
Introduktion til dataanalyseteknikker
I det 21. århundrede er dataanalyse et af de mest anvendte ord i hvert domæne. Så lad os i dag se, hvad betyder alle med dataanalyse og nogle vigtige teknikker i dataanalyse. Dataanalyse er processen med at inspicere, rense, transformere og modellere data med det formål at opdage nyttige oplysninger, der kan gøre beslutningen bedre. I 2019 sagde økonomen, ”Verdens mest værdifulde aktiv er ikke længere olie, men DATA”. Dataanalyse er tæt knyttet til datavisualisering. Baseret på den mængde data, som industrierne genererer hvert minut, og baseret på deres behov er der en række teknikker, der kom til. Lad os se, hvad de er i det næste afsnit. I dette emne skal vi lære om typer af dataanalyseteknikker.
Vigtige typer af dataanalyseteknikker
Dataanalyseteknikker klassificeres stort set i to typer, de er
- Metoder baseret på matematiske og statistiske fremgangsmåder
- Metoder baseret på kunstig intelligens og maskinlæring
Matematiske og statistiske tilgange
1. Beskrivende analyse: Beskrivende analyse er et vigtigt første skridt til udførelse af statistisk analyse. Det giver os en idé om distributionen af data, hjælper med at opdage outliers og gør det muligt for os at identificere foreninger mellem variabler og således forberede dataene til udførelse af yderligere statistisk analyse. Beskrivende analyse af et enormt datasæt kan gøres let ved at opdele det i to kategorier, de er beskrivende analyser for hver individuel variabel og beskrivende analyse for kombinationer af variabler.
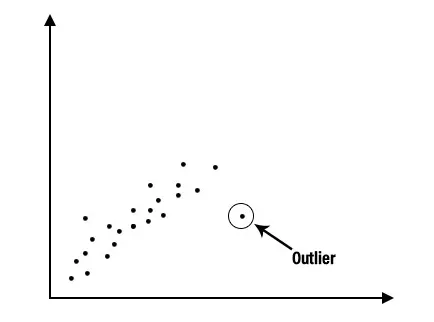
2. Regressionsanalyse: Regressionsanalyse er en af de dominerende teknikker til dataanalyse, der bruges i branchen lige nu. I denne form for teknik kan vi se forholdet mellem to eller flere variabler af interesse og i kernen, de studerer alle påvirkningen af en eller flere uafhængige variabler på den afhængige variabel. For at se, om der er noget forhold mellem variablerne eller ej, er vi først nødt til at plotte dataene på et diagram, og det vil være tydeligt, om der er nogen relation. Overvej for eksempel grafen, der er afbildet nedenfor, for at have en klar forståelse.
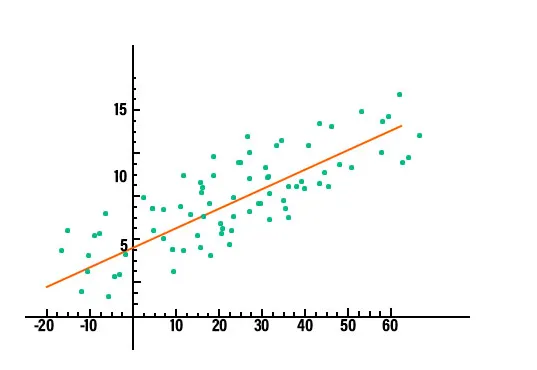
I data mining anvendes denne teknik til at forudsige værdierne for en variabel i det pågældende datasæt. Der er forskellige typer regressionsmodeller i brug. Et par af dem er lineær regression, logistisk regression og multiple regression.
3. Spredningsanalyse: Spredning er det omfang, en distribution strækkes eller klemmes på. I den matematiske tilgang kan spredningen defineres på to måder, grundlæggende forskellen mellem værdier imellem sig og for det andet forskellen mellem gennemsnitsværdien. Hvis forskellen mellem værdien og gennemsnittet er meget lav, kan vi sige, at spredning er mindre i dette tilfælde. Og nogle af de almindelige målinger for spredning er varians, standardafvigelse og interkvartilt interval.
