
Hvad er SVM-algoritme?
SVM står for Support Vector Machine. SVM er en overvåget maskinlæringsalgoritme, der ofte bruges til klassificerings- og regressionsudfordringer. Almindelige applikationer af SVM-algoritmen er Intrusion Detection System, Håndskriftsgenkendelse, Proteinstruktur Prediction, Detecting Steganography in digital images, etc.
I SVM-algoritmen er hvert punkt repræsenteret som et dataelement i det n-dimensionelle rum, hvor værdien af hver funktion er værdien af en bestemt koordinat.
Efter planlægning er klassificering udført ved at finde hype-plan, der adskiller to klasser. Se billedet nedenfor for at forstå dette koncept.
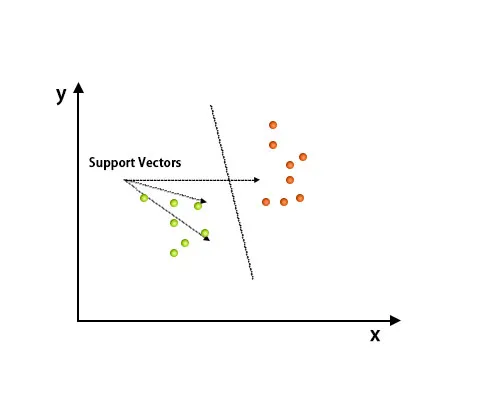
Support Vector Machine algoritme bruges hovedsageligt til at løse klassificeringsproblemer. Supportvektorer er intet andet end koordinaterne for hvert dataelement. Support Vector Machine er en grænse, der adskiller to klasser ved hjælp af hyperplan.
Hvordan fungerer SVM-algoritmen?
I ovenstående afsnit har vi drøftet differentieringen af to klasser ved hjælp af hyperplan. Nu skal vi se, hvordan denne SVM-algoritme rent faktisk fungerer.
Scenario 1: Identificer det rigtige hyperplan
Her har vi taget tre hyperplaner, dvs. A, B og C. Nu skal vi identificere det rigtige hyperplan til at klassificere stjerne og cirkel.
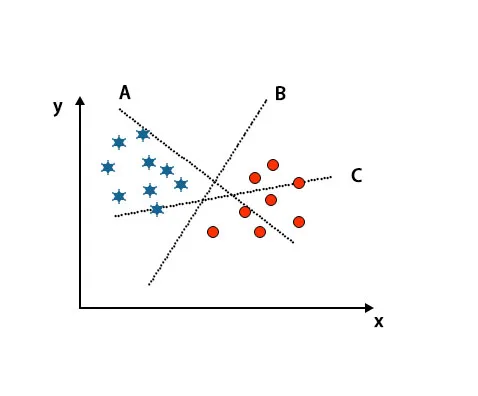
For at identificere det rigtige hyperplan skal vi kende tommelfingerreglen. Vælg hyperplan, der adskiller to klasser. I det ovennævnte billede differentierer hyperplan B to klasser meget godt.
Scenario 2: Identificer det rigtige hyperplan
Her har vi taget tre hyperplaner, dvs. A, B, og C. Disse tre hyperplanes adskiller allerede klasser meget godt.
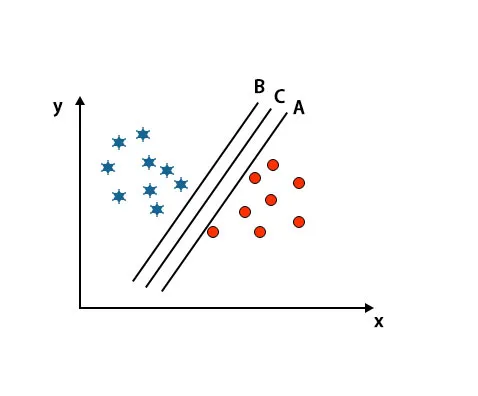
I dette scenarie øger vi afstanden mellem de nærmeste datapunkter for at identificere det rigtige hyperplan. Denne afstand er kun en margen. Se billedet nedenfor.
