

Introduktion til BFS-algoritme
For at få adgang til og administrere dataene effektivt kan de gemmes og organiseres i et specielt format kendt som datastrukturen. Der er mange datastrukturer såsom stak, matrix, tilknyttet liste, køer, træer og grafer osv. I lineære datastrukturer, såsom stak, matrix, tilknyttet liste og kø, er dataene organiseret i lineær rækkefølge, hvorimod i ikke- lineære datastrukturer som træer og grafer, er data organiseret hierarkisk ikke i en rækkefølge. Grafen er en ikke-lineær datastruktur, der har knudepunkter og kanter. Knudepunkter i graf kan også benævnes knudepunkter, der er endelige i antal og kanter er forbindelseslinierne mellem to noder.
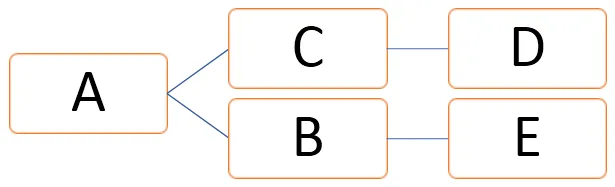
I ovenstående graf kan vertices repræsenteres som V = (A, B, C, D, E) og kanter kan defineres som
E = (AB, AC, CD, BE)
Hvad er BFS-algoritmen?
Der er generelt to algoritmer, der bruges til at krydse en graf. Det er BFS (bredde-første søgning) og DFS (dybde første søgning) algoritmer. Traversal of the Graph besøger nøjagtigt en gang hver toppunkt eller knude og kant i en veldefineret rækkefølge. Det er også meget vigtigt at holde styr på de hjørner, de er blevet besøgt, så den samme toppunkt ikke krydses to gange. I Breath First Search-algoritmen starter traverseringen fra en valgt knude eller kildeknudepunkt, og gennemgangen fortsætter gennem de knudepunkter, der er direkte forbundet med kildeknuden. I enklere vendinger skal man i BFS-algoritme først bevæge sig vandret og krydse det aktuelle lag, hvorefter det flyttes til det næste lag skal udføres.
Hvordan fungerer BFS-algoritme?
Lad os tage eksemplet med nedenstående graf.
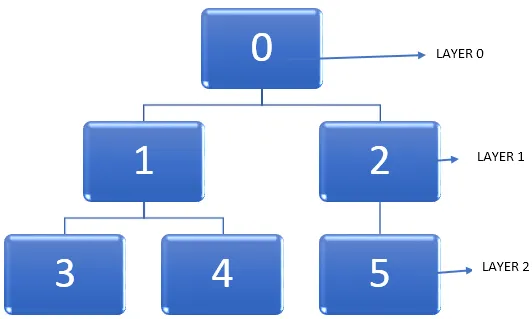
Den vigtige opgave er at finde den korteste sti i en graf, mens du krydser noder. Når vi går gennem en graf, går toppunktet fra uopdaget tilstand til opdaget tilstand og bliver til sidst helt opdaget. Det skal bemærkes, at det er muligt at sidde fast på et tidspunkt, mens man går gennem en graf og en knude kan besøges to gange. Så vi kan bruge en metode til at markere knudepunkterne, efter at den ændrer tilstanden af at være uopdaget til at blive helt opdaget.
Vi kan i nedenstående billede se, at knudepunkterne kan markeres i graferne, når de bliver helt opdaget ved at markere dem med sort. Vi kan starte ved kildeknudepunktet, og når traversalen skrider frem gennem hver knude, kan de markeres for at blive identificeret.
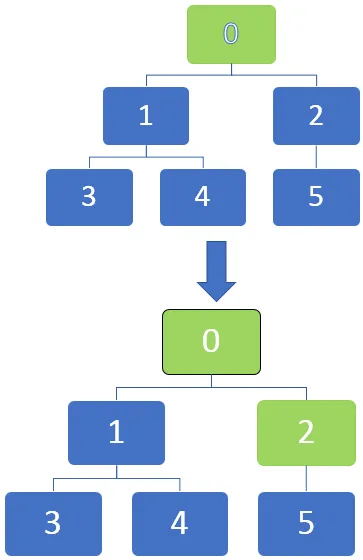
Traversalen starter fra et toppunkt og kører derefter til de udgående kanter. Når en kant går til et uopdaget toppunkt, markeres det som opdaget. Men når en kant går til et helt opdaget eller opdaget toppunkt, ignoreres det.
For en rettet graf besøges hver kant en gang, og for ikke-rettet graf besøges den to gange, dvs. en gang, mens du besøger hver knude. Den algoritme, der skal bruges, besluttes på baggrund af, hvordan de opdagede hjørner gemmes. I BFS-algoritmen bruges køen, hvor den ældste toppunkt først opdages og derefter spreder sig gennem lagene fra startpunktet.
Trin udføres for en BFS-algoritme
De nedenstående trin udføres for en BFS-algoritme.
- I en given graf, lad os starte fra et toppunkt, dvs. i ovenstående diagram er det knudepunkt 0. Niveauet, hvor dette toppunkt er til stede, kan betegnes som lag 0.
- Det næste trin er at finde alle de andre vertikater, der støder op til udgangspunktet, dvs. knudepunkt 0 eller umiddelbart tilgængeligt derfra. Derefter kan vi markere disse tilstødende hjørner, der skal være til stede i lag 1.
- Det er muligt at komme til samme toppunkt på grund af en løkke i grafen. Så vi skulle kun rejse til de højdepunkter, der skal være til stede i det samme lag.
- Dernæst markeres forældrekunktet for det aktuelle toppunkt, som vi befinder os i. Det samme skal udføres for alle toppunktene i lag 1.
- Derefter er det næste trin at finde alle de nævnte hjørner, der er en enkelt kant væk fra alle toppunktene, der er i lag 1. Disse nye sæt af knudepunkter vil være i lag 2.
- Ovenstående proces gentages, indtil alle knudepunkter er krydset.
Eksempel:
Lad os tage eksemplet med nedenstående graf og forstå, hvordan BFS-algoritmen fungerer. Generelt i en BFS-algoritme bruges en kø til at sætte knudepunkter i kø, mens de krydser noder.
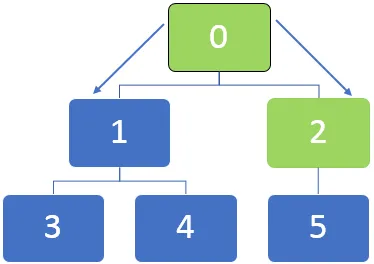
I ovenstående graf skal først knudepunktet 0 besøges, og denne knude er i kø til nedenstående kø:

