
Forskellen mellem Hive og HBase
Apache Hive og HBase er Hadoop-baserede big data-teknologier. De plejede begge at forespørge data. Hive og HBase kører oven på Hadoop, og de er forskellige i deres funktionalitet. Hive er kortreduceret baseret SQL-dialekt, mens HBase kun understøtter MapReduce. HBase lagrer data i form af nøgle / værdi eller kolonnefamiliepar, mens Hive ikke gemmer data.
Head to Head forskelle mellem Hive vs HBase (Infographics)
Nedenfor er Top 8 forskellen mellem Hive vs HBase
Vigtigste forskelle mellem Hive vs HBase
- Hbase er en ACID-kompatibel, mens Hive ikke er.
- Hive understøtter partitionering og filterkriterier baseret på datoformatet, mens HBase understøtter automatisk partitionering.
- Hive understøtter ikke opdateringserklæringer, mens HBase understøtter dem.
- Hbase er hurtigere sammenlignet med Hive til hentning af data.
- Hive bruges til at behandle strukturerede data, hvorimod HBase, da de er skemafri, kan behandle enhver type data.
- Hbase er meget (vandret) skalerbar sammenlignet med Hive.
- Hive analyserer dataene på HDFS med understøttelse af SQL Queries, og derefter konverterer de det til et kort og reducerer job, mens det i Hbase, da det er streaming i realtid, udfører det sine operationer direkte i databasen ved at partitionere til tabeller og kolonnefamilier.
- når man kommer til forespørgslen om datahub bruger en shell, der kaldes Hive shell, til at udstede kommandoer, hvorimod HBase, da det er en database, vil vi bruge en kommando til at behandle dataene i HBase.
- For at gå til Hive-shell bruger vi kommandobilken. Efter at have givet dette vises det som bikube>. I HBase giver vi simpelthen som Brug HBase.
Hive vs HBase-sammenligningstabel
| Grundlag for sammenligning | hive | Hbase |
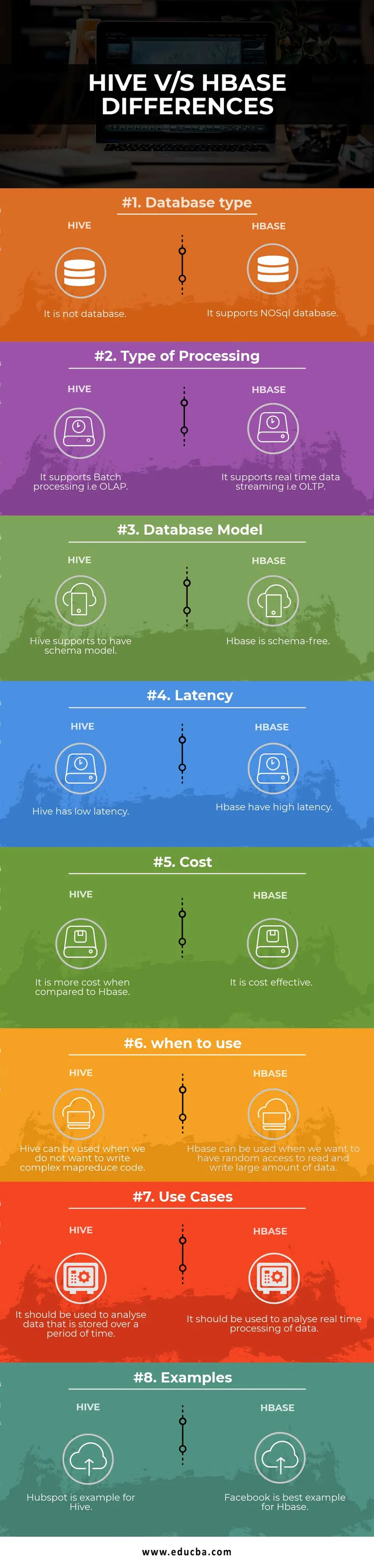
| Databasetype | Det er ikke en database | Det understøtter NoSQL-database |
| Type behandling | Det understøtter batchbehandling dvs. OLAP | Det understøtter datastrømning i realtid dvs. OLTP |
| Databasemodel | Hive understøtter at have skemamodel | Hbase er skemafri |
| Reaktionstid | Hive har lav latenstid | Hbase har høj latenstid |
| Koste | Det er dyrere sammenlignet med HBase | Det er omkostningseffektivt |
| hvornår man skal bruge | Hive kan bruges, når vi ikke ønsker at skrive en kompleks MapReduce-kode | HBase kan bruges, når vi vil have tilfældig adgang til at læse og skrive en stor mængde data |
| Brug sager | Det skal bruges til at analysere data, der er gemt over en periode | Det skal bruges til at analysere realtidsbehandling af data. |
| eksempler | Hubspot er et eksempel på Hive | Facebook er det bedste eksempel for Hbase |
Forskelle i kodning mellem Hive vs HBase
Lad os nu diskutere de grundlæggende forskelle mellem Hive og HBase i kodning.