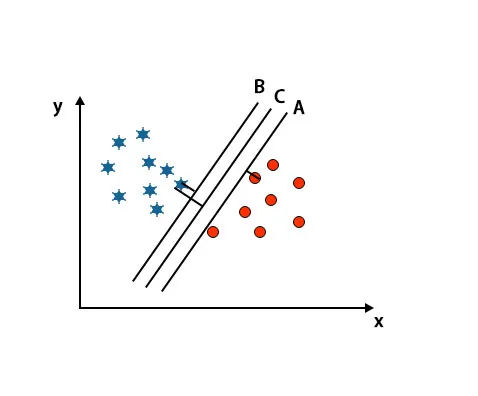
I det ovennævnte billede er margin på hyperplan C højere end hyperplan A og hyperplan B. Så i dette scenarie er C det rigtige hyperplan. Hvis vi vælger hyperplanet med en minimumsmarginal, kan det føre til misklassificering. Derfor valgte vi hyperplan C med maksimal margin på grund af robusthed.
Scenario 3: Identificer det rigtige hyperplan
Bemærk: For at identificere hyperplanet skal du følge de samme regler som nævnt i de foregående afsnit.
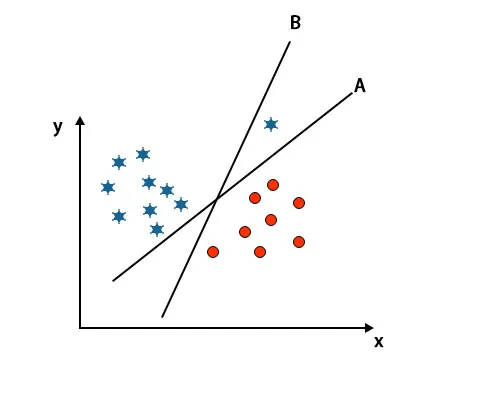
Som du kan se i det ovennævnte billede, er margin på hyperplan B højere end margin på hyperplan A, det er derfor, nogle vælger hyperplan B som højre. Men i SVM-algoritmen vælger den det hyperplan, der klassificerer klasser nøjagtigt inden maksimeringsmargenen. I dette scenarie har hyperplan A klassificeret alt præcist, og der er en vis fejl ved klassificeringen af hyperplan B. Derfor er A det rigtige hyperplan.
Scenario 4: Klassificer to klasser
Som du kan se på nedenstående billede, er vi ikke i stand til at differentiere to klasser ved hjælp af en lige linje, fordi den ene stjerne ligger som en outlier i den anden cirkelklasse.
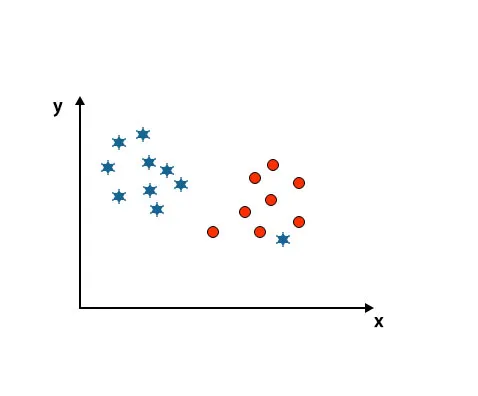
Her er en stjerne i en anden klasse. For stjerneklasse er denne stjerne den udflytter. På grund af SVM-algoritmens robusthedsegenskaber finder den det rigtige hyperplan med højere margin ignorerer en outlier.
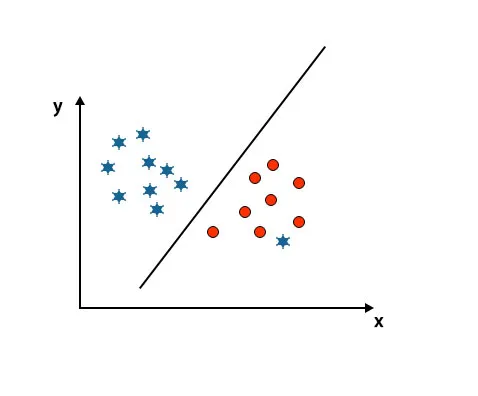
Scenario 5: Fin hyperplan for at differentiere klasser
Indtil nu har vi set lineært hyperplan. I det nævnte billede har vi ikke lineært hyperplan mellem klasser.