Efter at have besøgt knudepunktet 0 er naboknappen 0, 1 og 2 i kø. Køen kan repræsenteres som nedenfor: 
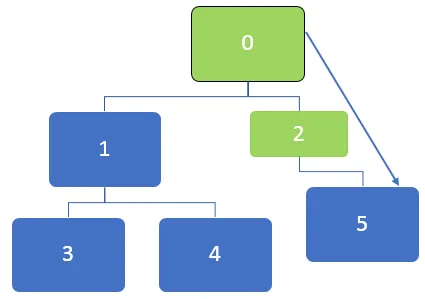
Derefter besøges den første knude i køen, der er 2. Efter at knudepunkt 2 er besøgt, kan køen repræsenteres som nedenfor:

Efter at have besøgt knudepunktet 2, vil 5 blive sat i kø, og da der ikke er nogen uanmeldte tilstødende knudepunkter for knudepunkt 5, er der dog stadig 5 i kø, men det vil ikke blive besøgt to gange.
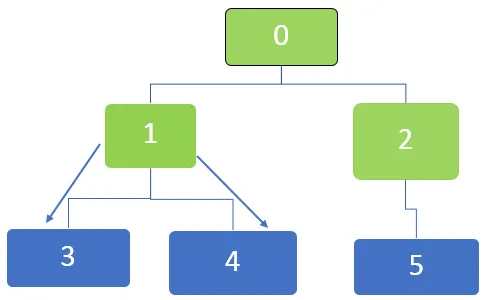
Dernæst er den første knude i køen 1, som vil blive besøgt. De nærliggende knudepunkter 3 og 4 er i kø. Køen er repræsenteret som nedenfor

Dernæst er den første knude i køen 5, og for denne knude er der ikke flere uudtalte nabosteder. Det samme gælder for knudepunkter 3 og 4, som der ikke er flere uudtalte nabosteder til.
Så alle noder krydses, og til sidst bliver køen tom.

Konklusion
Algoritme med bredde-søgning har nogle store fordele ved at anbefale den. En af de mange applikationer i BFS-algoritmen er at beregne den korteste sti. Det bruges også i netværk til at finde nabolande-knudepunkter og kan findes på sociale netværkswebsteder, netværksudsendelser og affaldsindsamling. Brugerne skal forstå kravet og datamønsteret for at bruge det til bedre ydeevne.
Anbefalede artikler
Dette har været en guide til BFS-algoritmen. Her diskuterer vi konceptet, arbejdet, trinene og eksemplet på ydeevne i BFS-algoritme. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Hvad er en grådig algoritme?
- Strålesporingsalgoritme
- Digital signaturalgoritme
- Hvad er Java Dvale?
- Digital signatur kryptografi
- BFS VS DFS | Top 6 forskelle med infografik