
Forskellen mellem Hadoop og Redshift
Hadoop er en open-source ramme udviklet af Apache Software Foundation med dens vigtigste fordele ved skalerbarhed, pålidelighed og distribueret computing. Databehandling, opbevaring, adgang, sikkerhed er flere typer funktioner, der er tilgængelige på Hadoop økosystem. HDFS har en høj gennemstrømning, hvilket betyder, at det er muligt at håndtere store datamængder med parallel behandlingsevne. Redshift er en cloud-hostingwebtjeneste udviklet af Amazon Web Services-enhed inden for Amazon.com Inc., ud af de eksisterende tjenester leveret af Amazon. Det bruges til at designe et datalager i stor skala i skyen. Redshift er en datalagertjeneste i petabyte, der er fuldt styret og omkostningseffektiv at betjene på store datasæt.
Lad os studere mere om Hadoop og Redshift detaljeret:
Hadoop HDFS har stor fejltolerancefunktion og er designet til at køre på hardwaresystemer til lave omkostninger. Hadoop kan håndtere en minimumstypestørrelse af TeraBytes til GigaBytes af filer inden for sit system. HDFS er master-slave-arkitektur, der består af Navneknudepunkter og Datanoder, hvor Navneknudepunktet indeholder metadata, og Dataknudepunktet indeholder reelle data, der skal behandles eller betjenes.
RedShift bruger forskellige dataindlæsningsteknikker såsom BI (Business Intelligence) rapportering, analytiske værktøjer og data mining. Redshift giver en konsol til at oprette og administrere Amazon Redshift-klynger. Kernekomponenten i Redshift Data Warehouse er en klynge.
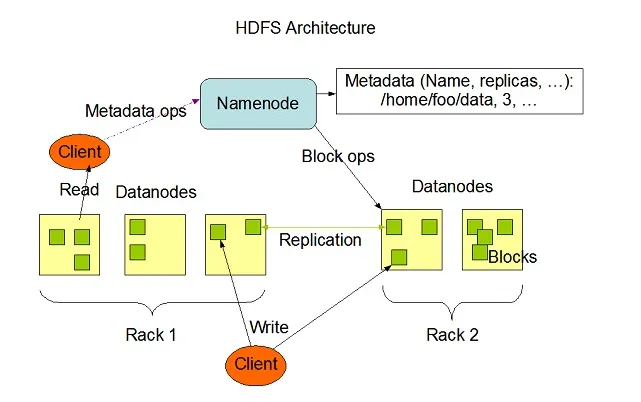
Billedkilde: Apache.org
RedShift-arkitektur:
 Billedkilde: Amazon.com
Billedkilde: Amazon.com
Head-to-head-sammenligning mellem Hadoop vs Redshift (Infographics):
Nedenfor er top 10-sammenligningen mellem Hadoop og Redshift som følger

De vigtigste forskelle mellem Hadoop vs Redshift:
Nedenfor er de vigtigste forskelle mellem Hadoop vs Redshift som følgende
1. Hadoop HDFS (Hadoop Distribueret filsystem) Arkitektur har navnekoder og datakoder, mens Redshift har Leader Node og Compute Nodes, hvor Compute noder vil blive opdelt som skiver.
2. Hadoop leverer kommandolinjegrænseflade til interaktion med filsystem, hvorimod RedShift har management-konsol til at interagere med Amazon-lagringstjenester såsom S3, DynamoDB osv.,
3.Databaseoperationerne skal konfigureres af udviklere. I Redshift automatiserer databasefunktionerne ved at analysere eksekveringsplanerne.
4.Hadoop har flere tredjepartsværktøjsstøtter, der let kan integreres, mens Redshift kun understøtter de produkter, der er udviklet af Amazon i sin sky.
5. Med hensyn til Hadoop er arkitektonisk design, netværk, opbevaring, sikkerhed og ydeevne blevet betragtet som primære elementer, hvorimod disse elementer i Redshift let og fleksibelt kan konfigureres ved hjælp af Amazon cloud management konsol.
6.Hadoop er en filsystemarkitektur baseret på Java Application Programming Interfaces (API), mens Redshift er baseret på Relational model Database Management System (RDBMS).
7.Hadoop kan have integrationer med forskellige leverandører, og Redshift har ingen support i dette tilfælde, hvor Amazon er deres eneste leverandør. Hvad hvis en bruger er utilfreds med tjenesten? I dette tilfælde er Hadoop en fordel.
8. De fleste af de eksisterende virksomheder bruger stadig Hadoop, mens nye kunder vælger RedShift.
9. I termer mangler ydelse Hadoop altid bagefter, og Redshift vinder altid i tilfælde af udførelse af forespørgsler på store datamængder.
