

Hvad er Big Data og Hadoop?
Data vokser eksponentielt hver dag, og med sådanne voksende data kommer behovet for at bruge disse data. Ligesom i ældre dage plejede vi at have diskettedrev til at gemme data, og dataoverførslen var også langsom, men i dag er disse utilstrækkelige, og skylagring bruges, da vi har terabyte med data. I dagens verden har vi sociale medier, der bidrager højest i datavækst. Det består af folks adfærd, tankegang og flere andre aspekter. Det siges, at der i hvert minut uploades 300 timer video på YouTube, over 20 millioner fotos uploades på Facebook og mange andre. Der er desuden ingen korrekt struktur af de data, der uploades, hvilket er den største udfordring til behandling af disse data.
Da der genereres enorme data i høj hastighed, var traditionelle RDBMS-systemer ikke i stand til at håndtere så hurtig vækst. Desuden er de heller ikke i stand til at håndtere ustrukturerede data. Det blev meget vanskeligt at håndtere en så enorm mængde heterogene data, der voksede hurtigt og at behandle disse data med høj behandlingshastighed. Således kom der et behov for et sådant system, der er i stand til at håndtere store datasæt effektivt. Derfor kom Hadoop til at løse scenariet. HDFS er komponenten i Hadoop, der adresserede lagringsproblemer med det store datasæt ved hjælp af distribueret lagerplads, mens YARN er den komponent, der adresserede behandlingsproblemet, hvilket reducerer behandlingstiden drastisk.
Hadoop er en open source-softwareramme til lagring og behandling af store datasæt ved hjælp af en distribueret stor klynge af hardware til hardware. Det blev udviklet af Doug Cutting og Michael J. Cafarella og licenseret under Apache. Det er skrevet ved hjælp af Java og blev udviklet på baggrund af det papir, der er skrevet af Google om MapReduce-systemet, og det anvender koncepter med funktionel programmering. Det er pålideligt, økonomisk fleksibelt og skalerbart.
Kerneelementerne i Hadoop
Kerneelementerne i Hadoop er som følger
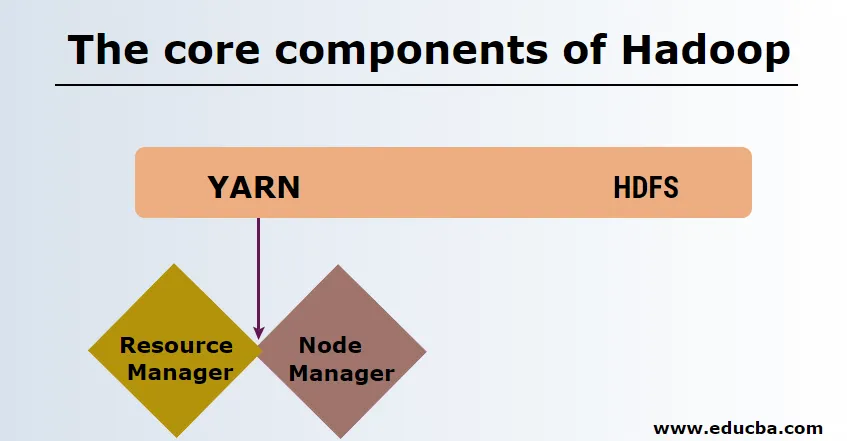
-
HDFS
HDFS eller Hadoop Distribueret filsystem har Namenode og dataknudepunkt. Namenode er masternoden, der kører master-dæmonen, og den administrerer dataknudepunkterne og holder styr på alle operationer. Datanoder er de slaver, hvor dataene faktisk lagres.
-
garn
YARN består af to hovedkomponenter:
1. ResourceManager: Den kører på masternoden og administrerer alle ressourcer og planlægger alle applikationer. Det har Scheduler & ApplicationManager.
2. NodeManager: Den kører på hver slaveknude og er ansvarlig for at styre containere og overvåge ressourceudnyttelse.
Flere komponenter af Hadoop
Der er adskillige komponenter i Hadoop som svin, bikube, sqoop, flume, mahout, oozie, zookeeper, HBase osv.
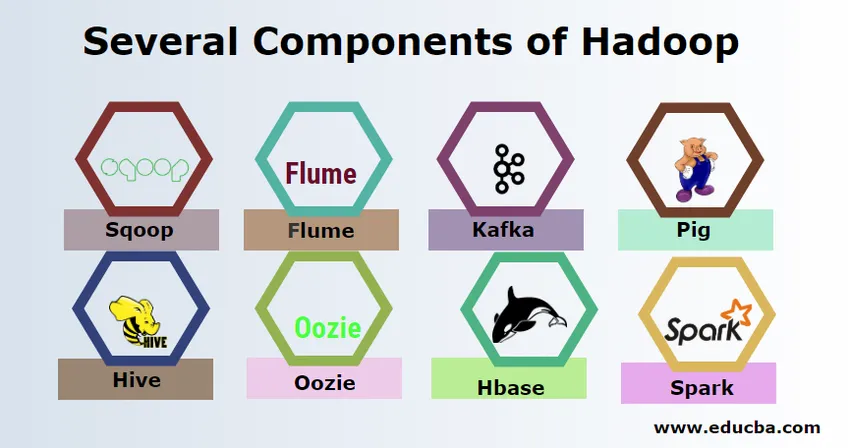
- Sqoop - Det bruges til at importere og eksportere data fra RDBMS til Hadoop og vice versa.
