

Introduktion til Deltag i Spark SQL
Som vi ved, bruges sammenføjningerne i SQL til at kombinere data eller rækker fra to eller flere tabeller baseret på et fælles felt mellem dem. I dette emne lærer vi om Deltag i Spark SQL Deltag i Spark SQL.
I Spark SQL er Dataframe eller Dataset en tabelformet hukommelse med rækker og kolonner, der er fordelt på flere noder. Som normale SQL-tabeller kan vi også udføre sammenkoblingsoperationer på Dataframe eller Datasæt, der findes i Spark SQL, baseret på et fælles felt mellem dem.
Der er forskellige typer af Join-operationer tilgængelige i SQL. Afhængigt af den forretningsmæssige brugssag, vælger vi valg af Deltag. I det følgende afsnit demonstrerer vi hver type sammenføjning med eksempel.
Typer af deltag i Spark SQL
Følgende er de forskellige typer sammenføjninger, der er tilgængelige i Spark SQL:
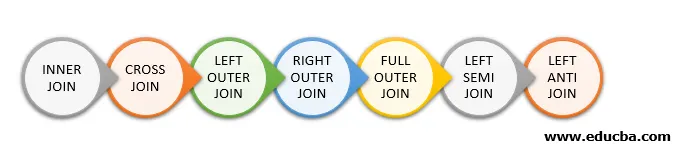
- INNER JOIN
- KRÆS DETALJER
- VENSTRE YDRE Deltager
- HØJRE UDVENDIGT BLI MED
- FULL YDRE JOIN
- VENSTRE SEMI DETALJER
- VENSTRE ANTI BLY MED
Eksempel på dataoprettelse
Vi bruger følgende data til at demonstrere de forskellige typer sammenføjninger:
Bogdatasæt:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
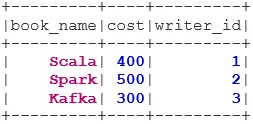
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
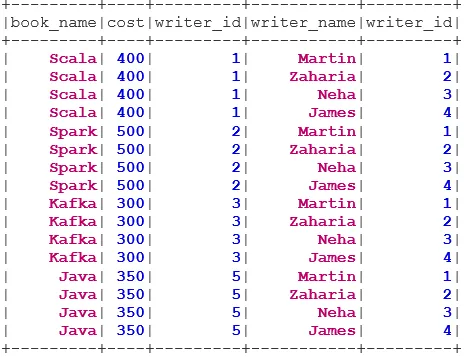
bookDS.show()

Writer Datasæt:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Typer af sammenføjninger
Nedenfor er nævnt 7 forskellige typer sammenføjninger:
1. INNER JOIN
INNER JOIN returnerer datasættet, der har rækkerne, der har matchende værdier i begge datasæt, dvs. værdien af det fælles felt vil være den samme.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. KRÆSSELUGNING
CROSS JOIN returnerer datasættet, der er antallet af rækker i det første datasæt ganget med antallet af rækker i det andet datasæt. En sådan type resultat kaldes det kartesiske produkt.
Forudsætning: For at bruge en krydsforbindelse skal spark.sql.crossJoin.enabled indstilles til sand. Ellers kastes undtagelsen.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. VENSTRE YDRE JOIN
LEFT OUTER JOIN returnerer datasættet, der har alle rækker fra det venstre datasæt, og de matchede rækker fra det højre datasæt.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. HØJRE UDREGTILSLUTNING
RIGHT OUTER JOIN returnerer datasættet, der har alle rækker fra det højre datasæt, og de matchede rækker fra det venstre datasæt.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. FULL YDRE JOIN
FULL OUTER JOIN returnerer datasættet, der har alle rækker, når der er en match i enten det venstre eller højre datasæt.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. VENSTRE SEMI JOIN
VENSTRE SEMI JOIN returnerer datasættet, der har alle rækker fra det venstre datasæt med deres korrespondance i det rigtige datasæt. I modsætning til LEFT OUTER JOIN, indeholder det returnerede datasæt i LEFT SEMI JOIN kun kolonnerne fra det venstre datasæt.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. VENSTRE ANTI JOIN
ANTI SEMI JOIN returnerer datasættet, der har alle rækkerne fra det venstre datasæt, der ikke har deres matchning i det rigtige datasæt. Det indeholder også kun kolonnerne fra det venstre datasæt.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Konklusion - Deltag i Spark SQL
Deltagelse af data er en af de mest almindelige og vigtige operationer til at opfylde vores forretningsbrugssag. Spark SQL understøtter alle de grundlæggende typer sammenføjninger. Når vi tilslutter os, er vi nødt til også at overveje ydeevne, da de muligvis kræver store netværksoverførsler eller endda oprette datasæt, der ligger ud over vores evne til at håndtere. For at forbedre ydelsen bruger Spark SQL optimizer til at ombestille eller skubbe ned filtre. Gnist begrænser også det farlige join i. e KRÆSSELUG. For at bruge cross cross skal spark.sql.crossJoin.enabled indstilles til at være sandt eksplicit.
Anbefalede artikler
Dette er en guide til at deltage i Spark SQL. Her diskuterer vi de forskellige typer af forbindelser, der er tilgængelige i Spark SQL med eksemplet. Du kan også se på den følgende artikel.
- Typer af sammenføjninger i SQL
- Tabel i SQL
- SQL Indsæt forespørgsel
- Transaktioner i SQL
- PHP-filtre | Sådan valideres brugerinput ved hjælp af forskellige filtre?