10.Hadoop bruger Map Reduce programmeringsmodel til at køre job. Amazon Redshift bruger Amazons Elastic Map Reduce.
11.Hadoop bruger Map Reduce programmeringsmodel til at køre job. Amazon Redshift bruger Amazons Elastic Map Reduce.
12.Hadoop foretrækkes at køre batchjob hver dag, der bliver billigere, mens Redshift kommer billigere ud i tilfælde af Online Analytical Processing (OLAP) teknologi, der findes bag mange Business Intelligence-værktøjer.
13.Hadoop er 10 gange langsommere end Redshift i at køre forespørgsler på den samme måde Hadoop er 10 gange dyrere end Redshift, hvilket resulterer i, at Hadoop blev mindst valgt inden Redshift.
14. Også hvad angår indlæsning af data har Hadoop været bag Redshift med hensyn til, hvis systemet tager timer for at indlæse data fra lageret i dets filbehandlingssystem.
15.Hadoop kan bruges til lave omkostningslagre, dataarkivering, datasøer, datalagring og dataanalyse, hvorimod Redshift hører under Datavarehovedfunktioner, der forårsager en begrænsning af brugen til flere formål.
16..Hoop-platform leverer support til forskellige eksterne leverandører og egne Apache-projekter såsom Storm, Spark, Kafka, Solr osv., Og på den anden side har Redshift begrænset integrationssupport med sine eneste Amazon-produkter
Hadoop vs Redshift sammenligningstabel
| GRUNDLÆGGELSE FOR
SAMMENLIGNING | Hadoop | rødforskydning |
| tilgængelighed | Open Source Framework af Apache Projects | Priser leveret af Amazon |
| Implementering | Leveret af Hortonworks og Cloudera-udbydere osv., | Udviklet og leveret af Amazon |
| Ydeevne | Hadoop MapReduce-job er langsommere | Redshift fungerer hurtigere end Hadoop-klyngen |
| Skalerbarhed | Begrænsninger i skalerbarhed | Let let ned / opdateres som pr. Krav |
| Prisfastsættelse | Koster $ 200 per måned for at køre forespørgsler | Prisen afhænger af serverområdet og billigere end Hadoop
F.eks .: $ 20 / måned |
| Hastighed | Hurtigere, men langsommere i forhold til Redshift | 10 gange hurtigere end Hadoop |
| Forespørgselshastighed | Det tager 1491 sekunder at køre 1.2TB data | 155 sekunder for at køre 1, 2 TB data |
| Dataintegration | Fleksibel med lokalt filsystem og enhver database | Kan kun indlæse data fra Amazon S3 eller DynamoDB |
| Dataformat | Alle dataformater understøttes | Strenge i dataformater som CSV-filformater |
| Brugervenlighed | Kompleks og vanskeligere at håndtere administrationsaktiviteter | Automatiseret backup og datalageradministration |
Konklusion - Hadoop vs Redshift
Den endelige erklæring for at afslutte den store vinder i denne sammenligning er Redshift, der vinder med hensyn til let betjening, vedligeholdelse og produktivitet, hvorimod Hadoop mangler med hensyn til ydeevne skalerbarhed og serviceomkostningerne med den eneste fordel ved nem integration med tredjepartsværktøjer og produkter. Redshift har for nylig udviklet sig med enorm vækst og accept af mange kunder og klienter på grund af dens høje tilgængelighed og mindre driftsomkostninger sammenlignet med Hadoop gør det mere og mere populært. Men indtil nu har de fleste af de eksisterende Fortune 1000-virksomheder brugt Hadoop-platforme i dens arkitekturer til at administrere kundedata.
I de fleste tilfælde har RedShift været det bedste valg at overveje til erhvervsmæssige formål af enhver klient eller kunde for at håndtere de store og følsomme data fra finansielle institutioner eller offentlige oplysninger med mere dataintegritet og sikkerhed.
Bortset fra dette har Hadoop sine egne fordele ved at være open source-projekt og havde været til rådighed i mange år også medføre, at de eksisterende systemer erstattes som en omkostningsproces. Produktet skal endelig vælges på baggrund af kravet og fleksibiliteten snarere end prisfastsættelse eller popularitet baseret på de drevne forretningsbehov.
Anbefalet artikel:
Dette har været en guide til Hadoop vs Redshift, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Hadoop vs Hive - Find ud af de bedste forskelle
- HADOOP vs RDBMS | Kend til de 12 nyttige forskelle
- Apache Hadoop vs Apache Spark | Top 10 sammenligninger, du skal vide!
- Big Data vs Data Science - Hvordan er de forskellige?
- Vejledning om Hadoop vs Spark
- Top 4 Cloud Hosting-udbydere med funktioner