

Introduktion til Python Pandas DataFrame
Flere udvidelser til Python-biblioteket, Pandas, kan findes online. En sådan er Paneldata (pan) Data (das). Dette ord, * Panel * antyder subtilt en 2-dimensionel datastruktur, der findes i dette bibliotek, hvilket giver brugerne en enorm styrke. Netop denne struktur kaldes en DataFrame.
Det er hovedsageligt en matrix af rækker og kolonner, der indeholder hele datasættet, med meget detaljerede indstillinger til indeksering af det samme. DataFrame (DF) kan forestilles billedmæssigt meget lig et excelark. Men det, der gør det kraftfuldt, er den lethed, hvorpå analytiske og transformationelle operationer kan udføres på de data, der er gemt i en DataFrame.
Hvad er nøjagtigt en Python Pandas DataFrame?
Pydata-siden kan henvises til noget af en officiel definition.
Hvis den forstås korrekt, nævner den DataFrame som en kolonnestruktur, der er i stand til at gemme ethvert python-objekt (inklusive et DataFrame i sig selv) som en celleværdi. (En celle indekseres ved hjælp af en unik række & kolonne-kombination)
DataFrames består af tre essentielle komponenter: data, rækker og kolonner.
- Data: Det henviser til de faktiske objekter / enheder, der er gemt i en celle i DataFrame og de værdier, der er repræsenteret af disse enheder. Et objekt er af en gyldig python-datatype, hvad enten det er indbygget eller brugerdefineret.
- Rækker: Henvisninger, der bruges til at identificere (eller indeksere) et bestemt sæt observationer fra de komplette data, der er gemt i en DataFrame, kaldes Rækkerne. Bare for at gøre det klart repræsenterer det de anvendte indekser og ikke kun dataene i en bestemt observation.
- Kolonner: Henvisninger, der bruges til at identificere (eller indeksere) et sæt attributter til alle observationer i en DataFrame. Som for rækker henviser disse til kolonneindekset (eller kolonneoverskrifterne) i stedet for kun dataene i kolonnen.
Så uden yderligere problemer, lad os prøve nogle måder at skabe disse meget magtfulde strukturer.
Trin til oprettelse af Python Pandas DataFrames
En Python Pandas DataFrame kan oprettes ved hjælp af følgende kodeimplementering,
1. Importer pandaer
For at oprette DataFrames skal panda-biblioteket importeres (ingen overraskelse her). Vi importerer det med et alias pd for nemt at referere til objekter under modulet.
Kode:
import pandas as pd
2. Oprettelse af det første DataFrame-objekt
Når biblioteket er importeret, er alle metoder, funktioner og konstruktører tilgængelige i dit arbejdsområde. Så lad os forsøge at oprette en vanille DataFrame.
Kode:
import pandas as pd
df = pd.DataFrame()
print(df)
Produktion:
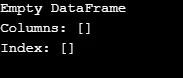
Som vist i output returnerer konstruktøren en tom DataFrame.
Lad os nu fokusere på at oprette DataFrames ud fra data, der er gemt i nogle af de sandsynlige repræsentationer.
- DataFrame fra en ordbog: Lad os sige, at vi har en ordbog, der lagrer en liste over virksomheder i softwaredomæne, og antallet af år, de har været aktive.
Kode:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Lad os se repræsentationen af det returnerede DataFrame-objekt ved at udskrive det på konsollen.
Produktion:

Som det ses, behandles hver nøgle i ordbogen som en søjle i DataFrame, og rækkeindekserne genereres automatisk fra 0. Pretty easy he!
Lad os nu sige, at du ville give det et tilpasset indeks i stedet for 0, 1, .. 4. Du skal bare videregive den ønskede liste som en parameter til konstruktøren, og pandaer gør det nødvendigt.
Kode:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Produktion:
Virksomhedens alder
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Nu kan du indstille rækkeindekser til en hvilken som helst ønsket værdi.
- DataFrame fra en CSV-fil: Lad os oprette en CSV-fil, der indeholder de samme data som i vores ordbog. Lad os kalde filen CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Filen kan indlæses i en dataframe (forudsat at den findes i det aktuelle arbejdsmappe) som følger.
Kode:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Produktion:
Virksomhedens alder
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Indstilling af parameternavne , omgåelse af en liste med værdier, tildeler dem som kolonneoverskrifter i den samme rækkefølge, som de er til stede på listen. Tilsvarende kan rækkeindekser indstilles ved at sende en liste til indeksparameteren, som vist i det foregående afsnit. Overskriften = Ingen angiver manglende kolonneoverskrifter i datafilen.
Lad os nu sige, at kolonnenavnene var en del af datafilen. Derefter indstiller header = False udfører det krævede job.
3. CompanyAgeWithHeader.csv
Virksomhed, alder
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Koden ændres til
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Produktion:
Virksomhedens alder
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame fra en Excel-fil: Ofte deles data i excel-filer, da det forbliver det mest populære værktøj, der bruges af almindelige folk til Adhoc-sporing. Derfor bør det ikke ignoreres af vores diskussion.
Lad os antage, at dataene, som i CompanyAgeWithHeader.csv, nu er gemt i CompanyAgeWithHeader.xlsx, i et ark med navnet Company Age. Den samme DataFrame som ovenfor oprettes med følgende kode.
Kode:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Produktion:
Virksomhedens alder
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Som du kan se, kan den samme DataFrame oprettes ved at angive filnavnet og arknavnet.
Yderligere læsning og næste trin
De viste metoder udgør en meget lille undergruppe i sammenligning med alle de forskellige måder DataFrames kan oprettes. Disse blev oprettet med den hensigt at komme i gang. Du bør bestemt udforske de nævnte referencer og forsøge at udforske andre måder, herunder oprette forbindelse til en database for at læse data fra direkte ind i en DataFrame.
Konklusion
Pandas DataFrame har vist sig at være en spiludveksler i verden af Data Science og Data Analytics såvel som det er praktisk til ad-hoc kortvarige projekter. Det leveres med en hær af værktøjer, der er i stand til at skære og terning af datasættet med ekstrem lethed. Forhåbentlig vil dette tjene som et springbræt i din fremtidige rejse.
Anbefalede artikler
Dette er en guide til Python-Pandas DataFrame. Her diskuterer vi trinnene til oprettelse af python-pandas dataframe sammen med dens kodeimplementering. Du kan også se på de følgende artikler for at lære mere -
- Top 15 funktioner i Python
- Forskellige typer af Python-sæt
- Top 4 typer af variabler i Python
- Top 6 redaktører af Python
- Arrays i datastruktur