

Oversigt over typer af klynger
Før vi lærer typer af klynger, lad os forstå, hvad der er klynge, og hvorfor er det så vigtigt i maskinindlæringsbranchen lige nu.
Hvad er klynge? Clustering er en proces, hvor algoritmen deler datapunkterne i et bestemt antal grupper baseret på princippet om, at lignende datapunkter forbliver tæt på hinanden, og de falder i den samme gruppe.
Hvorfor er det så vigtigt nu? Lad os forstå, at der ved f.eks. At se et eksempel findes en online tøjbutik, og de ønsker at forstå deres kunder bedre, så de kan gøre deres annoncestrategi mere effektiv. Det er ikke muligt for dem at have en unik slags strategi for hver kunde, i stedet for dette, hvad de kan gøre, er at opdele kunderne i et bestemt antal grupper (baseret på deres tidligere køb) og have en separat strategi for separate grupper. Dette gør virksomheden mere effektiv, dette er grunden til, at klynger er vigtige i branchen nu.
Typer af klynger
I store træk klassificeres metoder til klyngeteknikker i to typer, de er hårde metoder og bløde metoder. I metoden Hard klynge tilhører hvert datapunkt eller observation kun en klynge. I den bløde klyngemetode hører hvert datapunkt ikke helt til en klynge, i stedet kan det være et medlem af mere end en klynge, det har et sæt medlemskabskoefficienter, der svarer til sandsynligheden for at være i en given klynge.
I øjeblikket er der forskellige typer klyngemetoder, der er i brug. Lad os i denne artikel se nogle af de vigtige, såsom hierarkisk klynge, Partitionering af klynger, Fuzzy clustering, Density-baseret clustering og Distribution Model-baseret clustering. Lad os nu diskutere hver enkelt af disse med et eksempel:
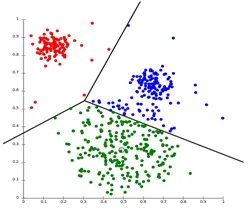
1. Partitionering Clustering
Partitionering Clustering er en type clustering-teknik, der deler datasættet i et sæt antal grupper. (For eksempel værdien af K i KNN, og det vil blive besluttet, før vi træner modellen). Det kan også kaldes som en centroid-baseret metode. I denne fremgangsmåde dannes klyngecenter (centroid) sådan, at afstanden af datapunkter i den klynge er minimal, når det beregnes med andre klyngscentroider. Et mest populært eksempel på denne algoritme er KNN-algoritmen. Sådan ser en partitioneringsgruppealgoritme ud
2. Hierarkisk klynge
Hierarkisk klynge er en type klyngeteknologi, der deler det datasæt ind i et antal klynger, hvor brugeren ikke specificerer antallet af klynger, der skal genereres, før han træner modellen. Denne type klyngeteknik kaldes også forbindelsesbaserede metoder. I denne metode udføres simpelt opdeling af datasættet ikke, mens det giver os hierarkiet af de klynger, der smelter sammen efter en bestemt afstand. Når den hierarkiske klynge er udført på datasættet, vil resultatet være en træbaseret repræsentation af datapunkter (Dendogram), der er opdelt i klynger. Sådan ser en hierarkisk klynge ud, når træningen er udført
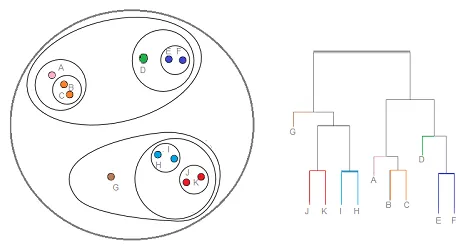
Kildelink: Hierarkisk klynge
I partitionering af klynger og hierarkisk klynge, en hovedforskel, vi kan bemærke, er ved partitionering af klynger, vi vil præ-specificere værdien af, hvor mange klynger vi ønsker, at datasættet skal opdeles i, og vi præciserer ikke denne værdi i hierarkisk klynge .
