
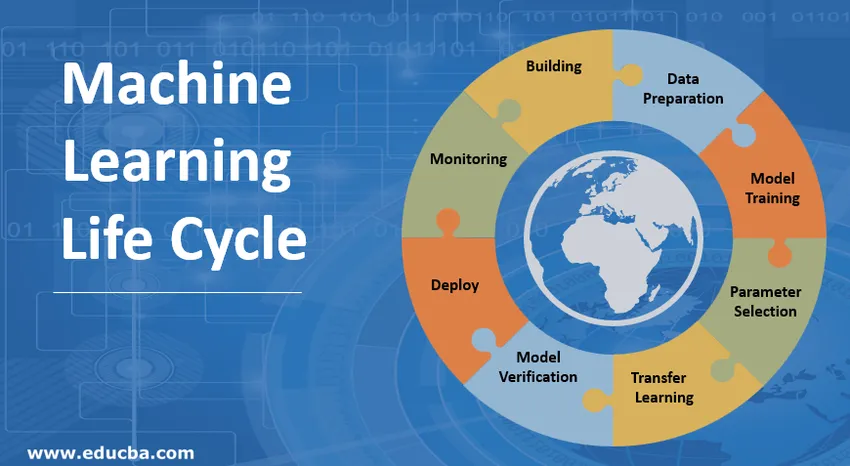
Introduktion til maskinlæring (ML) livscyklus
Machine Learning Life Cycle handler om at tilegne sig viden gennem data. Maskinens læringscyklus beskriver en trefaseproces, der bruges af dataforskere og dataingeniører til at udvikle, træne og betjene modeller. Udvikling, træning og service af maskinlæringsmodeller er resultatet af en proces kaldet maskinlæringscyklus. Det er et system, der bruger data som input, der har evnen til at lære og forbedre ved hjælp af algoritmer uden at være programmeret til det. Maskinens læringscyklus har tre faser som vist i figuren nedenfor: pipeline-udvikling, træning og inferens.
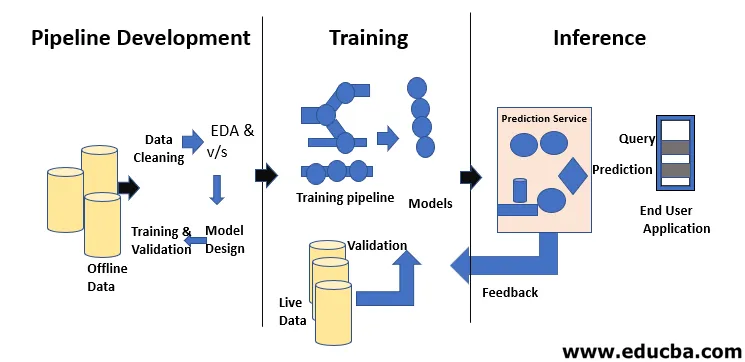
Det første trin i maskinlæringscyklussen består af at omdanne rå data til et renset datasæt, hvilket datasæt ofte deles og genbruges. Hvis en analytiker eller en dataforsker, der støder på problemer i de modtagne data, er de nødt til at få adgang til de originale data og transformationskripts. Der er forskellige årsager til, at vi måske ønsker at vende tilbage til tidligere versioner af vores modeller og data. For eksempel kan det at finde den tidligere bedste version kræve, at man søger gennem mange alternative versioner, da modeller uundgåeligt forringes i deres forudsigelsesevne. Der er mange grunde til denne forringelse, som et skift i distributionen af data, der kan resultere i et hurtigt fald i forudsigelsesevnen som kompensation for fejl. Diagnostisering af dette fald kan muligvis kræve sammenligning af træningsdata med live data, omskoling af modellen, revision af tidligere designbeslutninger eller endda redesigning af modellen.
Læring af fejl
Udviklingen af modeller kræver separat træning og test af datasæt. Overforbrug af testdata under træning kan føre til dårlig generalisering og ydeevne, da de kan føre til overdreven tilpasning. Kontekst spiller en vigtig rolle her, hvorfor det er nødvendigt at forstå, hvilke data der blev brugt til at træne de tilsigtede modeller, og med hvilke konfigurationer. Maskinens læringscyklus er datadrevet, fordi modellen og output af træningen er knyttet til de data, den blev trænet på. En oversigt over en ende til ende maskinlæring pipeline med et dataperspektiv er vist i figuren nedenfor:
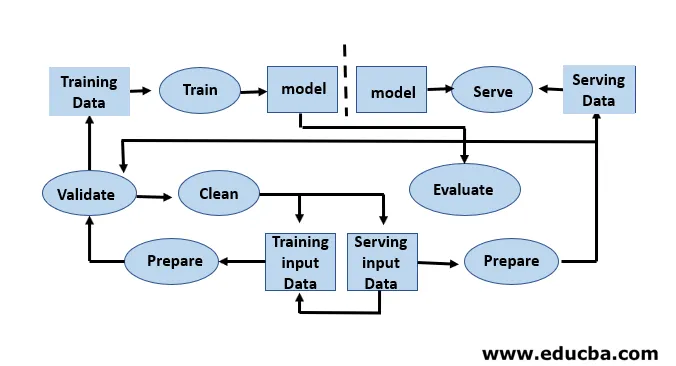
Trin involveret i maskinlæringscyklus
Machine Learning-udvikler udfører konstant eksperimentering med nye datasæt, modeller, softwarebiblioteker, indstilling af parametre for at optimere og forbedre modelnøjagtigheden. Da modelydelsen helt afhænger af inputdataene og træningsprocessen.
