

Forskellen mellem Hadoop og Hive
Hadoop:
Hadoop er en ramme eller software, der blev opfundet til at styre enorme data eller Big Data. Hadoop bruges til at lagre og behandle de store data, der distribueres over en klynge af vareserver.
Hadoop gemmer dataene ved hjælp af Hadoop distribuerede filsystem og behandler / forespørger dem ved hjælp af Map Reduce programmeringsmodel.
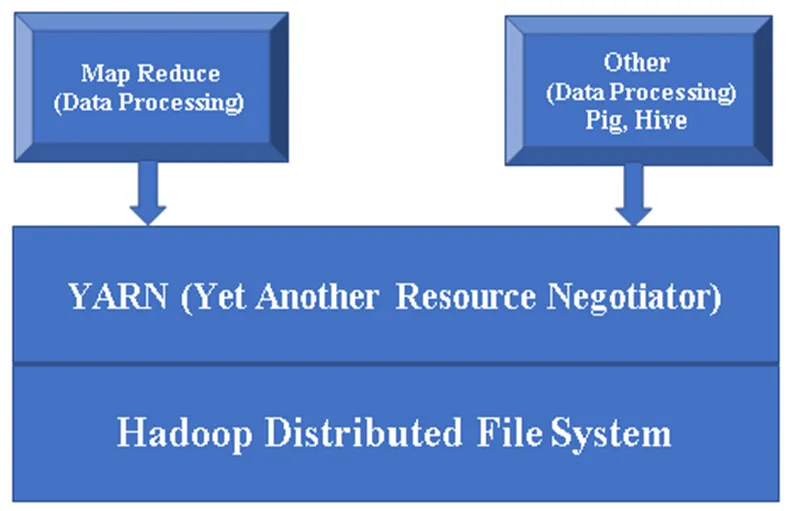
Figur 1, en grundlæggende arkitektur af en Hadoop-komponent.
Hadoop's vigtigste komponenter:
Hadoop Base / Common: Hadoop Common giver dig en platform til at installere alle dens komponenter.
HDFS (Hadoop Distribueret filsystem): HDFS er en væsentlig del af Hadoop-rammerne, det tager sig af alle data i Hadoop Cluster. Det fungerer på Master / Slave Architecture og gemmer dataene ved hjælp af replikering.
Master / slavearkitektur og replikering:
- Master Node / Name Node: Navneknap gemmer metadataene for hver blok / fil, der er gemt i HDFS, HDFS kan kun have en Master Node (I tilfælde af HA fungerer en anden Master Node som Secondary Master Node).
- Slave Node / Data Node: Datanoder indeholder faktiske datafiler i blokke. HDFS kan have flere datanoder.
- Replikering: HDFS gemmer sine data ved at dele dem op i blokke. Standard blokstørrelse er 64 MB. På grund af replikationsdata bliver lagret i 3 (standardreplikationsfaktor, kan øges pr. Krav) forskellige datanoder, hvorfor der er mindst mulig mulighed for at miste dataene i tilfælde af knudepunktfejl.
Garn (Endnu en ressourceforhandler): Det bruges dybest set til styring af Hadoop-ressourcer, og det spiller også en vigtig rolle i planlægningen af brugernes applikation.
MR (Map Reduce): Dette er den grundlæggende programmeringsmodel for Hadoop. Det bruges til at behandle / forespørge data inden for Hadoop rammer.
hive:
Hive er et program, der kører over Hadoop-rammerne og giver SQL-lignende interface til behandling / forespørgsel om dataene. Hive er designet og udviklet af Facebook, inden den bliver en del af Apache-Hadoop-projektet.
Hive kører sin forespørgsel ved hjælp af HQL (Hive-forespørgselssprog). Hive har den samme struktur som RDBMS, og næsten samme kommandoer kan bruges i Hive.
Hive kan gemme dataene i eksterne tabeller, så det er ikke obligatorisk at bruge HDFS, også understøtter det filformater som ORC, Avro-filer, Sekvensfil og tekstfiler osv.
