
Introduktion til forstærkningslæring
Forstærkningslæring er en type maskinlæring, og det er derfor også en del af kunstig intelligens, når de anvendes til systemer, udfører systemerne trin og lærer baseret på resultatet af trin for at opnå et komplekst mål, der er sat for, at systemet skal nå.
Forstå forstærkningslæring
Lad os forsøge at arbejde under forstærkningslæring ved hjælp af 2 tilfælde af enkel brug:
Sag nr. 1
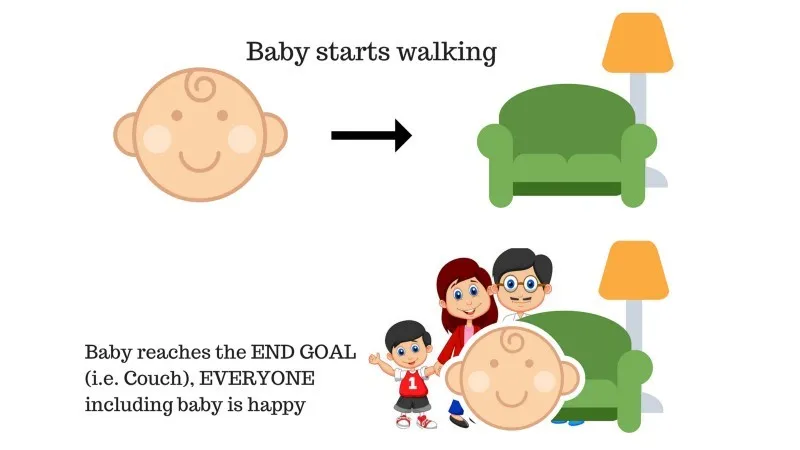
Der er en baby i familien, og hun er lige begyndt at gå, og alle er ganske glade for det. En dag forsøger forældrene at sætte sig et mål, lad os baby nå sofaen og se, om babyen er i stand til det.
Resultat af sag 1: Babyen når frem til sofaen, og derfor er alle i familien meget glade for at se dette. Den valgte vej kommer nu med en positiv belønning.
Punkter: Belønning + (+ n) → Positiv belønning.
Kilde: https://images.app.goo.gl/pGCXJ1N1bzLAer126
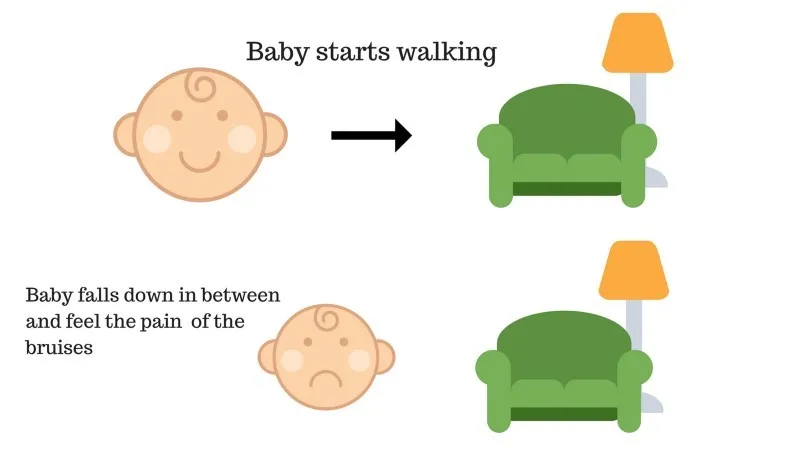
Sag nr. 2
Babyen kunne ikke nå sofaen, og babyen er faldet. Det gør ondt! Hvad kan muligvis være årsagen? Der kan være nogle forhindringer i stien til sofaen, og babyen var faldet til forhindringer.
Resultat af sag 2: Babyen falder på nogle forhindringer, og hun græder! Åh, det var dårligt, lærte hun, ikke at falde i fælden med forhindring næste gang. Den valgte vej kommer nu med en negativ belønning.
Point: Belønning + (-n) → Negativ belønning.
Kilde: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Dette har vi nu set tilfælde 1 og 2, forstærkningslæring, i koncept, gør det samme bortset fra at det ikke er menneskeligt, men i stedet udføres beregningsmæssigt.
