
Forskellen mellem maskinlæring og forudsigelig analyse
Maskinlæring er et område inden for datalogi, der vokser spring og er bundet i disse dage. De seneste fremskridt inden for hardwareteknologier, som resulterede i en massiv stigning i computerkraft såsom GPU (grafiske behandlingsenheder) og fremskridt i neurale netværk, maskinlæring er blevet et brummerord. I det væsentlige kan vi ved hjælp af maskinlæringsteknikker bygge algoritmer til at udtrække data og se vigtige skjulte oplysninger fra dem. Forudsigelig analyse er også en del af maskinlæringsdomænet, som er begrænset til at forudsige det fremtidige resultat fra data baseret på tidligere mønstre. Selv om forudsigelig analyse har været i brug siden mere end to årtier hovedsageligt i bank- og finanssektoren, har anvendelse af maskinlæring taget fremtrædende i den senere tid med algoritmer som objektdetektion fra billeder, tekstklassificering og anbefalingssystemer.
Maskinelæring
Maskinlæring bruger internt statistikker, matematik og datalogi til at opbygge logik til algoritmer, der kan udføre klassificering, forudsigelse og optimering i både reelle tider og batchtilstand. Klassificering og regression er to hovedklasser af et problem under maskinlæring. Lad os forstå både Machine Learning og Predictive Analytics detaljeret.
Klassifikation
Under disse spande af et problem har vi en tendens til at klassificere et objekt baseret på dets forskellige egenskaber i en eller flere klasser. F.eks. Klassificering af en bankkunde for at være berettiget til et boliglån eller ikke baseret på hans / hendes kredithistorik. Normalt ville vi have transaktionsdata tilgængelige for kunden som hans alder, indkomst, uddannelsesmæssig baggrund, hans arbejdserfaring, branche, hvor han arbejder, antal afhængige, månedlige udgifter, eventuelle tidligere lån, hans forbrugsmønster, kredithistorik osv. og på grundlag af disse oplysninger har vi en tendens til at beregne, om han skulle få lån eller ej.
Der er mange standard maskinlæringsalgoritmer, der bruges til at løse klassificeringsproblemet. Logistisk regression er en sådan metode, sandsynligvis mest anvendt og mest kendt, også den ældste. Derudover har vi også nogle af de mest avancerede og komplicerede modeller, der spænder fra beslutningstræ til tilfældig skov, AdaBoost, XP boost, supportvektormaskiner, naiv baize og neuralt netværk. Siden de sidste par år kører dyb læring i spidsen. Typisk bruges neuralt netværk og dyb læring til at klassificere billeder. Hvis der er hundrede tusinde billeder af katte og hund, og du ønsker at skrive en kode, der automatisk kan adskille billeder af katte og hund, kan du tænke dig at gå til dybe læringsmetoder som et indviklet neuralt netværk. Lommelygte, cafe, sensorflyt osv. Er nogle af de populære biblioteker i python til dyb læring.
For at måle nøjagtigheden af regressionsmodeller bruges målinger som falsk positiv hastighed, falsk-negativ hastighed, følsomhed osv.
Regression
Regression er en anden klasse af problemer i maskinlæring, hvor vi forsøger at forudsige den kontinuerlige værdi af en variabel i stedet for en klasse i modsætning til i klassificeringsproblemer. Regressionsteknikker bruges generelt til at forudsige aktiekursen for en aktie, salgsprisen for et hus eller en bil, et efterspørgsel efter en bestemt vare osv. Når tidsserieegenskaber også kommer i spil, bliver regressionsproblemer meget interessante at løse. Lineær regression med almindelig mindst firkantet er en af de klassiske maskinlæringsalgoritmer på dette domæne. Til tidsseriebaseret mønster bruges ARIMA, eksponentielt glidende gennemsnit, vægtet glidende gennemsnit og simpelt bevægende gennemsnit.
For at måle nøjagtigheden af regressionsmodeller bruges metrics som gennemsnit kvadratfejl, absolut middelkvadratfejl, rodmål kvadratisk fejl osv.
Predictive Analytics
Der er nogle områder med overlapning mellem maskinlæring og forudsigelig analyse. Mens almindelige teknikker som logistik og lineær regression hører under både maskinlæring og forudsigelig analyse, er avancerede algoritmer som et beslutningstræ, tilfældig skov osv. I det væsentlige maskinlæring. Under forudsigelig analyse forbliver målet med problemerne meget snævert, hvor hensigten er at beregne værdien af en bestemt variabel på et fremtidigt tidspunkt. Predictive analytics er stærkt indlæst statistik, mens maskinlæring er mere en blanding af statistik, programmering og matematik. En typisk forudsigelig analytiker bruger sin tid på at beregne t square, f statistik, Innova, chi-square eller almindelig mindst square. Spørgsmål som om dataene normalt er distribueret eller skævt, skal elevens t-distribution anvendes eller bjældekurve bruges, skal alfa tages med 5% eller 10% bug dem hele tiden. De ser efter djævelen i detaljer. En maskinlæringsingeniør gider ikke med mange af disse problemer. Deres hovedpine er helt anderledes, de finder sig fast på nøjagtighedsforbedring, falsk-positiv hastighedsminimering, outlier-håndtering, rækkevidde-normalisering eller k fold-validering.
