

Introduktion til beslutningstræ i datamining
I dagens verden på "Big Data" betyder udtrykket "Data Mining", at vi er nødt til at undersøge store datasæt og udføre "mining" på dataene og få frem den vigtige juice eller essens i det, dataene vil sige. En meget analog situation er kulminedrift, hvor forskellige redskaber kræves for at mine kulet, der er begravet dybt under jorden. Af værktøjerne i Data mining er “Decision Tree” et af dem. Således er dataudvinding i sig selv et stort felt, hvor de næste par afsnit, vi dybt dykker ned i beslutningstræets “værktøj” i Data Mining.
Algoritme for beslutningstræet i datamining
Et beslutningstræ er en overvåget læringsmetode, hvor vi træner de tilstedeværende data med allerede at vide, hvad målvariablen faktisk er. Som navnet antyder har denne algoritme en trætype af struktur. Lad os først se på det teoretiske aspekt af beslutningstræet og derefter undersøge det samme i en grafisk tilgang. I Decision Tree opdeler algoritmen datasættet i undergrupper på grundlag af den vigtigste eller mest betydningsfulde attribut. Den mest markante attribut er angivet i rodnoden, og det er her opdelingen finder sted af hele datasættet, der findes i rodnoden. Dette opdelte kaldes beslutningsnoder. I tilfælde af at der ikke er mere opdeling er det muligt, at noden betegnes som en bladknude.
For at stoppe algoritmen for at nå et overvældende stadium anvendes der et stopkriterium. Et af stopkriterierne er det mindste antal observationer i noden, inden opdelingen sker. Når man anvender beslutningstræet ved opdeling af datasættet, skal man være forsigtig med, at mange noder måske bare har støjende data. For at imødekomme et tidligere eller støjende dataproblemer anvender vi teknikker, der kaldes Data beskæring. Databehandling er intet andet end en algoritme til klassificering af data fra undergruppen, hvilket gør sig selv vanskelig for at lære fra en given model.
Decision Tree-algoritmen blev frigivet som ID3 (Iterative Dichotomiser) af maskinforskeren J. Ross Quinlan. Senere blev C4.5 frigivet som efterfølgeren til ID3. Både ID3 og C4.5 er en grådig tilgang. Lad os nu undersøge et flowdiagram af beslutningstrælsalgoritmen.
For vores pseudocode-forståelse ville vi tage “n” datapunkter, der hver har “k” -attributter. Under flowchart tages husk på "Information Gain" som betingelsen for en opdeling.
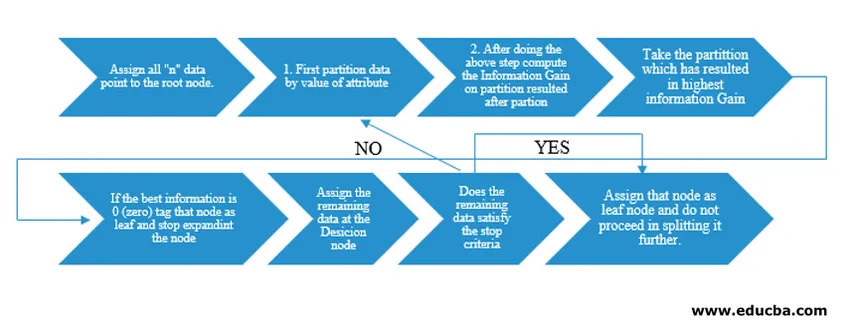
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
I stedet for Information Gain (IG), kan vi også anvende Gini-indekset som kriterierne for en split. For at forstå forskellen mellem disse to kriterier i lekmænd kan vi tænke på denne informationsgevinst som forskel på entropi før opdelingen og efter opdelingen (delt på grundlag af alle tilgængelige funktioner).