1. Opbygning af maskinlæringsmodellen
Dette trin bestemmer typen af modellen baseret på applikationen. Det finder også, at anvendelsen af modellen i modelindlæringsstadiet, så de kan designes korrekt i henhold til behovet for en bestemt applikation. En række forskellige maskinlæringsmodeller er tilgængelige, såsom den overvågede model, uovervåget model, klassificeringsmodeller, regressionsmodeller, klyngemodeller og forstærkende indlæringsmodeller. En tæt indsigt er afbildet i figuren nedenfor:
2. Forberedelse af data
En række forskellige data kan bruges som input til maskinindlæringsformål. Disse data kan komme fra en række kilder, såsom en virksomhed, farmaceutiske virksomheder, IoT-enheder, virksomheder, banker, hospitaler osv. Der leveres store mængder data i maskinens indlæringstrin, da antallet af data øges justeres det mod giver ønskede resultater. Disse outputdata kan bruges til analyse eller mates som input til andre applikationer eller systemer til maskinlæring, som de vil fungere som et frø.
3. Modeltræning
Denne fase handler om at skabe en model ud fra de data, der er givet til den. På dette trin bruges en del af træningsdataene til at finde modelparametre, såsom koefficienterne for et polynom eller vægte i maskinlæring, hvilket hjælper med at minimere fejlen for det givne datasæt. De resterende data bruges derefter til at teste modellen. Disse to trin gentages generelt et antal gange for at forbedre ydelsen af modellen.
4. Parametervalg
Det involverer valg af parametre forbundet med træningen, som også kaldes hyperparametre. Disse parametre styrer effektiviteten af træningsprocessen og dermed afhænger i sidste ende modelens ydelse af dette. De er meget vigtige for den vellykkede produktion af maskinlæringsmodellen.
5. Overfør læring
Da der er mange fordele ved at genbruge maskinindlæringsmodeller på tværs af forskellige domæner. På trods af det faktum, at en model ikke direkte kan overføres mellem forskellige domæner, bruges den derfor til at tilvejebringe et udgangsmateriale til påbegyndelse af træningen af en næste trinsmodel. Således reducerer det træningstiden markant.
6. Bekræftelse af modellen
Indgangen til dette trin er den træne model, der er produceret af modelindlæringsstadiet, og output er en verificeret model, der giver tilstrækkelig information til, at brugerne kan bestemme, om modellen er egnet til dens tilsigtede anvendelse. Dette trin i maskinlæringscyklussen drejer sig således om, at en model fungerer korrekt, når den behandles med usete input.
7. Installation af maskinindlæringsmodellen
I denne fase af maskinlæringscyklussen anvender vi til at integrere maskinlæringsmodeller i processer og applikationer. Det ultimative mål med dette trin er den korrekte funktionalitet af modellen efter installationen. Modellerne skal implementeres på en sådan måde, at de kan bruges til inferens, såvel som de skal opdateres regelmæssigt.
8. Overvågning
Det indebærer inkludering af sikkerhedsforanstaltninger for at sikre, at modellen fungerer korrekt i løbet af dens levetid. For at få dette til, kræves korrekt styring og opdatering.
Fordel ved maskinlæring livscyklus
Maskinlæring giver fordelene ved magt, hastighed, effektivitet og intelligens gennem indlæring uden eksplicit at programmere disse til en applikation. Det giver muligheder for forbedret ydelse, produktivitet og robusthed.
Konklusion - livscyklus for maskinlæring
Maskinlæringssystemer bliver vigtigere dag for dag, da mængden af data, der er involveret i forskellige applikationer, stiger hurtigt. Maskinindlæringsteknologi er hjertet i smarte enheder, husholdningsapparater og onlinetjenester. Succesen med maskinlæring kan udvides yderligere til sikkerhedskritiske systemer, datastyring, højtydende computing, der har et stort potentiale for applikationsdomæner.
Anbefalede artikler
Dette er en guide til Machine Learning Life Cycle. Her diskuterer vi introduktionen, Læring af fejl, trin, der er involveret i maskinlæringens livscyklus og fordele. Du kan også gennemgå vores andre foreslåede artikler for at lære mere–
- Kunstige efterretningsvirksomheder
- QlikView-sæt analyse
- IoT økosystem
- Cassandra Datamodellering