3. Tæthedsbaseret klynge
I denne klynge vil teknikklynger dannes ved adskillelse af forskellige tæthedsregioner baseret på forskellige tætheder i dataplanen. Densitetsbaseret rumlig klynge og anvendelse med støj (DBSCAN) er den mest anvendte algoritme i denne type teknik. Hovedideen bag denne algoritme er, at der skal være et minimum antal point, der indeholder i nærheden af en given radius for hvert punkt i klyngen. Indtil videre i ovennævnte klyngeteknikker, hvis du observerer grundigt, kan vi bemærke en almindelig ting i alle de teknikker, der er formen på dannede klynger, er enten sfæriske eller ovale eller konkave formede. DBSCAN kan danne klynger i forskellige former, denne type algoritme er bedst egnet, når datasættet indeholder støj eller outliers. Sådan ser en tæthedsbaseret rumlig klynge-algoritme ud efter træning.
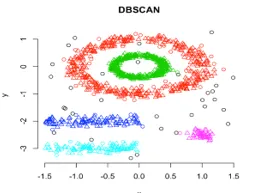
Kildelink: Tæthedsbaseret klynge
4. Distribution Model-Based Clustering
I denne type klynger dannes teknikklynger ved at identificere med sandsynligheden for, at alle datapunkter i klyngen kommer fra den samme distribution (Normal, Gaussian). Den mest populære algoritme i denne type teknik er Expectation-Maximization (EM) clustering ved hjælp af Gaussian Mixture Models (GMM).
Normale klyngeteknikker som hierarkisk klynge og partitionering klynger er ikke baseret på formelle modeller, KNN ved partitionering af klynger giver forskellige resultater med forskellige K-værdier. Som KNN og KMN betragter som middel for klyngecenteret, er det ikke bedst egnet i nogle tilfælde med Gaussiske blandingsmodeller, antager vi, at datapunkter er Gaussisk fordelt, på denne måde har vi to parametre til at beskrive formen på klyngernes middel og standardafvigelsen. På denne måde tildeles for hver klynge en Gaussisk distribution, for at få de optimale værdier af disse parametre (middel og standardafvigelse), anvendes en optimeringsalgoritme kaldet Expectation Maximization. Sådan ser EM - GMM ud efter træning.
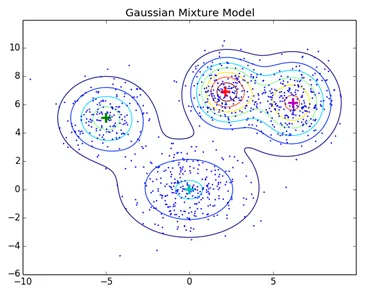
Kildelink: Distribution Model-Based Clustering
5. Fuzzy Clustering
Tilhører en gren af blødmetoden klyngeteknikker, hvorimod alle de ovennævnte klyngeteknikker tilhører hårde metodeklyngeteknikker. I denne type klyngeteknikker peger tæt på midten, måske en del af den anden klynge i højere grad end punkter i kanten af den samme klynge. Sandsynligheden for et punkt, der hører til en given klynge, er en værdi, der ligger mellem 0 til 1. Den mest populære algoritme i denne type teknik er FCM (Fuzzy C-betyder algoritme). Her beregnes centroid af en klynge som middelværdien af alle punkter vægtet af deres sandsynlighed for at tilhøre klyngen.
Konklusion - Typer af klynger
Dette er nogle af de forskellige klyngeteknikker, der i øjeblikket er i brug, og i denne artikel har vi dækket en populær algoritme i hver klyngeteknik. Vi er nødt til at vælge den type teknologi, vi bruger, baseret på vores datasæt og krav, vi har brug for at opfylde.
Anbefalede artikler
Dette har været en guide til typer af klynger. Her diskuterer vi forskellige typer klynger med deres eksempler. Du kan også se på de følgende artikler for at lære mere -
- Hierarkisk klynge-algoritme
- Klynge i maskinlæring
- Typer af maskinlæringsalgoritmer
- Typer af dataanalyseteknikker
- Sådan bruges og fjernes hierarkiet i Tableau?
- Komplet guide til typer af dataanalyse