

Introduktion til AdaBoost-algoritme
AdaBoost-algoritme kan bruges til at øge ydeevnen for enhver maskinlæringsalgoritme. Machine Learning er blevet et kraftfuldt værktøj, der kan fremsætte forudsigelser baseret på en stor mængde data. Det er blevet så populært i nyere tid, at anvendelsen af maskinlæring kan findes i vores daglige aktiviteter. Et almindeligt eksempel på det er at få forslag til produkter, mens de handler online, baseret på de forrige varer, som kunden har købt. Maskinlæring, ofte omtalt som forudsigelig analyse eller forudsigelig modellering, kan defineres som computerens evne til at lære uden at være programmeret eksplicit. Den bruger programmerede algoritmer til at analysere inputdata for at forudsige output inden for et acceptabelt interval.
Hvad er AdaBoost-algoritme?
I maskinlæring stod boosting fra spørgsmålet om, hvorvidt et sæt svage klassifikatorer kunne konverteres til en stærk klassifikator. Svag lærer eller klassifikator er en lærer, der er bedre end tilfældig gætte, og dette vil være robust i for stor pasform som i et stort sæt svage klassifikatorer, hvor hver svag klassifikator er bedre end tilfældig. Som en svag klassifikator bruges generelt en simpel tærskel for en enkelt funktion. Hvis funktionen er over tærsklen end forudsagt, hører den til positive ellers hører til negativ.
AdaBoost står for 'Adaptive Boosting', der omdanner svage elever eller forudsigere til stærke prediktorer for at løse klassificeringsproblemer.
Ved klassificering kan den endelige ligning sættes som nedenfor: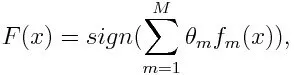
Her betegner f m den m. Svage klassificering og m repræsenterer dens tilsvarende vægt.
Hvordan fungerer AdaBoost-algoritme?
AdaBoost kan bruges til at forbedre ydelsen til maskinlæringsalgoritmer. Det bruges bedst med svage elever, og disse modeller opnår høj nøjagtighed over tilfældig chance for et klassificeringsproblem. De almindelige algoritmer med AdaBoost, der anvendes, er beslutningstræer med niveau 1. En svag lærer er en klassifikator eller prediktor, der klarer sig relativt dårligt med hensyn til nøjagtighed. Det kan også antydes, at de svage elever er enkle at beregne, og mange forekomster af algoritmer kombineres for at skabe en stærk klassifikator gennem boosting.
Hvis vi tager et datasæt, der indeholder et antal point, og overveje nedenstående
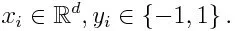
-1 repræsenterer negativ klasse og 1 angiver positiv. Det initialiseres som nedenfor, vægten for hvert datapunkt som:
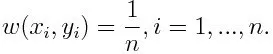
Hvis vi overvejer iteration fra 1 til M for m, får vi følgende udtryk:
Først skal vi vælge den svage klassifikator med den laveste vægtede klassificeringsfejl ved at tilpasse de svage klassifikatorer til datasættet.
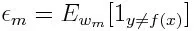
Derefter beregnes vægten for den m. Svage klassificering som nedenfor:
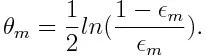
Vægten er positiv for enhver klassifikator med en nøjagtighed på over 50%. Vægten bliver større, hvis klassificeringsenheden er mere nøjagtig, og den bliver negativ, hvis klassificeringsenheden har nøjagtighed mindre end 50%. Forudsigelsen kan kombineres ved at invertere tegnet. Ved at invertere forudsigelsens tegn kan en klassificering med 40% nøjagtighed konverteres til en nøjagtighed på 60%. Så klassificeren bidrager til den endelige forudsigelse, selvom den klarer sig dårligere end tilfældig gætte. Den endelige forudsigelse vil dog ikke have noget bidrag eller få oplysninger fra klassificeren med nøjagtigt 50% nøjagtighed. Eksponentielt udtryk i tælleren er altid større end 1 for en forkert klassificeret sag fra den positive vægtede klassificer. Efter iteration opdateres de forkert klassificerede sager med større vægt. De negativt vægtede klassifikatorer opfører sig på samme måde. Men der er forskel på, at efter at skiltet er vendt; de korrekte klassificeringer oprindeligt ville konvertere til mis-klassificering. Den endelige forudsigelse kan beregnes ved at tage hensyn til hver klassifikator og derefter udføre summen af deres vægtede forudsigelse.
Opdatering af vægten for hvert datapunkt som nedenfor:
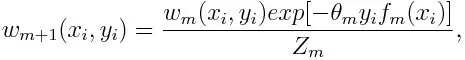
Z m er her normaliseringsfaktoren. Det sørger for, at summen af alle instansvægte bliver lig med 1.
Hvad bruges AdaBoost-algoritme til?
AdaBoost kan bruges til ansigtsregistrering, da det ser ud til at være standardalgoritmen til ansigtsregistrering i billeder. Den bruger en afvisningskaskade, der består af mange lag klassificeringsmaskiner. Når detektionsvinduet ikke genkendes på noget lag som et ansigt, afvises det. Den første klassificering i vinduet kasserer det negative vindue og holder beregningsomkostningerne på et minimum. Selvom AdaBoost kombinerer de svage klassifikatorer, bruges AdaBoost's principper også til at finde de bedste funktioner, der skal bruges i hvert lag af kaskaden.
Fordele og ulemper ved AdaBoost-algoritme
En af de mange fordele ved AdaBoost-algoritmen er, at den er hurtig, enkel og nem at programmere. Det har også fleksibiliteten til at blive kombineret med en hvilken som helst maskinlæringsalgoritme, og der er ikke behov for at indstille parametrene bortset fra T. Det er blevet udvidet til at lære problemer ud over binær klassificering, og det er alsidigt, da det kan bruges med tekst eller numerisk data.
AdaBoost har også få ulemper, som det er fra empirisk bevis og især sårbar over for ensartet støj. Svage klassifikatorer, der er for svage, kan føre til lave marginer og overmasse.
Eksempel på AdaBoost-algoritme
Vi kan overveje et eksempel på optagelse af studerende til et universitet, hvor enten de vil blive optaget eller nægtet. Her kan de kvantitative og kvalitative data findes fra forskellige aspekter. F.eks. Kan resultatet af optagelsen, der kan være ja / nej, være kvantitativt, hvorimod ethvert andet område som færdigheder eller hobbyer for studerende kan være kvalitativt. Vi kan let komme frem til den rigtige klassificering af træningsdata bedre end chancen for forhold som hvis eleven er god til et bestemt emne, så bliver hun / han optaget. Men det er svært at finde meget nøjagtig forudsigelse, og så kommer svage elever ind i billedet.
Konklusion
AdaBoost hjælper med at vælge træningssættet for hver nye klassifikator, der trænes på baggrund af resultaterne fra den foregående klassifikator. Også mens du kombinerer resultaterne; det bestemmer, hvor meget vægt der skal tildeles hver klassificeres foreslåede svar. Det kombinerer de svage elever for at skabe en stærk en til at rette klassificeringsfejl, som også er den første succesrige boostingalgoritme til binære klassificeringsproblemer.
Anbefalede artikler
Dette har været en guide til AdaBoost-algoritme. Her diskuterede vi konceptet, anvendelser, arbejde, fordele og ulemper med eksempel. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Naive Bayes algoritme
- Spørgsmål til marketingmedier om sociale medier
- Link Building Strategies
- Platform for sociale medier