modellen til at fungere dårligt.
Hvad er datavidenskab?
Datavidenskab er et felt, der spreder sig over flere discipliner. Det inkorporerer videnskabelige metoder, processer, algoritmer og systemer til at indsamle viden og arbejde på det samme. Dette felt inkluderer en række forskellige genrer og er en fælles platform for forening af begreber inden for statistik, dataanalyse og maskinlæring. I dette arbejder den teoretiske viden om statistik sammen med data i realtid og teknikker i maskinlæring hånd i hånd for at opnå frugtbare resultater for virksomheden. Ved hjælp af forskellige teknikker, der anvendes inden for datavidenskab, kan vi i nutidens verden antyde bedre beslutningstagning, som ellers kan gå glip af det menneskelige øje og sind. Husk, at maskinen aldrig glemmer! For at maksimere profit i en datadrevet verden er magien med Data Science et nødvendigt værktøj at have.
Forskellige typer datavidsteknik
I de følgende par afsnit undersøger vi almindelige datavidenskabelige teknikker, der bruges i hvert andet projekt. Selvom datateknikkerne undertiden kan være forretningsproblemspecifikke og måske ikke falder i nedenstående kategorier, er det helt okay at betegne dem som diverse typer. På et højt niveau opdeler vi teknikkerne i Overvåget (vi kender målpåvirkning) og Uovervåget (Vi ved ikke om den målvariabel, vi prøver at opnå). I det næste niveau kan teknikkerne opdeles i form af
- Det output, vi ville få, eller hvad er hensigten med forretningsproblemet
- Type af anvendte data.
Lad os først se på adskillelse baseret på forsæt.
1. Uovervåget læring
- Anomali-detektion
I denne type teknik identificerer vi enhver uventet forekomst i hele datasættet. Da adfærden adskiller sig fra den faktiske forekomst af data, er de underliggende antagelser:
- Forekomsten af disse tilfælde er meget lille i antal.
- Forskellen i adfærd er betydelig.
Anomali algoritmer forklares, såsom Isolationsskoven, som giver en score for hver post i et datasæt. Denne algoritme er en træbaseret model. Ved hjælp af denne type detekteringsteknik og dens popularitet bruges de i forskellige forretningssager, for eksempel websidevisninger, Churn Rate, Indtjening pr. Klik osv. I nedenstående graf kan vi forklare, hvordan anomali ser ud.
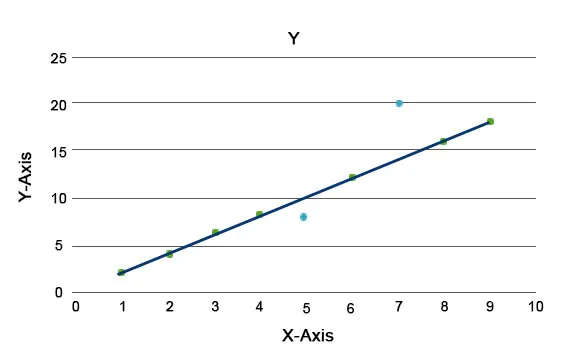
Her repræsenterer dem i blåt en anomali i datasættet. De varierer fra den almindelige trendlinje og forekommer mindre.
- Clustering-analyse
Gennem denne analyse er hovedopgaven at adskille hele datasættet i grupper, så tendensen eller trækkene i et gruppedatapunkter ligner hinanden. I datavidenskabets terminologi kalder vi disse som klyngen. For eksempel i detailhandelen er der en plan for at skalere virksomheden, og det bliver bydende nødvendigt at vide, hvordan de nye kunder vil opføre sig i en ny region baseret på de tidligere data, vi har. Det bliver umuligt at udtænke en strategi for hvert individ i en befolkning, men det vil være nyttigt at skabe befolkningen i klynger, så strategien vil være effektiv i en gruppe og er skalerbar.
