

Introduktion til Hive-kommandoer
Hive-kommando er et datalagerinfrastrukturværktøj, der sidder øverst på Hadoop for at opsummere Big data. Det behandler strukturerede data. Det gør dataforespørgsler og analyse lettere. Hive-kommando kaldes også som "skema ved læsning;" Hive verificerer ikke data, når de indlæses, verifikation sker kun, når der udstedes en forespørgsel. Denne egenskab ved Hive gør det hurtigt til første indlæsning. Det er som at kopiere eller blot flytte en fil uden at lægge nogen begrænsninger eller kontroller. Hive blev først udviklet af Facebook. Apache Software Foundation tog det op senere og udviklede det videre.
Her er komponenterne i Hive-kommandoen:
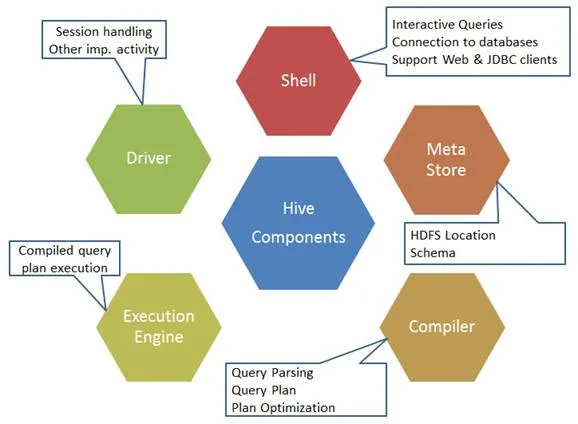
Fig. 1. Hivekomponenter
https://www.developer.com/
Her er kommandoen Features of Hive, der er anført nedenfor:
- Hive-butikker er rå og behandlet datasæt i Hadoop.
- Det er designet til OnLine Transaction Processing (OLTP). OLTP er de systemer, der letter data med meget lydstyrke på meget mindre tid uden afhængighed af den enkelte server.
- Det er hurtigt, skalerbart og pålideligt.
- SQL-forespørgselssprog, der leveres her, kaldes HiveQL eller HQL. Dette gør ETL-opgaver og anden analyse lettere.
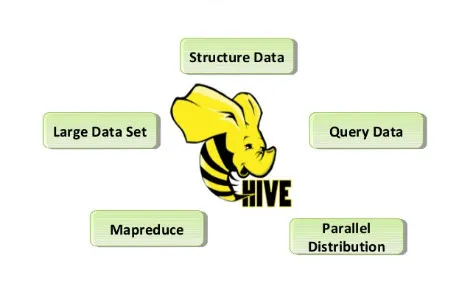
Fig. Hiveegenskaber
Kilder billeder: - Google
Der er kun få begrænsninger af Hive-kommandoen, som er anført nedenfor:
- Hive understøtter ikke underspørgsler.
- Hive understøtter helt sikkert overskrivning, men desværre understøtter det ikke sletning og opdateringer.
- Hive er ikke designet til OLTP, men den bruges til det.
Sådan åbner du Hive's interaktive shell:
$ HIVE_HOME / bin / bistade
Grundlæggende Hive-kommandoer
-
skab
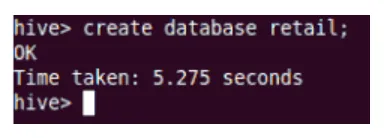
Dette skaber den nye database i Hive.
-
Dråbe
Dråben fjerner en tabel fra Hive
-
Ændre
Ændre kommando vil hjælpe dig med at omdøbe tabellen eller tabelkolonnerne.
For eksempel:
hive> ALTER TABEL medarbejder RENAME TO medarbejder1;
-
At vise
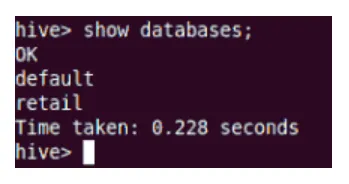
Vis-kommando viser alle databaserne, der er bosat i Hive.
-
Beskrive
Beskriv kommando vil hjælpe dig med oplysninger om skemaet i tabellen.
Mellemhive-kommandoer
Hive opdeler en tabel i forskellige relaterede partitioner baseret på kolonner. Ved hjælp af disse partitioner bliver det lettere at forespørge data. Disse partitioner bliver yderligere opdelt i spande for at køre forespørgslen effektivt videre til data.
Med andre ord distribuerer spande data i sættet med klynger ved at beregne hash-koden for nøglen, der er nævnt i forespørgslen.
-
Tilføjelse af partition
Tilføjelse af partition kan udføres ved at ændre tabellen. Lad os sige, at du har tabel "EMP" med felter som Id, Navn, Løn, Afd., Betegnelse og yoj.
hive> ALTER TABLE-medarbejder
> TILFØJ DELING (år = '2012')
placering '/ 2012 / del2012';
-
Omdøbning af partition
hive> ALTER TABEL MEDARBEJDERSDELING (år = '1203')
RENAME TO PARTITION (Yoj = '1203');
-
Drop Partition
hive> ALTER TABEL DROP MEDARBEJDERE (HVIS EKSISTER)
> DELTAGNING (år = '1203');
-
Relationsoperatører
Relationsoperatører består af et vist sæt operatører, der hjælper med at hente relevant information.