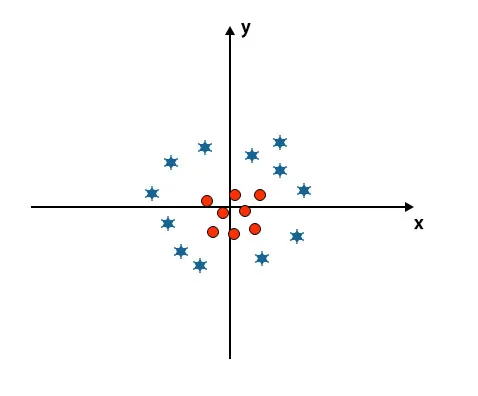
For at klassificere disse klasser introducerer SVM nogle yderligere funktioner. I dette scenarie skal vi bruge denne nye funktion z = x 2 + y 2.
Plotter alle datapunkter på x- og z-aksen.

Bemærk
- Alle værdier på z-aksen skal være positive, fordi z er lig med summen af x-kvadrat og y-kvadratet.
- I det ovennævnte plot er røde cirkler lukket for oprindelsen af x-aksen og y-aksen, hvilket fører værdien af z til lavere og stjerne er nøjagtigt det modsatte af cirklen, det er væk fra x-aksens oprindelse og y-aksen, hvilket fører værdien af z til høj.
I SVM-algoritmen er det let at klassificere ved hjælp af lineært hyperplan mellem to klasser. Men spørgsmålet opstår her er, hvis vi tilføjer denne funktion af SVM til at identificere hyperplan. Så svaret er nej, for at løse dette problem har SVM en teknik, der almindeligvis er kendt som et kerne-trick.
Kernel-trick er den funktion, der omdanner data til en passende form. Der er forskellige typer af kernefunktioner, der bruges i SVM-algoritmen, dvs. Polynomial, lineær, ikke-lineær, Radial Basis-funktion osv. Her bruges kernetrick lavdimensionelt input-rum konverteres til et højere-dimensionelt rum.
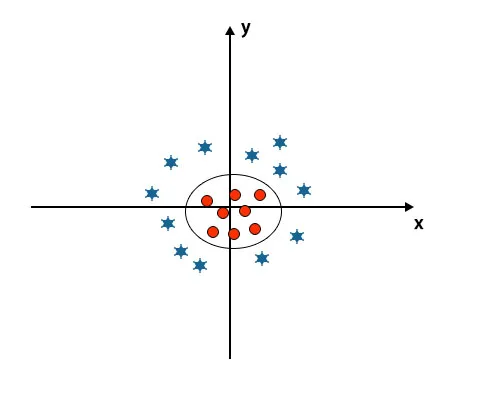
Når vi ser på hyperplanet oprindelsen af aksen og y-aksen, ser det ud som en cirkel. Se billedet nedenfor.
Fordele ved SVM-algoritme
- Selv hvis inputdata er ikke-lineære og ikke-adskillelige, genererer SVM'er nøjagtige klassificeringsresultater på grund af deres robusthed.
- I beslutningsfunktionen bruger den en undergruppe af træningspunkter kaldet supportvektorer, hvorfor den er hukommelseseffektiv.
- Det er nyttigt at løse ethvert komplekst problem med en passende kernefunktion.
- I praksis generaliseres SVM-modeller med mindre risiko for overfitting i SVM.
- SVM'er fungerer godt til tekstklassificering og når man finder den bedste lineære separator.
Ulemper ved SVM-algoritme
- Det tager lang træningstid, når man arbejder med store datasæt.
- Det er svært at forstå den endelige model og den individuelle påvirkning.
Konklusion
Det er blevet styret til at understøtte Vector Machine Algorithm, som er en maskinlæringsalgoritme. I denne artikel diskuterede vi, hvad der er SVM-algoritmen, hvordan det fungerer, og det er fordelene i detaljer.
Anbefalede artikler
Dette har været en guide til SVM-algoritme. Her diskuterer vi dets arbejde med et scenario, fordele og ulemper ved SVM-algoritme. Du kan også se på de følgende artikler for at lære mere -
- Dataindvindingsalgoritmer
- Dataminingsteknikker
- Hvad er maskinlæring?
- Værktøj til maskinindlæring
- Eksempler på C ++ algoritme