En forudsigelig analytiker bruger for det meste værktøjer som Excel. Scenario eller målsøgning er deres favorit. De bruger lejlighedsvis VBA eller mikros og skriver næppe nogen lang kode. En maskinlæringsingeniør bruger hele sin tid på at skrive kompliceret kode ud over almindelig forståelse, han bruger værktøjer som R, Python, Saas. Programmering er deres største arbejde, at rette bugs og teste på de forskellige landskaber en daglig rutine.
Disse forskelle bringer også en stor forskel i deres efterspørgsel og løn. Mens forudsigelige analytikere er så i går, er maskinlæring fremtiden. En typisk maskinlæringsingeniør eller datavidenskabsmand (som det mest kaldes i disse dage) får 60-80% mere betalt end en typisk softwareingeniør eller en forudsigelig analytiker for den sags skyld, og de er den vigtigste driver i dagens teknologibaserede verden. Uber, Amazon og nu selvkørende biler er også kun mulige på grund af dem.
Sammenligning fra head to head mellem maskinlæring vs forudsigelig analyse (infografik)
Nedenfor er de øverste 7 sammenligninger mellem Machine Learning vs Predictive Analytics
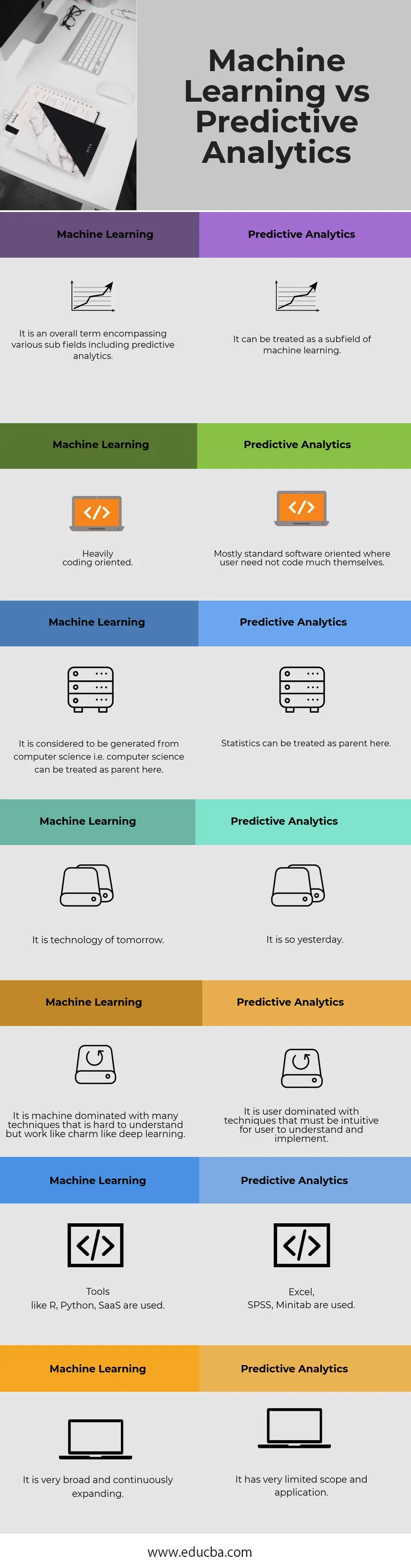
Machine Learning vs Predictive Analytics-sammenligningstabel
Nedenfor er den detaljerede forklaring af Machine Learning vs Predictive Analytics
| Maskinelæring | Predictive Analytics |
| Det er et overordnet udtryk, der omfatter forskellige underfelter, inklusive forudsigelig analyse. | Det kan behandles som et underfelt af maskinlæring. |
| Kraftigt kodningsorienteret. | Normalt standard softwareorienteret, hvor en bruger ikke selv behøver at kode meget |
| Det anses for at være genereret fra datalogi, dvs. datalogi kan behandles som overordnede her. | Statistikker kan behandles som en forælder her. |
| Det er morgendagens teknologi. | Det er så i går. |
| Det er en maskine domineret af mange teknikker, der er svære at forstå, men fungerer som charme som dyb læring. | Det er brugerdomineret med teknikker, der skal være intuitivt for en bruger at forstå og implementere. |
| Værktøjer som R, Python, SaaS bruges. | Excel, SPSS, Minitab bruges. |
| Det er meget bredt og kontinuerligt ekspanderende. | Det har et meget begrænset omfang og anvendelse. |
Konklusion - Machine Learning vs Predictive Analytics
Fra ovenstående diskussion om både maskinlæring og forudsigelig analyse er det klart, at forudsigelsesanalyse stort set er et underfelt inden for maskinlæring. Maskinlæring er mere alsidig og er i stand til at løse en lang række problemer.
Anbefalet artikel
Dette har været en guide til Machine Learning vs Predictive Analytics, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Lær Big Data Vs Machine Learning
- Forskellen mellem Data Science vs Machine Learning
- Sammenligning mellem forudsigelig analyse vs datavidenskab
- Data Analytics vs Predictive Analytics - Hvilken er nyttig