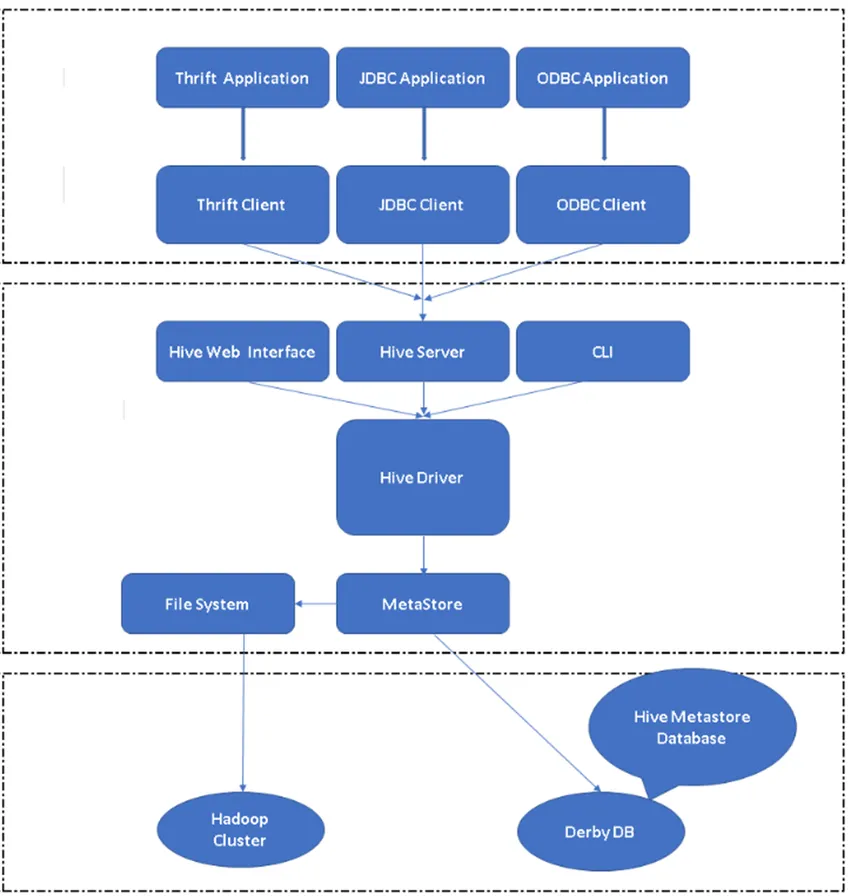
Figur 2, Hive's Architecture & It's vigtigste komponenter.
Hives vigtigste komponent:
Hive-klienter: Ikke kun SQL, Hive understøtter også programmeringssprog som Java, C, Python ved hjælp af forskellige drivere såsom ODBC, JDBC og Thrift. Man kan skrive en hvilken som helst hive-klientapplikation på andre sprog og kan køre i Hive ved hjælp af disse klienter.
Hive-tjenester: Under Hive-tjenester finder eksekvering af kommandoer og forespørgsler sted. Hive-webgrænseflade har fem underkomponenter.
- CLI: Standard kommandolinjegrænseflade leveret af Hive til udførelse af Hive-forespørgsler / -kommandoer.
- Hive-webgrænseflader: Det er en enkel grafisk brugergrænseflade. Det er et alternativ til Hive-kommandolinjen og bruges til at køre forespørgsler og kommandoer i Hive-applikationen.
- Hive Server: Det kaldes også som Apache Thrift. Det er ansvarligt at tage kommandoer fra forskellige - forskellige kommandolinjegrænseflader og indsende alle kommandoer / forespørgsler til Hive, også det henter det endelige resultat.
- Apache Hive Driver: Det er ansvarligt for at tage input fra CLI-, web-UI-, ODBC-, JDBC- eller Thrift-grænsefladerne fra en klient og videregive informationen til metastore, hvor alle filinformationen er gemt.
- Metastore: Metastore er et lager til at gemme alle Hive-metadataoplysninger. Hives metadata gemmer informationen såsom strukturen af tabeller, partitioner & kolonnetype osv…
Hive Storage: Det er det sted, hvor den faktiske opgave udføres. Alle de forespørgsler, der løber fra Hive, udførte handlingen inde i Hive-lageret.
Sammenligning mellem hoved og hoved mellem Hadoop vs Hive (Infographics)
Nedenfor er den øverste 8 forskel mellem Hadoop vs Hive
De vigtigste forskelle mellem Hadoop vs Hive:
Nedenfor er lister over punkter, der beskriver de vigtigste forskelle mellem Hadoop og Hive:
1) Hadoop er en ramme til behandling / forespørgsel af Big data, mens Hive er et SQL-baseret værktøj, der bygger over Hadoop for at behandle dataene.
2) Hive-proces / forespørgsel om alle data ved hjælp af HQL (Hive Query Language), det er SQL-lignende sprog, mens Hadoop kun kan forstå Map Reduce.
3) Map Reduce er en integreret del af Hadoop, Hive's forespørgsel konverteres først til Map Reduce end behandles af Hadoop for at forespørge dataene.
4) Hive fungerer på SQL Like-forespørgsel, mens Hadoop forstår det ved hjælp af Java-baseret Map Reduce.
5) I Hive kan tidligere anvendte traditionelle “Relational Database's” -kommandoer også bruges til at forespørge big data, mens du er i Hadoop, skal skrive komplekse Map Reduce-programmer ved hjælp af Java, der ikke ligner tradition Java.
6) Hive kan kun behandle / forespørge de strukturerede data, mens Hadoop er beregnet til alle typer data, hvad enten det er struktureret, ustruktureret eller semistruktureret.
