

Hvad er Hive-funktion?
Som vi ved i dag er Hadoop en af de alsidige teknologier i big data. Hadoop har evnen til at klare store datasæt, men da datavæksten er proportionalt, bliver kortreducerende programmer vanskelige. For at udføre SQL-forespørgsler, der er til stede i HDFS blev en sådan teknologi introduceret af Hadoop kaldet apache Hive startet af Facebook. Hive bruges meget af dataanalytikeren. De er implementeret til tre funktionaliteter, nemlig: Datasummering, dataanalyse på distribueret fil og dataforespørgsel. Hive leverer SQL-lignende forespørgsler kaldet HQL - sprog med højt forespørgsel understøtter DML, brugerdefinerede funktioner. Hive-kompilator konverterer internt denne forespørgsel til kortreducerende job, hvilket forenkler Hadoop's arbejde med at skrive komplekse programmer. Vi kunne finde en bikube i applikationer som datalager, datavisualisering og ad-hoc-analyse, google analytics. Den vigtigste fordel er, at de bruger SQL-viden, som er en grundlæggende færdighed implementeret på tværs af dataforskere og software-fagfolk.
Forskellige bikubfunktioner i detaljer
Hive understøtter forskellige datatyper, der ikke findes i andre databasesystemer. det inkluderer et kort, array og struktur. Hive har nogle indbyggede funktioner til at udføre flere matematiske og aritmetiske funktioner til et specielt formål. Funktioner i bikube kan kategoriseres i følgende typer. De er indbyggede funktioner og brugerdefinerede funktioner.
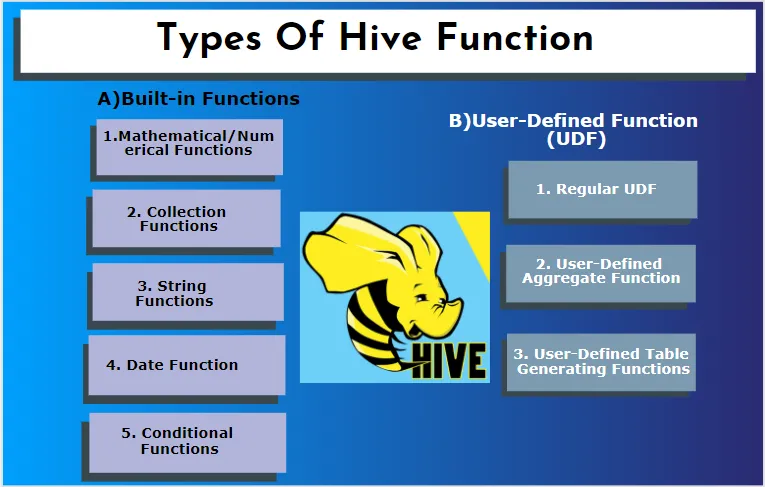
A) Indbyggede funktioner
Disse funktioner udtrækker data fra bikubetabellerne og behandler beregningerne. Nogle af de indbyggede funktioner er:
1. Matematiske / numeriske funktioner
Disse funktioner bruges hovedsageligt til matematiske beregninger. Disse funktioner bruges i SQL-forespørgsler.
| Funktionsnavn | Eksempel | Beskrivelse |
| ABS (dobbelt x) | Hive> vælg ABS (-200) fra tmp; | Det returnerer den absolutte værdi af et tal. |
| CEIL (dobbelt x) | Hive> vælg CEIL (8.5) fra tmp; | Det henter det mindste heltal større end eller lig med værdien x. |
| Rand (), rand (int seed) | Hive> vælg Rand () fra tmp;
Rand (0-9) | Det returnerer et tilfældigt tal, afhænger af frøværdien, de genererede tilfældige tal ville være deterministiske. |
| Pow (dobbelt x, dobbelt y) | Hive> vælg Pow (5, 2) fra tmp; | Den returnerer x-værdien hævet til y-effekten. |
| GULV (dobbelt y) | Hive> vælg FLOOR (11.8) fra tmp; | Det returnerer et maksimalt heltal mindre end eller lig med at give værdien y. |
| EXP (dobbelt a) | Hive> vælg Exp (30) fra tmp; | Det returnerer eksponentværdien på 30. de naturlige algoritmeværdier. |
| PMOD (int a, int b) | Hive> vælg PMOD (2, 4) fra tmp; | Det giver den positive modul for tallet. |
2. Samlingsfunktioner
At dumpe alle elementerne sammen og returnere enkeltelementer afhænger af den inkluderede datatype.
| Funktionsnavn | Eksempel | Beskrivelse |
| Map_values (Kort) | Hive> vælg kortværdier ('hej', 45) | Det henter uordnede arrayelementer. |
| Størrelse (kort) | Hive> vælg størrelse (kort) | Returnerer antallet af elementer på datatypekortet. |
| Array_contains (Array b) | Hive> vælg array_concepts (a (10)) | Returnerer SAND, hvis arrayet indeholder værdien. |
| Sort_array (Array a) | Hive> vælg sort_array ((10, 3, 6, 1, 7)) | Sorterer inputmatrisen i stigende rækkefølge i henhold til den naturlige rækkefølge af arrayelementerne og returnerer værdien. |
3. Strengefunktioner
Brug af strengfunktioner udføres dataanalyse glimrende.
