

Oversigt over Data Mining Architecture
Datamining er måden at finde og udforske de basale eller avancerede mønstre i et kompliceret sæt store datasæt, der involverer de metoder, der er placeret i skæringspunktet mellem statistik, maskinlæring og også databasesystemer. Det kan siges at være et tværfagligt felt inden for statistik og computervidenskab, hvor målet er at udtrække informationen ved hjælp af intelligente metoder og teknikker fra et bestemt datasæt ved hjælp af ekstraktion og derved transformere dataene. Datahåndteringsaktiviteter og databehandlingsaktiviteter sammen med inferensovervejelser tages også med i betragtning. I denne artikel vil vi dykke dybt ind i arkitekturen for data mining.
Datamineringsarkitektur
Datamining er teknikken for at udtrække interessant viden fra et sæt enorme mængder data, som derefter gemmes i mange datakilder såsom filsystemer, datalager, databaser. De primære komponenter i data mining-arkitekturen involverer -
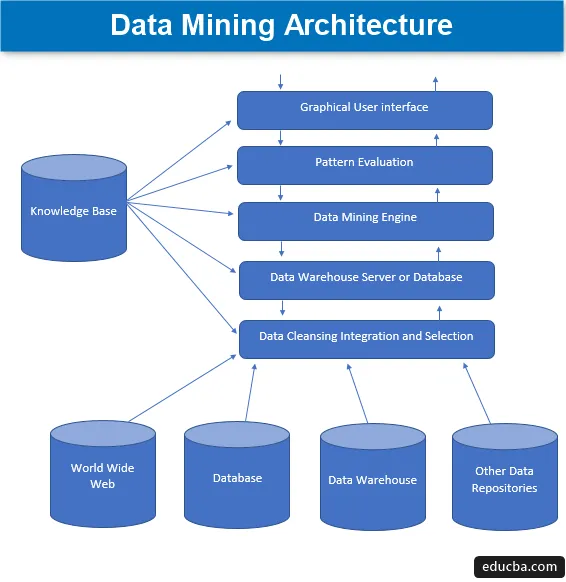
1. Datakilder
Et stort udvalg af nuværende dokumenter såsom datavarehus, database, www eller populært kaldet et verdensomspændende web, der bliver de faktiske datakilder. Oftest kan det også være tilfældet, at dataene ikke findes i nogen af disse gyldne kilder, men kun i form af tekstfiler, almindelige filer eller sekvensfiler eller regneark, og så skal dataene behandles i en meget på samme måde som behandlingen ville blive udført på data modtaget fra gyldne kilder. Det meste af det store stykke data i dag modtages fra internettet eller world wide web, da alt, hvad der findes på internettet i dag, er data i en eller anden form, der danner en form for informationslagringsenheder.
Inden dataene behandles forud, involverer de forskellige processer, som de går igennem, datarensning, integration og valg, før dataene til sidst overføres til databasen eller en hvilken som helst af EDW (enterprise data warehouse) serveren. Den største udfordring, som til tider ligger i dette datasæt, er forskellige kilderniveauer og en bred vifte af dataformater, der danner datakomponenterne. Derfor kan dataene ikke direkte bruges til behandling i sin naive tilstand, men behandles, transformeres og udformes på en meget mere anvendelig måde. På denne måde sikres også pålidelighed og fuldstændighed af dataene. Så det primære trin involverer dataindsamling, rengøring og integration, og skriv, at kun de relevante data videresendes. Al denne aktivitet er en del af et separat sæt værktøjer og teknikker.
2. Datavarehouse-server eller -database
Databaseserveren er det faktiske rum, hvor dataene er indeholdt, når de er modtaget fra det forskellige antal datakilder. Serveren indeholder det faktiske datasæt, der bliver klar til at blive behandlet, og derfor administrerer serveren dataindsamlingen. Al denne aktivitet er baseret på anmodningen om datamining af personen.
3. Data Mining Engine
I tilfælde af dataindvinding danner motoren kernekomponenten og er den mest vitale del, eller at sige drivkraften, der håndterer alle anmodninger og administrerer dem og bruges til at indeholde et antal moduler. Antallet af tilstedeværende moduler inkluderer mineopgaver såsom klassificeringsteknik, tilknytningsteknik, regressionsteknik, karakterisering, forudsigelse og klynger, tidsserier analyse, naive Bayes, supportvektormaskiner, ensemblemetoder, boosting og bagging teknikker, tilfældige skove, beslutningstræer, etc.
4. Mønsterevalueringsmoduler
Denne evalueringsteknik for modulerne er hovedsageligt ansvarlig for at måle interessantheden af alle de mønstre, der bruges til beregning af det grundlæggende niveau for tærskelværdien, og bruges også til at interagere med dataindvindingsmotoren til koordinering i evalueringen af andre moduler. Alt i alt er hovedformålet med denne komponent at kigge efter og søge efter alle de interessante og anvendelige mønstre, der kan gøre dataene af relativt bedre kvalitet.
5. Grafisk brugergrænseflade
Når dataene kommunikeres med motorerne og blandt forskellige mønsterevalueringer af moduler, bliver det en nødvendighed at interagere med de forskellige komponenter, der er til stede, og gøre dem mere brugervenlige, så effektiv og effektiv anvendelse af alle de nuværende komponenter kunne gøres, og derfor opstår behovet for en grafisk brugergrænseflade populært kendt som GUI.
Dette bruges til at skabe en følelse af kontakt mellem brugeren og data mining-systemet, hvilket hjælper brugerne med at få adgang til og bruge systemet effektivt og let for at holde dem blottet for enhver kompleksitet, der har opstået i processen. Dette er en form for abstraktion, hvor kun de relevante komponenter vises for brugerne, og alle de kompleksiteter og funktionaliteter, der er ansvarlige for at opbygge systemet, er skjult af hensyn til enkelheden. Hver gang brugeren sender en forespørgsel, interagerer modulet derefter med det samlede sæt af et data mining-system for at producere en relevant output, som let kunne vises for brugeren på en meget mere forståelig måde.
6. Knowledge Base
Dette er den komponent, der danner basen i den samlede dataindvindingsproces, da det hjælper med at vejlede søgningen eller i vurderingen af de dannede mønsters interesse. Denne vidensbase består af brugertro og også de data, der er opnået fra brugeroplevelser, som igen er nyttige i data mining processen. Motoren får muligvis sit sæt indgange fra den oprettede vidensbase og giver dermed mere effektive, nøjagtige og pålidelige resultater.
Data mining er en af de vigtigste teknikker i dag, der beskæftiger sig med datastyring og databehandling, der udgør rygraden i enhver organisation. Analyse af data i enhver organisation giver frugtbare resultater. Hver eneste komponent i dataminingsteknikken og -arkitekturen har sin egen måde at udføre ansvar og også til at gennemføre dataudvinding effektivt. De forskellige moduler er nødvendige for at interagere korrekt for at producere et værdifuldt resultat og fuldføre den komplekse procedure for dataindvinding med succes ved at give det rigtige sæt information til virksomheden.
Anbefalede artikler
Dette har været en guide til Data Mining Architecture. Her diskuterer vi de primære komponenter i data mining Architecture. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Data Mining Tool
- Fordele ved Data Mining
- Hvad er klynge i datamining?
- HTML5 Interview Spørgsmål og svar
- Mest anvendte teknikker til ensemblæring
- Algoritmer af modeller i datamining