7) Ved hjælp af Hive kan man behandle / forespørge dataene uden kompleks programmering, mens man i Simple Hadoop-økosystemet har brug for at skrive komplekst Java-program for de samme data.
8) Hadoop-rammerne på den ene side har brug for 100'ers linje for at forberede Java-baseret MR-program, en anden side Hadoop med Hive kan forespørge om de samme data ved hjælp af 8 til 10 linjer HQL.
9) I Hive er det meget vanskeligt at indsætte output fra en forespørgsel som input fra en anden, mens den samme forespørgsel let kan udføres ved hjælp af Hadoop med MR.
10) Det er ikke obligatorisk at have Metastore inden for Hadoop-klyngen, mens Hadoop gemmer alle dens metadata inde i HDFS (Hadoop Distribueret filsystem).
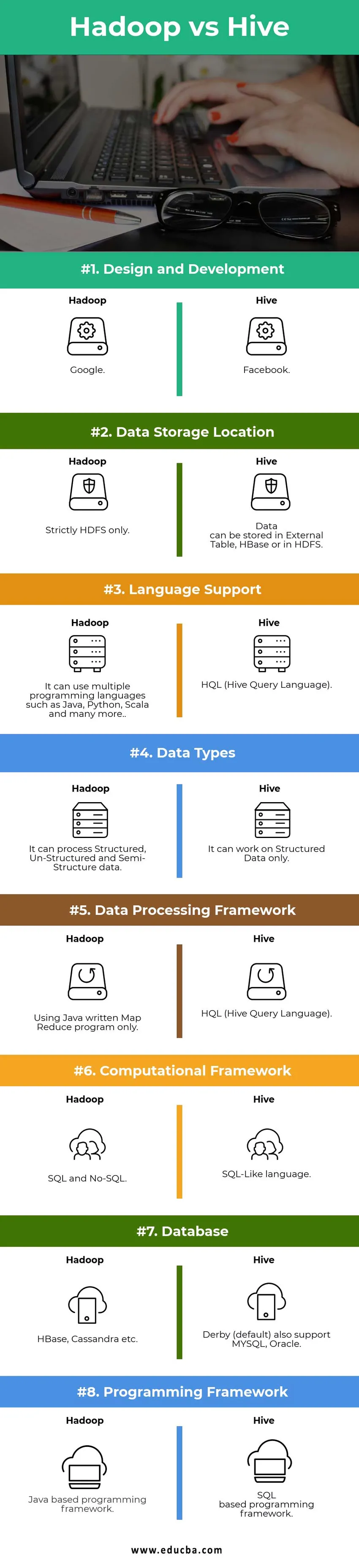
Hadoop vs Hive sammenligningstabel
| Sammenligningspunkter | hive | Hadoop |
|
Design og udvikling | ||
| Datalagringsplacering |
Data kan gemmes i eksternt Tabel, HBase eller i HDFS. | Strengt HDFS kun. |
| Sprogsupport | HQL (Hive Query Language) |
Det kan bruge flere programmeringssprog som Java, Python, Scala og mange flere. |
| Datatyper | Det kan kun arbejde på strukturerede data. |
Det kan behandle strukturerede, ustrukturerede og semistrukturerede data. |
| Ramme for databehandling |
HQL (Hive Query Language) | Brug kun af Java skrevet Map Reduce-program. |
|
Beregningsrammer | SQL-lignende sprog. | SQL og No-SQL. |
| Database |
Derby (standard) understøtter også MYSQL, Oracle … | HBase, Cassandra osv…. |
| Programmeringsramme |
SQL-baseret programmeringsramme. | Java-baseret programmeringsramme. |
Konklusion - Hadoop vs Hive
Hadoop og Hive bruges begge til at behandle Big data. Hadoop er en ramme, der giver platform for andre applikationer til at spørge / behandle Big Data, mens Hive kun er en SQL-baseret applikation, der behandler dataene ved hjælp af HQL (Hive Query Language)
Hadoop kan bruges uden Hive til at behandle big data, mens det ikke er nemt at bruge Hive uden Hadoop.
Som en konklusion kan vi ikke sammenligne Hadoop og Hive på nogen måde og på noget aspekt. Både Hadoop og Hive er helt forskellige. At køre begge teknologier sammen kan gøre Big Data-forespørgselsprocessen meget lettere og behagelig for Big Data-brugere.
Anbefalede artikler:
Dette har været en guide til Hadoop vs Hive, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Hadoop vs Apache Spark - Interessante ting, du har brug for at vide
- HADOOP vs RDBMS | Kend til de 12 nyttige forskelle
- Hvordan Big Data ændrer ansigtet til sundhedsvæsenet
- Top 12 sammenligning af Apache Hive vs Apache HBase (Infographics)
- Fantastisk guide til Hadoop vs Spark