| Grundlag for sammenligning | hive | Hbase |
| Sådan opretter du en database | Opret datatabase (hvis ikke eksisterer) DATABASE-NAVN; | Da Hbase er en database, behøver vi ikke oprette en bestemt database |
| Sådan slettes en database | DROP DATABASE (HVIS EKSISTERET) DATABASE-NAVN (BEGRÆNSNING ELLER CASCADE); | NA |
| Sådan opretter du en tabel | Opret (midlertidig eller ekstern) tabel (hvis ikke eksisterer) tabel-navn ((kolonne-navn data_type (Kommentar kolonne-kommentar), ….)) (Kommentar tabel_komment) (ROW FORMAT rækkeformat) (Gemt som filformat) | SKAB '', '' |
| Sådan ændrer du et bord | ALTER TABEL-navn RENAME TO new-name
ALTER TABEL-navn DROP (COLUMN) kolonnenavn ALTER TABELnavn TILFØJE KOLUMMER (col-spec (, col-spec ..)) ALTER TABEL-navn ÆNDR kolonnenavn nyt-navn ny-type ALTER TABELnavn ERSTAT KOLUMMER (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Deaktivering af en tabel | NA | deaktiver 'TABLE-NAME' -> for at deaktivere det angivne tabelnavn
deaktivere_all 'r *' -> for at deaktivere alle tabeller, der matcher det regulære udtryk |
| Aktivering af en tabel | NA | aktiver 'TABLE-NAME' |
| Sådan slettes en tabel | DROP TABEL HVIS EKSISTERER tabelnavnet | Hvis vi vil droppe en tabel, skal vi først deaktivere den
deaktiver 'tabelnavn' drop 'tabel-navn' Tilsvarende kan vi bruge disable_all og drop_all til at slette de tabeller, der matcher det specificerede regulære udtryk. |
| At liste databaser | vis databaser; | NA |
| At liste tabeller i databasen | vis tabeller; | liste |
| For at beskrive skemaet for en tabel | beskriv tabellenavn; | beskriv 'tabelnavn' |
Integration af Hive vs HBase
- Installer og konfigurer Hive.
- Installer og konfigurer HBase.
- Til integration af både Hive og HBase bruger vi STORAGE HANDLERS i Hive.
- Storage Handlers er en kombination af SERDE, InputFormat, OutputFormat, der accepterer enhver ekstern enhed som en tabel i Hive.
- Så denne funktion hjælper en bruger med at udstede SQL-forespørgsler, hvad enten tabellen findes i Hadoop eller i den NOSQL-baserede database, såsom HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nu skal vi undersøge et eksempel til at forbinde Hive med HBase ved hjælp af HiveStorageHandler:
- Først skal vi oprette Hbase-tabel ved hjælp af kommandoen.
oprette 'Student', 'personalinfo', 'dept info'
-> Personalinfo og afd. Info opretter to forskellige kolonnefamilier i Studenttabellen.
- Vi er nødt til at indsætte nogle data i Studenttabellen. F.eks. Som nævnt nedenfor.
sætte 'student', 'sid01 ′, ' personalinfo: navn ', ' Ram '
sæt 'studerende', 'sid01 ′, ' personalinfo: mailid ', ' '
sæt 'student', 'sid01 ′, ' deptinfo: deptname ', ' Java '
sætte 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> Tilsvarende kan vi oprette data til sid02, sid03 …
- Nu skal vi oprette Hive-tabel, der peger på HBase-tabel.
- For hver kolonne i Hbase opretter vi en bestemt tabel til den kolonne i Hive. I dette tilfælde opretter vi 2 tabeller i Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Tilsvarende er vi nødt til at oprette tabel om detaljerede oplysninger om dybd i hive.
- Nu kan vi skrive SQL-forespørgsel i en bikube som nævnt nedenfor.
select * from student_hbase;
På denne måde kan vi integrere Hive med HBase.
Konklusion - Hive vs HBase
Som diskuteret er de begge forskellige teknologier, der giver forskellige funktionaliteter, hvor Hive fungerer ved at bruge SQL-sprog, og det kan også kaldes, da HQL og HBase bruger nøgleværdipar til at analysere dataene. Hive og HBase fungerer bedre, hvis de kombineres, fordi Hive har lav latens og kan behandle en enorm mængde data, men kan ikke opretholde ajourførte data, og HBase understøtter ikke analyse af data, men understøtter opdateringer på rækkeniveau på en stor mængde af data.
Anbefalet artikel
Dette har været en guide til Hive vs HBase, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Apache Pig vs Apache Hive - Top 12 nyttige forskelle
- Find ud af de 7 bedste forskelle mellem Hadoop vs HBase
- Top 12 sammenligning af Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Find ud af de bedste forskelle