4. Faktoranalyse: Faktoranalyse er en slags dataanalyseteknik, som hjælper med at finde den underliggende struktur i et sæt af variabler. Det hjælper med at finde uafhængige variabler i datasættet, der beskriver mønstre og modeller af relationer. Det er det første skridt i retning af klynge- og klassificeringsprocedurer. Faktoranalyse er også relateret til Principal Component Analysis (PCA), men begge af dem er ikke identiske, vi kan kalde PCA som den mere basale version af udforskende faktoranalyse
5. Tidsserier: Tidsserieranalyse er en dataanalyseteknologi, der beskæftiger sig med tidsseriedata eller trendanalyse. Lad os nu forstå, hvad der er tidsseriedata? Tidsseriedata er data i en række bestemte tidsintervaller eller perioder. Hvis vi ser videnskabeligt, udføres de fleste af målingerne over tid.
Metoder baseret på maskinlæring og kunstig intelligens
1. Beslutningstræer: Beslutningstræanalyse er en grafisk repræsentation, der ligner en trælignende struktur, hvor problemerne i beslutningstagningen kan ses i form af et rutediagram, hver med grene til alternative svar. Beslutningstræer er en top-down tilgangstype, med den første beslutningsnode øverst, baseret på svaret på den første beslutningsnode, vil den blive opdelt i grene, og den vil fortsætte, indtil træet træffer en endelig beslutning. De grene, der ikke deler sig mere, kaldes blade.
2. Neurale netværk: Neurale netværk er et sæt algoritmer, der er designet til at efterligne den menneskelige hjerne. Det er også kendt som ”Netværket af kunstige neuroner”. Anvendelser af neuralt netværk i data mining er meget brede. De har en høj acceptfunktion for støjende data og resultater med høj nøjagtighed. Baseret på nødvendigheden bruges i øjeblikket mange typer af neurale netværk, få af dem er tilbagevendende neurale netværk og indviklede neurale netværk. Konventionelle neurale netværk bruges mest til billedbehandling, naturligt sprogbehandling og anbefalingssystemer. Gentagne neurale netværk bruges hovedsageligt til håndskrift og talegenkendelse.
3. Evolutionsalgoritmer: Evolutionsalgoritmer bruger mekanismerne inspireret af rekombination og selektion. Disse typer algoritmer er uafhængige af domænet, og de har evnen til at udforske store datasæt, opdage mønstre og løsninger. De er ufølsomme over for støj sammenlignet med andre datateknikker.
4. Fuzzy logik: Det er en tilgang i computing baseret på "Grad af sandhed" snarere end den almindelige "Boolske logik" (sandhed / falsk eller 0/1). Som omtalt ovenfor i beslutningstræer ved beslutningsknudepunkt har vi enten ja eller nej som svar, hvad nu hvis vi har en situation, hvor vi ikke kan beslutte absolut ja eller absolut nej? I disse tilfælde spiller fuzzy logik en vigtig rolle. Det er en mangfoldig værdsat logik, hvor sandhedsværdien kan være mellem helt sand og fuldstændig falsk, dvs.
Konklusion
Det hårde spørgsmål, som alle virksomheder eller virksomheder står overfor, er, hvilken type dataanalyseteknik der er bedst for dem? Vi kan ikke definere nogen teknik som den bedste i stedet for, hvad vi kan gøre, er at prøve flere teknikker og se, hvilken der bedst passer til vores datasæt og bruge det. Ovennævnte teknikker er nogle af de vigtige teknikker, der i øjeblikket bruges i branchen.
Anbefalede artikler
Dette er en guide til typer af dataanalyseteknikker Her diskuterer vi de typer af dataanalyseteknikker, der i øjeblikket bruges i branchen. Du kan også se på de følgende artikler for at lære mere -
- Data Science værktøjer
- Data Science Platform
- Data Science Karriere
- Big Data Technologies
- Klynge i maskinlæring
- Fuzzy Logic System | Hvornår skal du bruge, Arkitektur
- Komplet guide til implementering af neurale netværk
- Hvad er dataanalyse?
- Opret beslutningstræ med fordele
- Vejledning til forskellige typer dataanalyse