
Hvad er Cassandra?
Cassandra er en NoSQL-database, der er peer to peer distribueret database. Det kører på en klynge, der har homogene knudepunkter. Det er lavet på en sådan måde, at det kan håndtere store datamængder. Ved håndtering af disse data skal det også være i stand til at give en høj kapacitet. Cassandra leverer højt hele tiden, når det kommer til læse- og skrivehandlinger. Arkitekturen i Cassandra-klyngen har ingen mestre, slaver eller nogen specifikke ledere. Ved at bruge denne måde sikrer det, at der ikke er et enkelt mislykkelsespunkt. Lad os se på arkitekturen i detaljer.
Cassandra Arkitektur
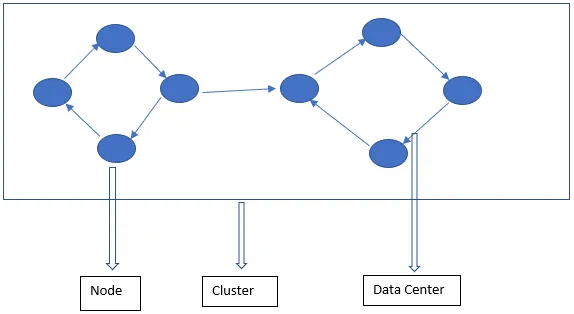
Cassandra-arkitekturen består hovedsageligt af knudepunkt, klynge og datacenter. Ud over disse er der også andre komponenter. Cassandra er en række gemt database. Det giver autoriserede brugere mulighed for at oprette forbindelse til enhver knude i ethvert datacenter ved hjælp af CQL.
Nøglestrukturer i Cassandra
Dette er følgende nøglestrukturer i Cassandra:
- Knude - Det er her dataene gemmes. Det er den mest basale komponent i Cassandra. Det kan betragtes som en enkelt server i et rack. Det sikrer, at der ikke er et enkelt mislykkelsespunkt.
- Datacenter - Et datacenter er en samling af noder. Dette kan være fysisk eller virtuelt. Afhængigt af arbejdsbyrden er datacentre opdelt og valgt. Replikeringsfaktoren afgøres på basis af datacentret. Afhængig af denne replikationsfaktor kan data skrives til forskellige datacentre.
- Cluster - Cluster består af et eller flere datacentre. Klynger spænder normalt på forskellige fysiske placeringer.
Ud over disse er de andre komponenter, der spiller en rolle i Cassandra, som nedenfor.
1. Forpligtelseslog
De data, der er forpligtet til at opretholde holdbarheden af data, gemmes i forpligtelsesloggen. Data flyttes til en sorteret strengtabel (forklares næste). Når denne bevægelse er udført, kan forpligtelsesloggen arkiveres, slettes eller genanvendes.
2. SS-tabel
Denne tabel som nævnt i det foregående punkt gemmer log- eller hukommelsestabellerne med regelmæssige intervaller. Det er en uforanderlig datafil. SS-tabeller kan gemme data ofte på en rækkefølge. De tilføjer data og vedligeholder oplysninger til hver Cassandra-tabel.
3. CQL-tabel
Cassandra Query-tabellen er en samling af bestilte kolonner, der kan hente en række fra denne tabel. Der er kolonner, der er gemt i denne tabel, hvor data kan hentes ved at bruge den primære nøgle.
4. Blomstfilter
Det er en simpel form af cache, hvor der er ikke-deterministiske algoritmer, der er gemt til test. Den kontrollerer, om et element er et medlem af sættet eller ej. Disse filtre er normalt tilgængelige efter hver forespørgsel, der kører.
Nøglekomponenter til at konfigurere Cassandra
Der er følgende komponenter i Cassandra:
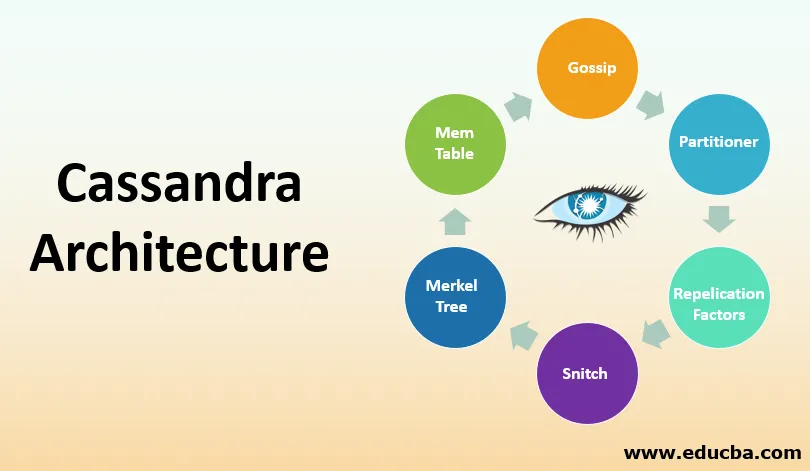
1. Sladder
- Som navnet antyder, skal der være kommunikation mellem jævnaldrende for at opdage og dele placering og information om alle noder.