Brug af armering trinvis
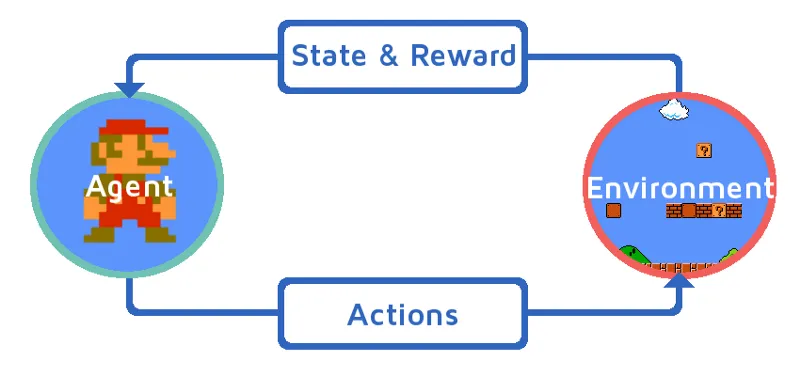
Lad os forstå forstærkningsindlæringen ved at bringe et forstærkningsagent på en trinvis måde. I dette eksempel er vores forstærkningslæringsagent Mario, som vil lære at spille på egen hånd:
Kilde: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Den aktuelle tilstand i Mario-spilmiljøet er S_0. Fordi spillet endnu ikke er startet, og Mario er på sin plads.
- Derefter starter spillet, og Mario bevæger sig, Mario dvs. RL-agenten tager og handler, lad os sige A_0.
- Nu er spilmiljøets tilstand blevet S_1.
- Desuden er RL-agenten, dvs. Mario nu tildelt et positivt belønningspunkt, R_1, sandsynligvis fordi Mario stadig er i live, og der ikke var nogen fare.
Nu vil ovennævnte loop fortsætte med at køre, indtil Mario endelig er død, eller Mario når sin destination. Denne model udsender løbende handlingen, belønningen og tilstanden.
Maksimering belønninger
Målet med forstærkningslæring er at maksimere belønningerne ved at tage hensyn til visse andre faktorer, såsom belønningsrabatten; vi vil kort forklare, hvad der menes med rabatten ved hjælp af en illustration.
Den kumulative formel for nedsatte belønninger er som:
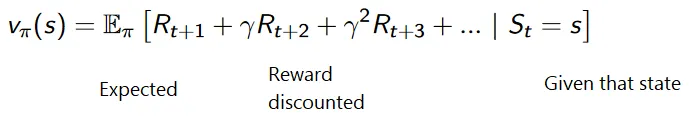
Rabatbelønninger
Lad os forstå dette gennem et eksempel:
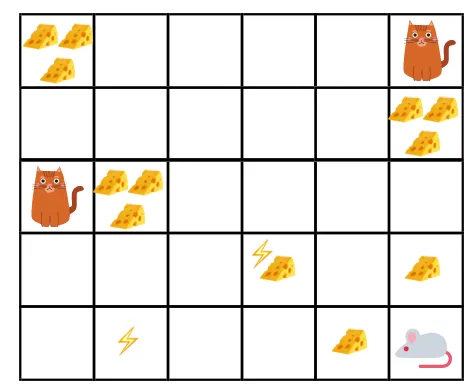
- I den givne figur er målet, musen i spillet skal spise lige så meget ost, før den bliver spist af en kat eller uden at blive elektrosjokket.
- Nu kan vi antage, at jo tættere vi er på katten eller den elektriske fælde, jo større er sandsynligheden for, at musen bliver spist eller chokeret.
- Dette indebærer, at selvom vi har den fulde ost nær den elektriske stødblok eller i nærheden af katten, jo mere risikabelt det er at gå der, er det bedre at spise osten, der er i nærheden, for at undgå enhver risiko.
- Så selvom vi har en "blok1" af ost, som er fuld og er langt fra katten og den elektriske stødblok og den anden en "blok2", som også er fuld, men enten er i nærheden af katten eller den elektriske stødblok, den senere osteblokke, dvs. “blok2”, vil være mere diskonteret i belønninger end den foregående.
Kilde: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Kilde: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Typer af forstærkningslæring
Nedenfor er de to typer forstærkningslæring med deres fordele og ulemper:
1. Positiv
Når styrken og hyppigheden af adfærden øges på grund af forekomsten af en bestemt adfærd, kaldes det Positive Reinforcement Learning.
Fordele: Ydelsen maksimeres, og ændringen forbliver i længere tid.
Ulemper: Resultater kan mindskes, hvis vi har for meget forstærkning.
2. Negativ
Det er styrkelse af adfærd, mest på grund af at det negative udtryk forsvinder.
Fordele: Opførsel øges.
Ulemper: Kun den minimale opførsel af modellen kan nås ved hjælp af negativ forstærkningslæring.
Hvor forstærkningslæring skal bruges?
