

Hvad er datamodellering
Kort sagt henviser datamodellering til at opbygge en datamodel, der kan gemmes i en eller anden database. Datamodellen er en konceptuel repræsentation af en tilknytning mellem forskellige dataobjekter.
Forståelse af datamodellering / rækkevidde
Det forekommer i tre forskellige lag:
- Fysisk model: Det er et skema, der siger, hvordan data lagres fysisk i databasen
- Konceptuel model: Det er brugervisningen af dataene, dvs. det høje niveau, som brugeren ser.
- Logisk model: Den sidder mellem den fysiske model og den konceptuelle model, og den repræsenterer dataene logisk adskilt fra dens fysiske butikker.
Hierarkisk datamodellering: Disse modeller blev brugt til at erstatte filbaserede systemer. Dataene blev opbevaret i et træ som en for mange arrangementer.
Relationsdatamodellering: Det er sandt, at den hierarkiske model hjalp os med at bevæge os fra filbaserede systemer, som reducerede kompleksiteten, men stadig havde kendt den anvendte fysiske datalagring. Den relationelle database følger den relationelle model, hvor data gemmes i tabeller, i modsætning til hierarkisk database, hvor de er gemt i en trælignende struktur. Kort sagt reducerede det kompleksiteten mere sammenlignet med den hierarkiske model.
Hvordan gør datamodellering arbejde så let / hvorfor skal vi bruge det?
Det hjælper os med en visuel repræsentation af data og håndhæver forretningslogik, regler, politikker osv. Om data. Det er en guide, der bruges af forskere og analytikere til design og implementering af en database. Så uden datamodellering bliver analytikernes og forskeres job til at implementere forretningskravene til databasen vanskelig.
Hvorfor har vi brug for datamodellering? / Hvad kan du gøre med det?
Hovedmålet med at bruge det er:
- For at sikre, at alle dataobjekter er repræsenteret korrekt, som om det ikke gøres korrekt, får vi forkerte resultater.
- Det hjælper som nævnt tidligere med at designe database på konceptuelle, fysiske og logiske niveauer.
- Det hjælper med at designe relationstabeller, primære nøgler, fremmednøgler osv.
- Databaseudviklere kan oprette en bedre fysisk database med en god model, da den bliver et vejledende værktøj for dem.
- Det hjælper med at identificere manglende og overflødige data.
- Det hjælper os med at have en bedre it-infrastruktur og at have let og billig vedligeholdelse, når det kræves i det lange løb, selvom det oprindeligt er tidskrævende.
Arbejder med datamodellering
Lad os nu oprette en eksempeldatamodel for at forstå, hvordan man arbejder med en model. For at gøre dette er vi nødt til at følge visse trin:
- Først skal vi forstå kravene. I dette tilfælde opretter vi en model til en online butik. Så husk at vi har brug for to borde a) kunder b) produkter
- Det næste trin er at få attributterne til tabellerne eller enhederne
en. kundetabel kan have attributter som:
- Id
- Navn
- Adresse
b. Produkttabel kan have attributter som:
- Id
- Navn
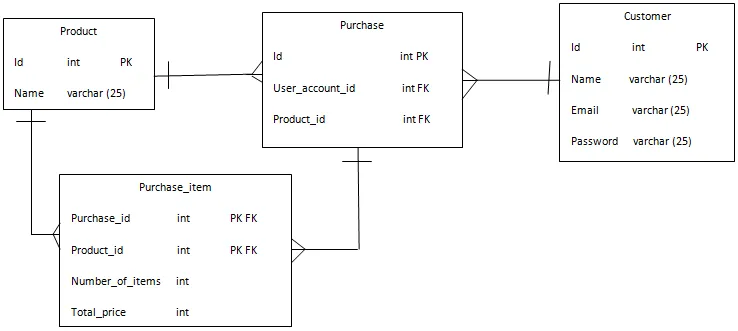
I kundetabellen kan vi have id som primærnøgle, og lignende produkt-id i produkttabellen vil være den primære nøgle som vist i nedenstående diagrammer.

Nu vil vi designe forholdet mellem disse to tabeller. Så for at forbinde kunde- og produkttabellen vil vi oprette en tabel kaldet køb, der vil være som en ordrestabel (dvs. hvilken kunde bestilte hvilket produkt).

Hvis du ser på figuren ovenfor, er referencen til kundekøb OK, fordi hvert køb har en kunde, og en kunde har mange køb. Så denne henvisning er okay. En ting mere har vi taget user_account_id som en fremmed nøgle (henvisningen til id'et i kundenøglen). Tilsvarende produkt_id. Der er stadig et problem med reference til produktkøb, da flere produkter kan købes i et køb, ligesom flere køb kan omfatte det samme produkt.
For at overvinde dette vil vi designe en mellemliggende tabel kendt som purchase_item, som vil være forbundet med køb og produkt. I nedenstående figur kan vi se problemet løst.
Fordele
Der er forskellige fordele er som følger:
- Det hjælper virksomheder med at kommunikere, planlægge på tværs af deres organisation.
- Det hjælper med at genkende den rigtige datakilde, der kan bruges til at udfylde modellen.
- Dette kan bruges til at definere forhold mellem forskellige tabeller som primær nøgle, fremmed nøgle osv.
Hvem er det rigtige publikum til at lære denne teknologi?
Det er meget vigtigt. De rigtige målgrupper til at lære modelleringsteknikker er personer, der er dataarkitekter og dataanalytikere. De fleste personer starter som dataanalytikere og bevæger sig derefter op ad stigen.
Hvordan denne teknologi vil hjælpe dig i karrierevækst?
Ifølge Glassdoor forventes den gennemsnitlige løn på markedet for modellerere at tjene ca. $ 78.601 i gennemsnit. Så du kan se, at det er et godt betalt job. De fleste store virksomheder investerer i modellerere, da de er meget vigtige for at bevare dataarkets integritet.
Konklusion
Afslutningsvis kan vi sige, at modellen, der er oprettet af modellerere, sikrer konsistens i navngivning af konventioner, integritet og sikkerhed for data. fordi gode data giver virksomheden mulighed for korrekt udnyttelse af deres data.
Anbefalede artikler
Dette har været en guide til Hvad er datamodellering. Her diskuterede vi definitionen, karrierevækst, færdigheder, fordele og Working of Data Modeling ved hjælp af eksempler. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Hvad er Agile Project Management?
- Spørgsmål om datavarehousing-interview
- Hvad er SAS?
- Hvad er Big Data Technology?
- Vejledning til datamodel i Cassandra