| Opdel (streng s, streng pat) | Hive> vælg split ('educba ~ hive ~ Hadoop, ' ~ ') output: ("educba", "hive", "Hadoop") | Det opdeler streng omkring klapudtryk og returnerer en matrix. |
| indlæsning (streng s, int Len, strengpude) | Hive> vælg belastning ('EDUCBA', 6, 'H') | Det returnerer strenge med højre polstring med længden på strengen. (pad-karakter). |
| Længde (streng str) | Hive> vælg længde ('educba') | Denne funktion returnerer længden på strengen. |
| Rtrim (streng a) | Hive> vælg rtrim ('TOPIC');
Output: 'Emne' | Det returnerer resultatet ved at beskære mellemrum fra højre ender. |
| Concat (streng m, streng n) | Hive> vælg konkat ('data', 'ware') Resultat: Dataware | Det resulterer i strengen ved at foretage sammenkædning af to strenge, dette kan tage et hvilket som helst antal input. |
| Omvendt (streng) | Hive> vælg omvendt ('Mobil') | Returnerer resultatet af en vendt streng. |
4. Datofunktion
Det er nødvendigt at have dataformat i hive for at forhindre Null fejl i output. Det er nødvendigt at have datakompatibilitet for at gå sammen med introducerede datafunktioner i hive.
| Unix_timestamp ( strengdato, strengmønster ) | Hive> vælg Unix_ timestamp ('2019-06-08', 'åååå-mm-dd'); Resultat: 124576 400 taget tid: 0.146 sekunder | Denne funktion returnerer dato til det specifikke format og returnerer sekunder mellem dato og Unix-tider. |
| Unix_timestamp (streng dato) | Hive> vælg Unix_ timestamp ('2019-06-08 09:20:10', 'åååå-mm-dd'); | Den returnerer datoen i 'åååå-MM-dd HH: mm: ss' format til Unix tidsstempel. |
| Time (streng dato) | Hive> vælg time ('2019-06-08 09:20:10'); Resultat: 09 timer | Den returnerer timestamp-timen |
5. Betingede funktioner
| Hvis (Boolean test, T værdi sand, t falsk) | Hive> vælg IF (1 = 1, 'SAND', 'FALSE') som IF_CONDITION_TEST; | Det kontrollerer med betingelsen, om værdien er sand returnerer 1 og falsk returnerer 0. |
| Er ikke null (b) | Hive> Select er ikke null (null); | Dette henter ikke nul-sætninger. hvis null returnerer falsk. |
| Koalesce (værdi1, værdi2) | Eksempel: Hive> vælg sammenhæng (Nul, nul, 4, nul, 6). det returnerer 4. | Det henter først ikke nulværdier fra listen over værdier. |
B) Brugerdefineret funktion (UDF)
Hive bruger brugerspecifikke funktioner i henhold til klientkravene, det er skrevet i java-programmering. Det implementeres af to grænseflader, nemlig enkel API og kompleks API. De kaldes fra bikupeforespørgslen. Tre typer UDF'er:
1. Regelmæssig UDF
Det fungerer på et bord med en enkelt række. Det oprettes ved at oprette en java-klasse og derefter pakke dem ind i en .jar-fil. Det næste trin er at verificere med en bikupplasse. derefter henrettet dem til sidst i en bikub-forespørgsel.
2. Brugerdefineret aggregeret funktion
De bruger aggregerede funktioner som gennemsnit / middelværdi ved at implementere fem metoder init (), iterate (), partiel (), merge (), terminate ().
3. Brugerdefineret tabelgenerering af funktioner
Det fungerer med en enkelt række i en tabel og resulterer i flere rækker.
Konklusion
Afslutningsvis har vi lært, hvordan vi arbejder i bikupplatformen med indbyggede funktioner og brugerdefinerede funktioner i detaljer gennem denne artikel. De fleste organisationer har programmerer og SQL-udviklere til at arbejde på serversiden, men en apache-bikive er et kraftfuldt værktøj, der hjælper dem med at bruge Hadoop-rammer uden forudgående viden om programmer og kortreduktion. Hive hjælper nye brugere med at starte og udforske dataanalyse uden nogen barrierer.
Anbefalede artikler
Dette er en guide til Hive-funktionen. Her diskuterer vi konceptet, to forskellige typer funktioner og underfunktioner i Hive. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Top strengfunktioner i Hive
- Spørgsmål om Hive-interview
- Hvad er RMAN Oracle?
- Hvad er vandfaldsmodel?
- Introduktion til Hive Arkitektur
- Hive ordre af