- Flume - Det bruges til at trække data i realtid ind i Hadoop.
- Kafka - Det er et meddelelsessystem, der bruges til at rute data i realtid til Hadoop.
- Pig - Det bruges som scriptingsprog til databehandling.
- Hive - Det er en datalagerramme, der bygger på HDFS, så brugere, der er bekendt med SQL, kan udføre forespørgsler for at hente dataene. Disse spørgsmål kaldes HiveQL.
- Oozie - Det bruges til at planlægge arbejdsgangen af job, der skal køres på specificerede begivenheder eller tid.
- Hbase - Det er den ingen SQL-database, der leveres som en del af Apache Hadoop.
- Spark - Det bruges til at udføre in-memory-behandling, som er meget hurtigere end Hadoop-kortreduktion.
Hadoop-udbydere
Der er mange virksomheder, der tilbyder Hadoop-distributioner. Nedenfor er de par bedste udbydere af Hadoop:
- Cloudera
- Hortonworks
- MapR
Der er få forudsætninger for at lære Hadoop. Tidligere erfaring med Java og scriptingsprog er nødvendig. Selvom Hadoop allerede har sine egne programmeringssprog på højt niveau som svin og bikube, der genererer backend-koden til yderligere behandling, er det stadig muligt at oprette eget kortreducerende program, hvilket som helst programmeringssprog som Ruby, Python, Perl og endda C-programmering.
Bigdata og Hadoop er i høj efterspørgsel på dagens marked. Dette vil stige mere i de kommende dage. Masser af organisationer er allerede flyttet ind i Hadoop, og de, der ikke har planer om at flytte snart. Der er en aktuel rapport om, at større virksomheder er begyndt at investere i big data-analyse. Prognose for Big Data-markedsføring er altid i opadgående tendens, og det er slet ikke en kortvarig tilstand. Bortset fra alle disse tilbyder jobene i Hadoop og big data altid en høj løn sammenlignet med andre teknologier.
Top Big Data og Hadoop virksomheder
Nedenfor er et par topfirmaer, der bruger flest antal Hadoop-ressourcer.
- Yahoo
- Amazon
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Der er mange virksomheder, der bruger big data-applikationer. Disse er:
-
Nokia
Det bruger Cloudera og Hadoop komponenter som HDFS, HBase, Sqoop, Scribe til applikationen. Den brugte brugerdata effektivt for at forstå og forbedre brugerens oplevelse. Det bruger databehandling og komplekse analyser til opbygning af kortet med forudsigelig trafik og lagdelte elevationsmodeller.
-
SAS
Det har samarbejdet med Hadoop for at hjælpe dataforskere med at få bedre indsigt ved at tilvejebringe et miljø, der giver visuel og interaktiv oplevelse og således hjælper med at udforske nye tendenser. De analytiske programmer udtrækker meningsfuld indsigt fra data, og in-memory-teknologien hjælper hurtigere datatilgang.
Der er også mange andre virksomheder, der bruger big data-platforme til forskellige analyser. Dette er flydata-analyse af black box i luftfartsindustrien, de forskellige analyser i aktiemarkedet osv.
Fordele ved Haddop
Nedenfor er et par af fordelene ved Hadoop
- Skalerbar - I modsætning til traditionel RDBMS er det en meget skalerbar platform, da den kan gemme store datasæt i distribuerede klynger over råvaremateriale, der fungerer parallelt.
- Omkostningseffektiv - Omkostningerne var for høje til, at RDBMS kunne gemme data, der er lettet i Hadoop.
- Hurtig og fleksibel - Det giver data, der skal fås adgang til hurtigt via det distribuerede filsystem. Det tilbyder også at udlede forretningsindsigt fra semistrukturerede og ustrukturerede data.
- Fejltolerant - Hver gang nogen data sendes til en knude, kopieres de samme data til andre noder, der kan fås i tilfælde af fejl i den første knude.
Konklusion - hvad er Big Data og Hadoop
Data vokser konstant, og der er derfor altid behov for big data og Hadoop for at give mening ud af disse data. Af denne grund vil fagfolk med Hadoop-færdigheder altid finde rigelige muligheder i de kommende dage og kan være et vigtigt aktiv for en organisation, der øger forretningen og deres karriere.
Anbefalede artikler
Dette har været en guide til hvad der er Big Data og Hadoop. Her har vi drøftet de grundlæggende koncepter og komponenter i Big Data og Hadoop. Du kan også se på den følgende artikel for at lære mere -
- Eksempler på Big Data Analytics
- Anvendelser af Hadoop
- Vejledning til datavisualisering
- Hvad er Big data analytics?