Ting, der kan gøres med forstærkningslæring / eksempler. Følgende er de områder, hvor forstærkningslæring anvendes i disse dage:
- Healthcare
- Uddannelse
- Spil
- Computer vision
- Forretningsledelse
- Robotics
- Finansiere
- NLP (Natural Language Processing)
- Transportmidler
- Energi
Karrierer inden for forstærkningslæring
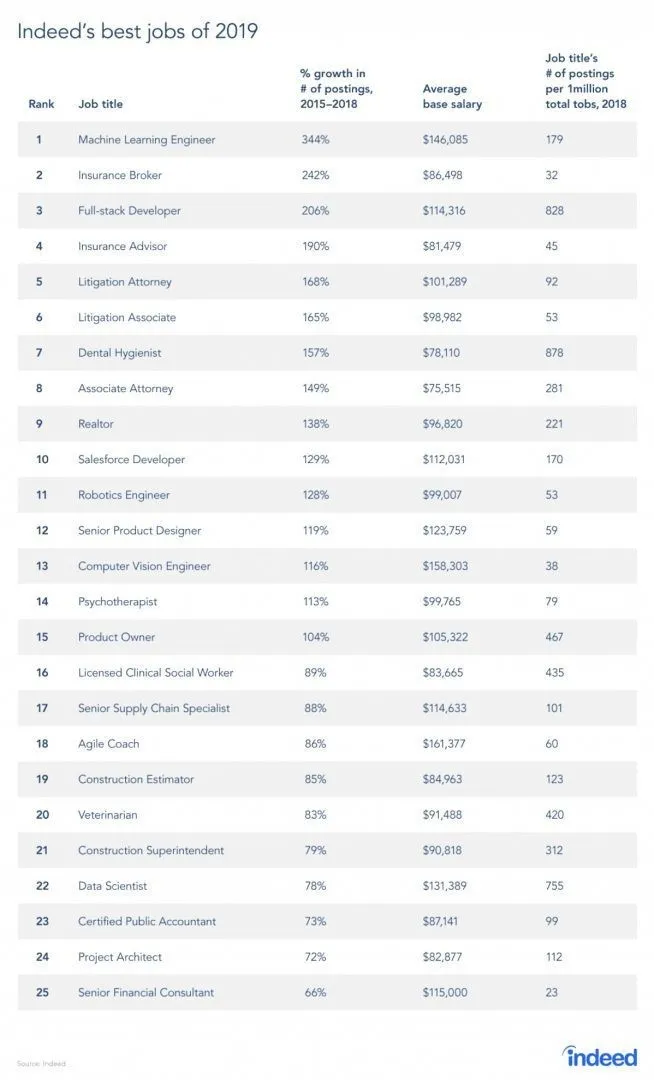
Der er faktisk en rapport fra jobstedet, da RL er en gren af maskinlæring, ifølge rapporten er maskinlæring det bedste job i 2019. Nedenfor er snapshot af rapporten. I henhold til de nuværende tendenser kommer en Machine Learning Engineers med en enorm gennemsnitlig løn på $ 146.085 og med en vækstrate på 344 procent.
Kilde: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Færdigheder til styrkelse af læring
Nedenfor er de færdigheder, der kræves til forstærkningslæring:
1. Grundlæggende færdigheder
- Sandsynlighed
- Statistikker
- Datamodellering
2. Programmeringsfærdigheder
- Grundlæggende om programmering og datalogi
- Design af software
- I stand til at anvende Machine Learning-biblioteker og algoritmer
3. Sprog til programmering af maskinlæring
- Python
- R
- Selvom der også er andre sprog, hvor Machine Learning-modeller kan designes som Java, C / C ++, men Python og R er de mest foretrukne sprog, der bruges.
Konklusion
I denne artikel startede vi med en kort introduktion om forstærkningsindlæring, og derefter dybt dykkede ind i arbejdet med RL og forskellige faktorer, der er involveret i arbejdet med RL-modeller. Derefter havde vi sat nogle eksempler fra den virkelige verden for at forstå endnu bedre om emnet. Ved udgangen af denne artikel skal man have en god forståelse af arbejdet med forstærkningslæring.
Anbefalede artikler
Dette er en guide til Hvad er forstærkningslæring? Her diskuterer vi funktionen og forskellige faktorer, der er involveret i udvikling af modeller for forstærkningslæring, med eksempler. Du kan også gennemgå vores andre relaterede artikler for at lære mere -
- Typer af maskinlæringsalgoritmer
- Introduktion til kunstig intelligens
- Kunstig intelligens værktøjer
- IoT-platform
- Top 6 Machine Learning Programmeringssprog