
Oversigt over neurale netværksalgoritmer
- Lad os først vide, hvad betyder et neuralt netværk? Neurale netværk er inspireret af de biologiske neurale netværk i hjernen, eller vi kan sige nervesystemet. Det har skabt en masse spænding, og der foregår stadig forskning i denne undergruppe af Machine Learning i industrien.
- Den basale beregningsenhed i et neuralt netværk er en neuron eller knude. Det modtager værdier fra andre neuroner og beregner output. Hver knude / neuron er forbundet med vægt (w). Denne vægt er angivet pr. Relativ betydning af den pågældende neuron eller knude.
- Så hvis vi tager f som nodefunktion, giver nodefunktionen f output som vist nedenfor: -
Udgang af neuron (Y) = f (w1.X1 + w2.X2 + b)
- Hvor w1 og w2 er vægt, er X1 og X2 numeriske indgange, hvorimod b er bias.
- Ovenstående funktion f er en ikke-lineær funktion, også kaldet aktiveringsfunktion. Dets grundlæggende formål er at introducere ikke-linearitet, da næsten alle data fra den virkelige verden er ikke-lineære, og vi ønsker, at neuroner skal lære disse repræsentationer.
Forskellige neurale netværksalgoritmer
Lad os nu undersøge fire forskellige neurale netværksalgoritmer.
1. Gradient Descent
Det er en af de mest populære optimeringsalgoritmer inden for maskinlæring. Det bruges under træning af en maskinlæringsmodel. Med enkle ord bruges det dybest set til at finde værdier på koefficienterne, der simpelthen reducerer omkostningsfunktionen så meget som muligt. Først starter vi med at definere nogle parameterværdier og derefter ved hjælp af en beregning begynder vi at iterativt justere værdierne, så den mistede funktion reduceres.
Lad os nu komme til den del, hvad der er gradient ?. Så en gradient betyder meget, at output fra enhver funktion ændres, hvis vi reducerer input med lidt eller med andre ord, vi kan kalde det til skråningen. Hvis skråningen er stejl, lærer modellen hurtigere på lignende måde stopper en model med at lære, når skråningen er nul. Dette skyldes, at det er en minimeringsalgoritme, der minimerer en given algoritme.
Under formlen til at finde den næste position vises i tilfælde af gradientafstamning.
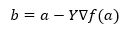
Hvor b er den næste position
a er den aktuelle position, gamma er en ventende funktion.
Så som du kan se, er gradientafstamning en meget lydteknik, men der er mange områder, hvor gradientafstamning ikke fungerer korrekt. Nedenfor findes nogle af dem:
- Hvis algoritmen ikke udføres korrekt, kan vi støde på noget som problemet med forsvindende gradient. Disse forekommer, når gradienten er for lille eller for stor.
- Problemer opstår, når dataindretningen udgør et ikke-konvekst optimeringsproblem. Gradient anstændigt fungerer kun med problemer, der er det konvekse optimerede problem.
- En af de meget vigtige faktorer, man skal kigge efter, mens man anvender denne algoritme, er ressourcer. Hvis vi har mindre hukommelse tildelt til applikationen, bør vi undgå gradientafstødningsalgoritme.
2. Newtons metode
Det er en andenordens optimeringsalgoritme. Det kaldes en anden orden, fordi den gør brug af den hessiske matrix. Så den hessiske matrix er intet andet end en firkantet matrix af andenordens partielle derivater af en skaleret værdi-funktion. I Newtons metodeoptimeringsalgoritme anvendes den til den første derivat af en dobbelt differentierbar funktion f, så den kan finde rødderne / stationære punkter. Lad os nu komme ind på de trin, der kræves af Newtons metode til optimering.
Den evaluerer først tabsindekset. Derefter kontrolleres det, om stopkriterierne er sande eller forkerte. Hvis det er forkert, beregnes det derefter Newtons træningsretning og træningsfrekvens og forbedrer derefter parametre eller vægte på neuronet og igen fortsætter den samme cyklus. Så kan du nu sige, at det tager færre trin sammenlignet med gradientafstigning for at få minimum værdien af funktionen. Selvom det tager færre trin sammenlignet med gradientafstødningsalgoritmen, bruges den stadig ikke bredt, da den nøjagtige beregning af hessian og dens inverse er beregningsmæssigt meget dyre.
3. Konjugeret gradient
Det er en metode, der kan betragtes som noget mellem gradientafstamning og Newtons metode. Den største forskel er, at det fremskynder den langsomme konvergens, som vi generelt forbinder med gradientafstamning. Et andet vigtigt faktum er, at det kan bruges til både lineære og ikke-lineære systemer, og det er en iterativ algoritme.
Det blev udviklet af Magnus Hestenes og Eduard Stiefel. Som allerede nævnt ovenfor, at det producerer hurtigere konvergens end gradientafstamning. Årsagen til, at det er i stand til at gøre det, er, at i konjugatgradientalgoritmen foretages søgningen sammen med konjugatretningerne, hvorfor den konvergerer hurtigere end gradientafstødningsalgoritmer. Et vigtigt punkt at bemærke er, at y kaldes den konjugerede parameter.
Træningsretningen nulstilles periodisk til det negative af gradienten. Denne metode er mere effektiv end gradientafstamning til træning af det neurale netværk, da det ikke kræver den hessiske matrix, der øger beregningsbelastningen, og den konvergerer også hurtigere end gradientafstamning. Det er passende at bruge i store neurale netværk.
4. Quasi-Newton-metode
Det er en alternativ tilgang til Newtons metode, da vi nu er opmærksomme på, at Newtons metode er beregningsdygtig. Denne metode løser disse ulemper i en sådan grad, at i stedet for at beregne den hessiske matrix og derefter beregne den inverse direkte, bygger denne metode op en tilnærmelse til at inverse Hessian ved hver iteration af denne algoritme.
Nu beregnes denne tilnærmelse ved hjælp af informationen fra det første derivat af tabsfunktionen. Så vi kan sige, at det sandsynligvis er den bedst egnede metode til at håndtere store netværk, da det sparer beregningstid, og det er også meget hurtigere end gradientafstigning eller konjugeret gradientmetode.
Konklusion
Inden vi afslutter denne artikel, skal vi sammenligne beregningshastighed og hukommelse for de ovennævnte algoritmer. I henhold til hukommelseskrav kræver gradientafstigning den mindste hukommelse, og det er også den langsomste. Tværtimod kræver Newtons metode mere computerkraft. Så under hensyntagen til alle disse er Quasi-Newton-metoden den bedst egnede.
Anbefalede artikler
Dette har været en guide til neurale netværksalgoritmer. Her diskuterer vi også oversigten over henholdsvis Neural Network Algorithm sammen med fire forskellige algoritmer. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Machine Learning vs Neural Network
- Rammer for maskinlæring
- Neurale netværk vs dyb læring
- K- betyder klynge-algoritme
- Vejledning til klassificering af neuralt netværk