For eksempel: Sig din "EMP" -tabel se sådan ud:
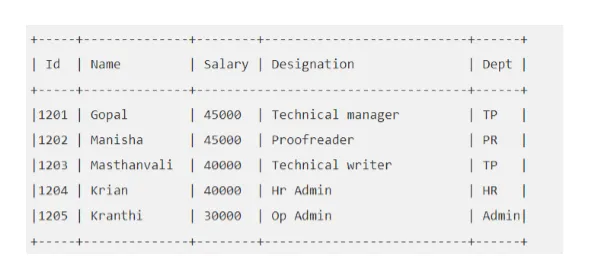
Lad os udføre Hive-forespørgsel, som henter os den medarbejder, hvis løn er større end 30000.
bikube> VÆLG * FRA EMP HVOR Løn> = 40000;
-
Aritmetiske operatører
Dette er operatører, der hjælper med at hjælpe med at udføre aritmetiske operationer på operanderne og til gengæld altid returnerer nummertyper.
For eksempel: For at tilføje to tal såsom 22 & 33
hive> VÆLG 22 + 33 TILFØJ FRA temp;
-
Logisk operatør
Disse operatører skal udføre logiske operationer, som til gengæld altid returnerer sandt / falsk.
bikube> VÆLG * FRA EMP HVOR Løn> 40000 && Afd. = TP;
Avancerede Hive-kommandoer
-
Udsigt
Visningskoncept i Hive er det samme som i SQL. Visningen kan oprettes på tidspunktet for udførelsen af en SELECT-sætning.
Eksempel:
hive> Opret VISNING EMP_30000 AS
VÆLG * FRA EMP
HVOR løn> 30000;
-
Indlæser data i tabellen
Hive> Indlæs data lokal inpath '/home/hduser/Desktop/AllStates.csv' i tabelstater;
Her er "Stater" den allerede oprettede tabel i Hive.
https://www.tutorialspoint.com/hive/
Hive har nogle indbyggede funktioner, der hjælper dig med at hente dit resultat på en bedre måde.
Som runde, gulv, BIGINT osv.
-
Tilslutte
Forbindelsesklausul kan hjælpe med at sammenføje to tabeller baseret på det samme kolonnenavn.
Eksempel:
bikube> VÆLG c.ID, c.NAME, c.AGE, o.AMOUNT
FRA KUNDER c BLINDER ORDERS o
ON (c.ID = o.CUSTOMER_ID);
Alle former for sammenføjninger understøttes af Hive: Venstre ydre sammenføjning, højre yderforbindelse, fuld yderforbindelse.
Tip og tricks til brug af bikive-kommandoer
Hive gør databehandling så let, ligetil og udvidelig, at brugeren er mindre opmærksomme på at optimere Hive-forespørgslerne. Men at være opmærksom på få ting, mens du skriver Hive-forespørgsel, vil helt sikkert medføre stor succes med at styre arbejdsbyrden og spare penge. Nedenfor er et par tip til det:
- Partitioner & spande: Hive er et big data-værktøj, der kan forespørges på store datasæt. Imidlertid kan skrivning af forespørgslen uden at forstå domænet give store partitioner i Hive.
Hvis brugeren er opmærksom på datasættet, kan relevante og meget anvendte kolonner grupperes i den samme partition. Dette vil hjælpe med at køre forespørgslen hurtigere og ineffektiv måde.
I sidste ende nej. af kortlægnings- og I / O-operationer vil også blive reduceret.
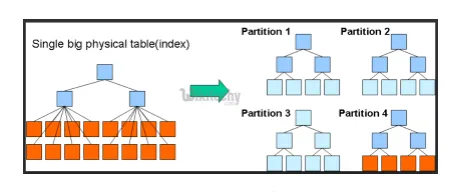
Fig. 3. Opdeling
Kilder billeder: Google-billede
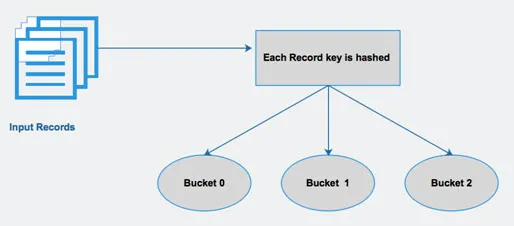
Fig. 4 Bucketing
Kilder billeder: - Google-billede
- Parallel udførelse: Hive kører forespørgslen i flere trin. I nogle tilfælde kan disse stadier afhænge af andre faser, og kan derfor ikke komme i gang, når den forrige fase er afsluttet. Uafhængige opgaver kan imidlertid køre parallelt for at spare den samlede køretid. Sådan aktiveres det parallelle kørsel i Hive:
sæt hive.exec.parallel = sandt;
Dette vil således forbedre brugen af klynger.
- Blokering af prøveudtagning: Sampling af data fra en tabel giver mulighed for udforskning af forespørgsler på data.
Trods bucking ønsker vi snarere at prøve datasæt mere tilfældigt. Bloksampling leveres med forskellige kraftige syntaks, som hjælper med at samle dataene på en anden måde.
Prøveudtagning kan bruges til at finde ca. info fra datasæt som den gennemsnitlige afstand mellem oprindelse og destination.
Forespørgsel 1% af big data giver næsten det perfekte svar. Udforskning bliver meget lettere og effektiv.
Konklusion - Hive-kommandoer
Hive er et højere niveauabstraktion oven på HDFS, som giver fleksibelt forespørgsel om forespørgsel. Det hjælper med at spørge og behandle data på en lettere måde.
Hive kan købes sammen med andre Big data-elementer for at udnytte dens funktionalitet på en fuldgyldig måde.
Anbefalede artikler
Dette har været en guide til Hive-kommandoer. Her har vi drøftet grundlæggende såvel som avancerede Hive-kommandoer og nogle øjeblikkelige Hive-kommandoer. Du kan også se på den følgende artikel for at lære mere -
- Spørgsmål om Hive-interview
- Hive VS nuance - Top 6 nyttige sammenligninger
- Tableau-kommandoer
- Adobe Photoshop-kommandoer
- Brug af ORDER BY-funktion i Hive
- Download og installer Hive trin for trin