Entropi er som tilfældighed, og vi ville nå et punkt efter opdelingen for at have den mindst tilfældige tilstand. Derfor skal informationsgevinst være størst for den funktion, vi ønsker at opdele. Ellers hvis vi vil vælge at dele på basis af Gini-indeks, ville vi finde Gini-indekset for forskellige attributter, og ved hjælp af det samme finder vi vægtet Gini-indeks til forskellige split og bruger det med højere Gini-indeks til at opdele datasættet.
Vigtige betingelser for beslutningstræet i datamining
Her er nogle af de vigtige udtryk for et beslutningstræ i data mining, der er givet nedenfor:
- Root Node: Dette er den første knude, hvor opdelingen finder sted.
- Bladknudepunkt: Dette er den knude, hvorefter der ikke er flere forgreninger.
- Beslutningsnode: Den knude, der dannes efter opdeling af data fra en tidligere knude, er kendt som en beslutningsknudepunkt.
- Filial: Delafsnit af et træ, der indeholder oplysninger om kølvandet på split i beslutningsnoden.
- Beskæring: Når der er fjernelse af undernoder i en beslutningsknudepunkt for at imødekomme en uddybende eller støjende data kaldes beskæring. Det menes også at være det modsatte af opdeling.
Anvendelse af beslutningstræet i dataudvinding
Decision Tree har en flowchart-type arkitektur indbygget med typen algoritme. Det har i det væsentlige et "Hvis X, så Y andet Z" -mønster, mens opdelingen er lavet. Denne type mønstre bruges til at forstå menneskets intuition inden for det programmatiske felt. Derfor kan man i vid udstrækning bruge dette i forskellige kategoriseringsproblemer.
- Denne algoritme kan bruges i vid udstrækning i det felt, hvor objektivfunktionen er relateret med hensyn til analysen, der er udført.
- Når der er adskillige handlingsforløb til rådighed.
- Tidligere analyse.
- At forstå det betydelige sæt funktioner for hele datasættet og “mine” de få funktioner fra en liste over hundreder af funktioner i big data.
- Valg af den bedste flyrejse til en destination.
- Beslutningsproces baseret på forskellige omstændigheder.
- Churn-analyse.
- Følelsesanalyse.
Fordele ved beslutningstræet
Her er nogle fordele ved beslutningstræet, der er beskrevet nedenfor:
- Brugervenlighed: Den måde, beslutnings træet portrætteres i dets grafiske former, gør det let at forstå for en person med ikke-analytisk baggrund. Især for mennesker i ledelse, der ønsker at se på, hvilke egenskaber der er vigtige bare ved et blik på beslutningstræet kan fremlægge deres hypotese.
- Data-efterforskning: Som omtalt er at få betydelige variabler en kernefunktionalitet i beslutningstræet og bruge det samme, man kan finde ud af under data-efterforskning ved at beslutte, hvilken variabel der skal være særlig opmærksom i løbet af data mining og modelleringsfasen.
- Der er meget lidt menneskelig indgriben i dataforberedelsestrinnet, og som et resultat af den tid, der forbruges under data, mindskes rengøringen.
- Decision Tree er i stand til at håndtere kategoriske såvel som numeriske variabler og tager også højde for klasseklassifikationsproblemer.
- Som en del af antagelsen har beslutningstræer ingen antagelse fra en rumlig fordeling og klassificeringsstruktur.
Konklusion
Til sidst indebærer afgørelsen træer en helt anden klasse af ikke-linearitet og tager sigte på at løse problemer med ikke-linearitet. Denne algoritme er det bedste valg til at efterligne et beslutningsniveau og tænke på mennesker og fremstille det i en matematisk-grafisk form. Det tager en top-down tilgang til bestemmelse af resultater fra nye usynlige data og følger princippet om splittelse og erobring.
Anbefalede artikler
Dette er en guide til beslutningstræ i datamining. Her diskuterer vi algoritmen, betydningen og anvendelsen af beslutningstræet i data mining sammen med dets fordele. Du kan også se på de følgende artikler for at lære mere -
- Data Science Machine Learning
- Typer af dataanalyseteknikker
- Beslutningstræ i R
- Hvad er datamining?
- Vejledning til forskellige metoder til dataanalyse