
Introduktion til Data Science livscyklus
Data Science Livscyklus drejer sig om at bruge maskinlæring og andre analysemetoder til at producere indsigt og forudsigelser fra data for at nå et forretningsmæssigt mål. Hele processen involverer flere trin som datarensning, klargøring, modellering, modelevaluering osv. Det er en lang proces og kan tage flere måneder at gennemføre. Så det er meget vigtigt at have en generel struktur, der skal følges for ethvert problem. Den globalt anerkendte struktur til løsning af ethvert analytisk problem kaldes som Cross Industry Standard Process for Data Mining eller CRISP-DM framework.
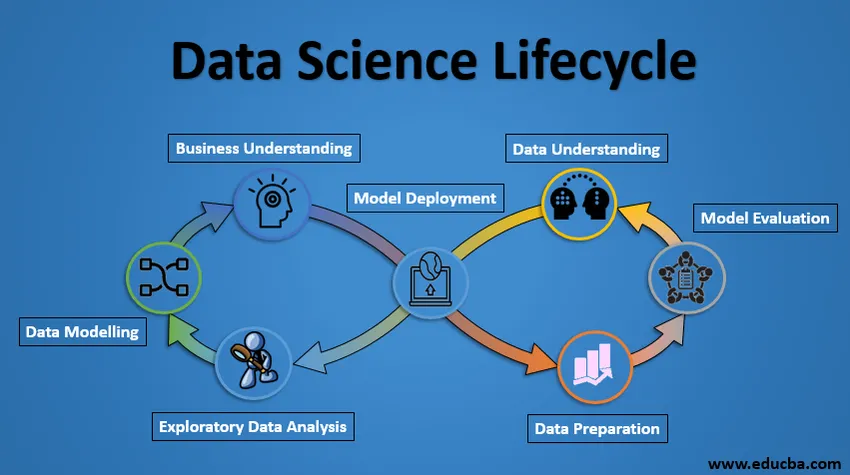
Livscyklus for datavidenskab
Nedenfor er projektets livscyklus for datavidenskab.
1. Forretningsforståelse
Hele cyklus drejer sig om forretningsmålet. Hvad vil du løse, hvis du ikke har et præcist problem? Det er ekstremt vigtigt at forstå forretningsmålet klart, fordi det er dit endelige mål for analysen. Efter korrekt forståelse kan vi kun sætte det specifikke mål for analyse, der er synkroniseret med forretningsmålet. Du skal vide, om klienten ønsker at reducere kredittab, eller om de vil forudsige prisen på en vare osv.
2. Forståelse af data
Efter forretningsforståelse er det næste trin dataforståelse. Dette indebærer indsamling af alle de tilgængelige data. Her skal du arbejde tæt sammen med forretningsteamet, da de faktisk er opmærksomme på, hvilke data der er til stede, hvilke data der kan bruges til dette forretningsproblem og anden information. Dette trin involverer at beskrive dataene, deres struktur, deres relevans, deres datatype. Udforsk dataene ved hjælp af grafiske diagrammer. Grundlæggende at udtrække alle oplysninger, du kan få om dataene, ved blot at udforske dataene.
3. Forberedelse af data
Dernæst kommer dataforberedelsestrinnet. Dette inkluderer trin som at vælge de relevante data, integrere dataene ved at flette datasættene, rense dem, behandle de manglende værdier ved enten at fjerne dem eller beregne dem, behandle forkerte data ved at fjerne dem, også kontrollere for outliers ved hjælp af bokseplaner og håndtere dem . Konstruktion af nye data, hent nye funktioner fra eksisterende. Formater dataene i den ønskede struktur, fjern uønskede kolonner og funktioner. Dataforberedelse er det mest tidskrævende, men alligevel det vigtigste trin i hele livscyklussen. Din model vil være så god som dine data.
4. Undersøgende dataanalyse
Dette trin involverer at få en idé om løsningen og faktorer, der påvirker den, inden man bygger den faktiske model. Distribution af data inden for forskellige variabler af en funktion udforskes grafisk ved hjælp af søjlediagrammer. Forholdet mellem forskellige funktioner er fanget gennem grafiske repræsentationer som scatterdiagrammer og varmekort. Mange andre datavisualiseringsteknikker bruges i vid udstrækning til at udforske hver funktion individuelt og ved at kombinere dem med andre funktioner.
5. Datamodellering
Datamodellering er hjertet i dataanalyse. En model tager de forberedte data som input og leverer den ønskede output. Dette trin inkluderer valg af den passende type model, uanset om problemet er et klassificeringsproblem, et regressionsproblem eller et klyngeproblem. Når vi har valgt modelfamilien blandt de forskellige algoritmer blandt denne familie, er vi nødt til omhyggeligt at vælge algoritmerne til at implementere og implementere dem. Vi er nødt til at indstille hyperparametre for hver model for at opnå den ønskede ydelse. Vi er også nødt til at sikre, at der er en korrekt balance mellem ydeevne og generaliserbarhed. Vi ønsker ikke, at modellen skal lære dataene og fungere dårligt på nye data.
6. Modelevaluering
Her evalueres modellen for at kontrollere, om den er klar til at blive implementeret. Modellen testes på usete data, evalueres på et nøje gennemtænkt sæt evalueringsmetrics. Vi er også nødt til at sikre, at modellen er i overensstemmelse med virkeligheden. Hvis vi ikke opnår et tilfredsstillende resultat i evalueringen, skal vi gentage hele modelleringsprocessen, indtil det ønskede niveau af målinger er nået. Enhver datavidenskabelig løsning, en maskinlæringsmodel, ligesom et menneske, bør udvikle sig, skal kunne forbedre sig selv med nye data og tilpasse sig en ny evalueringsmetrik. Vi kan bygge flere modeller til et bestemt fænomen, men mange af dem kan være ufuldkommen. Modelevaluering hjælper os med at vælge og opbygge en perfekt model.
7. Model Deployment
Modellen efter en streng evaluering implementeres endelig i det ønskede format og kanal. Dette er det sidste trin i datavidens livscyklus. Hvert trin i den ovenfor beskrevne datavidens livscyklus skal arbejdes nøje. Hvis et trin udføres forkert, vil det følgelig påvirke det næste trin, og hele indsatsen går til spilde. Hvis data for eksempel ikke indsamles korrekt, mister du information, og du bygger ikke en perfekt model. Hvis data ikke renses ordentligt, fungerer modellen ikke. Hvis modellen ikke evalueres korrekt, vil den mislykkes i den virkelige verden. Helt fra forretningsforståelse til modelinstallation skal hvert trin gives ordentlig opmærksomhed, tid og kræfter.
Anbefalede artikler
Dette er en guide til Data Science livscyklus. Her diskuterer vi en oversigt over Data Science Livscyklus og trinene, der udgør en data science livscyklus. Du kan også gennemgå vores relaterede artikler for at lære mere -
- Introduktion til Data Science Algorithms
- Data Science vs Software Engineering | Top 8 nyttige sammenligninger
- Forskelstyper af datavidenskabsteknikker
- Data Science Færdigheder med typer