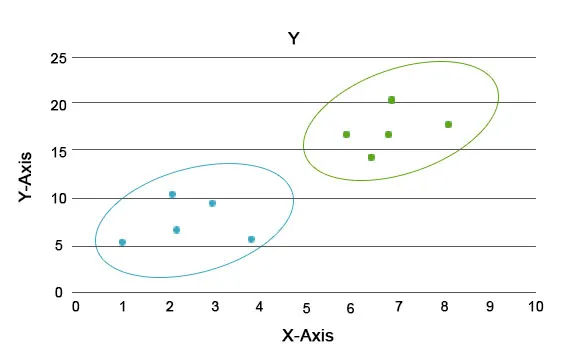
Her er de blå og orange farver forskellige klynger med unikke træk i sig selv.
- Associeringsanalyse
Denne analyse hjælper os med at opbygge interessante forhold mellem elementer i et datasæt. Denne analyse afslører skjulte forhold og hjælper med at repræsentere datasæt-poster i form af tilknytningsregler eller sæt af hyppige genstande. Associeringsreglen er opdelt i 2 trin:
- Generering af hyppigt artikelsæt: I dette genereres et sæt, hvor ofte forekommende elementer sættes sammen.
- Regelgenerering: Sættet, der er bygget ovenfor, føres gennem forskellige lag af regeldannelse for at opbygge et skjult forhold mellem hinanden. For eksempel kan sættet falde i enten konceptuelle eller implementeringsspørgsmål eller applikationsproblemer. Disse er derefter forgrenet i respektive træer for at opbygge associeringsreglerne.
F.eks. Er APRIORI en associeringsregelopbygningsalgoritme.
2. Overvåget læring
- Regressions analyse
I regressionsanalyse definerer vi den afhængige / målvariabel og de resterende variabler som uafhængige variabler og antyder til sidst, hvordan en / flere uafhængige variabler påvirker målvariablen. Regressionen med en uafhængig variabel kaldes univariat og med mere end én kaldes multivariat. Lad os forstå, hvordan man bruger univariat og derefter skalerer til multivariat.
For eksempel er y målvariablen og x 1 er den uafhængige variabel. Så fra viden om den rette linje kan vi skrive ligningen som y = mx 1 + c. Her bestemmer “m”, hvor stærkt y påvirkes af x 1 . Hvis “m” er meget tæt på nul, betyder det, at med en ændring i x 1, påvirkes y ikke kraftigt. Med et tal over 1, bliver virkningen stærkere, og små ændringer i x 1 fører til stor variation i y. I lighed med univariat kan i multivariat skrives som y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Her bestemmes virkningen af hver uafhængig variabel af dens tilsvarende “m”.
- Klassificeringsanalyse
I lighed med klyngeanalyse er klassificeringsalgoritmer bygget med målvariablen i form af klasser. Forskellen mellem klynge og klassificering ligger i det faktum, at vi i klynge ikke ved, hvilken gruppe datapunkterne falder i, mens vi i klassificeringen ved, hvilken gruppe det hører til. Og det adskiller sig fra regression fra perspektivet, at antallet af grupper skal være et fast antal i modsætning til regression, det er kontinuerligt. Der er en række algoritmer i klassificeringsanalyse, for eksempel supportvektormaskiner, logistisk regression, beslutningstræer osv.
Konklusion
Afslutningsvis forstår vi, at hver type analyse er enorm i sig selv, men her kan vi give en lille smag til forskellige teknikker. I de næste par noter ville vi tage hver af dem separat og gå i detaljer om forskellige underteknikker anvendt i hver forældremetode.
Anbefalet artikel
Dette er en guide til datavidenskabsteknikker. Her diskuterer vi introduktionen og forskellige typer teknikker inden for datavidenskab. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Data Science værktøjer | Top 12 værktøjer
- Data Science algoritmer med typer
- Introduktion til Data Science Karriere
- Data Science vs Data Visualization
- Eksempler på multivariat regression
- Opret beslutningstræ med fordele
- Kort oversigt over Data Science livscyklus