- Disse oplysninger skal fortsætte lokalt, så hver node kan bruge informationen, så snart en node skal genstartes. Noder opdager oplysninger om andre noder ved at udveksle oplysninger.
- Dette kan gøres i højst tre noder. Oplysningerne deles ikke med hver knude, der findes i klyngen eller datacentret. Oplysningerne deles med et par knudepunkter, men til sidst gennemgår statsoplysningerne i hele klyngen.
2. Partitioner
- Partitioneren beslutter, hvilken knude der skal modtage den første kopi af data. Det er også ansvarligt for at tage sig af distributionen af disse kopier.
- Det bestemmer, hvilken knude der skal have, hvilken replikation i klyngen. Hver række med data skal identificeres unikt. Dette kan gøres ved at bruge en primær nøgle eller en partitionsnøgle.
- Partitioneren er en hash-funktion, der hjælper med at få et token fra en primær nøgle i enhver række. Hver knude har en num_token-værdi tildelt til den, der kan indstilles som partitioner.
- Den tokenværdi, der genereres, hjælper med at bestemme, hvilken knude der modtager replikken af rækkerne.
3. Replikationsfaktor
- Denne faktor bestemmer det samlede antal kopier, der er til stede i klyngen. Hvis replikationsfaktoren er 1, er der kun en kopi af hver række på en knude.
- Tilsvarende, hvis replikationsfaktoren er to, opretholdes der to kopier, hvor hver kopi er til stede på en anden knude. Som nævnt tidligere er der ingen master-slave-arkitektur i Cassandra, hver kopi er vigtig.
- Replikeringsfaktoren er defineret for hvert datacenter. Denne faktor skal være større end én, men ikke mere end antallet af noder, der findes i klyngen.
4. Snitch
- Replikeringsstrategien, der hjælper med at få det sted, hvor kopier skal placeres for en gruppe maskiner i datacentret og stativet kaldes Snitch.
- Der er et dynamisk lag, der hjælper med overvågning og ydeevne og hjælper med at vælge den bedste replika, hvorfra data kan læses. Snitches skal kun konfigureres, når der oprettes en klynge.
- Det har standardværdier aktiveret for de fleste implementeringer. Konfigurationsændringerne kan foretages i filen Cassandra.yml, hvor den dynamiske snitch-tærskel for hver node er til stede.
5. Merkle Tree
- Der kan være forskelle i datablokke. For let at finde forskellene er Merkle træ et hashtræ, der hjælper med at gøre dette.
- Bladknuderne i hashtræet indeholder hasjer af separate datablokke, og overordnede knudepunkter har oplysningerne, eller de gemmer også hasherne for deres børn.
- Ved at bruge denne teknik er det lettere at finde forskelle mellem de noder, der er til stede.
6. Mem-tabel
- Denne tabel indeholder oplysninger om cache, hvis data ikke er skyllet endnu og befinder sig i hukommelsen.
Konklusion
Cassandra er en NoSQL-database, der er nyttig til behandling af enorme mængder data. Det har ikke en typisk master-slave-arkitektur, og derfor er alle noder lige så vigtige. Knudepunkterne har replikker over klyngen pr. Replikationsfaktor. Dette sikrer konsistensen og holdbarheden af dataene. Med alle disse funktioner er det tydeligt, at Cassandra er meget nyttig til big data. Cassandra er derfor holdbar, hurtig, da den er distribueret og pålidelig.
Anbefalede artikler
Dette er en guide til Cassandra Arkitektur. Her diskuterer vi Cassandra's introduktion, Cassandra-arkitektur, nøglestruktur og nøglekomponenter. Du kan også gennemgå vores andre foreslåede artikler -
- Oversigt over Kubernetes Arkitektur
- Hvad er Big Data Architecture?
- Funktioner tilføjet til AutoCAD Arkitektur
- Cloud computing-arkitektur