
Introduktion til maskinlæringsmodeller
En oversigt over forskellige maskinlæringsmodeller, der bruges i praksis. Ud fra definitionen er en maskinlæringsmodel en matematisk konfiguration opnået efter anvendelse af specifikke maskinlæringsmetoder. Ved hjælp af det store udvalg af API'er er det stort set lige nu at opbygge en maskinindlæringsmodel med færre linjer med koder. Men den egentlige dygtighed hos en anvendt datavidenskabelig professionel ligger i at vælge den rigtige model baseret på problemopgørelsen og krydsvalidering i stedet for at kaste data til smarte algoritmer tilfældigt. I denne artikel diskuterer vi forskellige maskinlæringsmodeller, og hvordan de bruges effektivt ud fra den type problemer, de løser.
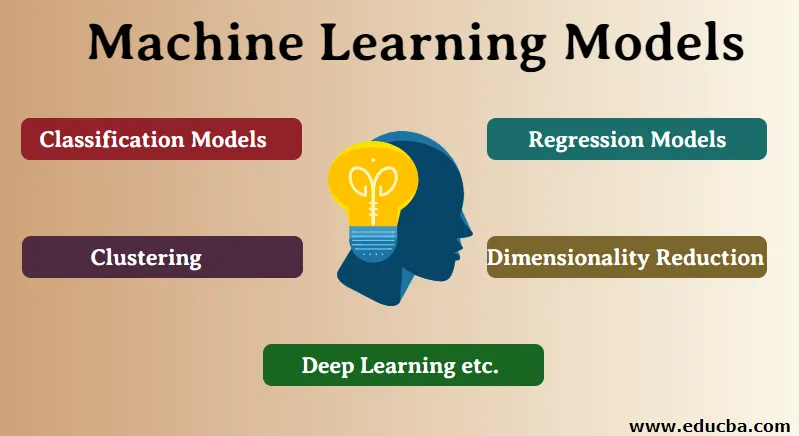
Typer af maskinlæringsmodeller
Baseret på typen af opgaver kan vi klassificere maskinindlæringsmodeller i følgende typer:
- Klassificeringsmodeller
- Regressionsmodeller
- clustering
- Dimensionalitetsreduktion
- Deep Learning osv.
1) Klassificering
Med hensyn til maskinlæring er klassificering opgaven med at forudsige typen eller klassen af et objekt inden for et begrænset antal indstillinger. Outputvariablen til klassificering er altid en kategorisk variabel. For eksempel er det en standard binær klassificeringsopgave at forudsige en e-mail som spam eller ej. Lad os nu notere nogle vigtige modeller for klassificeringsproblemer.
- K-nærmeste nabos algoritme - enkel, men beregningsmæssigt udtømmende.
- Naive Bayes - Baseret på Bayes sætning.
- Logistic Regression - Lineær model til binær klassificering.
- SVM - kan bruges til binære / multiklasseklassifikationer.
- Beslutningstræ - " Hvis andet " -baseret klassifikator, mere robust over for outliers.
- Ensembler - Kombination af flere maskinindlæringsmodeller kølede sammen for at få bedre resultater.
2) Regression
I maskinen er læringsregression et sæt problemer, hvor outputvariablen kan tage kontinuerlige værdier. For eksempel kan det at forudsige flyprisen betragtes som en standard regressionsopgave. Lad os notere nogle vigtige regressionsmodeller, der bruges i praksis.
- Lineær regression - den enkleste baseline-model til regressionsopgave, fungerer kun godt, når data er lineært adskillelige og meget mindre eller ingen multicollinearity er til stede.
- Lasso-regression - Lineær regression med L2-regularisering.
- Ridge Regression - Lineær regression med L1-regularisering.
- SVM-regression
- Beslutningstræregression osv.
3) Clustering
I enkle ord er klynger opgaven at gruppere lignende objekter sammen. Maskinlæringsmodeller hjælper med at identificere lignende objekter automatisk uden manuel indgriben. Vi kan ikke opbygge effektive overvågede maskinlæringsmodeller (modeller, der skal trænes med manuelt kuraterede eller mærkede data) uden homogene data. Clustering hjælper os med at opnå dette på en smartere måde. Følgende er nogle af de meget anvendte klyngemodeller:
- K betyder - Enkelt, men lider af høj varians.
- K betyder ++ - Ændret version af K betyder.
- K medoider.
- Agglomerativ klynge - En hierarkisk klyngemodel.
- DBSCAN - Tæthedsbaseret klyngerealgoritme osv.
4) Dimensionalitetsreduktion
Dimensionalitet er antallet af forudsigelsesvariabler, der bruges til at forudsige den uafhængige variabel eller mål. I den virkelige verdensdatasæt er antallet af variabler for høj. For mange variabler bringer også forbandelsen for overfitting til modellerne. I praksis blandt disse store antal variabler bidrager ikke alle variabler ens til målet, og i et stort antal tilfælde kan vi faktisk bevare afvigelser med et mindre antal variabler. Lad os liste over nogle ofte anvendte modeller til reduktion af dimensionalitet.
- PCA - Det skaber mindre antal nye variabler ud af et stort antal prediktorer. De nye variabler er uafhængige af hinanden, men mindre tolkbare.
- TSNE - Tilvejebringer lavere dimensionel indlejring af højdimensionelle datapunkter.
- SVD - Nedbrydning af enkeltværdi bruges til at nedbryde matrixen i mindre dele for at kunne beregne effektivt.
5) Deep Learning
Deep learning er en undergruppe af maskinlæring, der beskæftiger sig med neurale netværk. Baseret på arkitekturen i neurale netværk, lad os liste ned vigtige modeller for dyb læring:
- Flerlagsperstron
- Konvolution neurale netværk
- Gentagne neurale netværk
- Boltzmann-maskine
- Autokodere osv.
Hvilken model er bedst?
Ovenfor tog vi ideer om masser af maskinlæringsmodeller. Nu kommer et åbenlyst spørgsmål til os 'Hvilken er den bedste model blandt dem?' Det afhænger af det aktuelle problem og andre tilknyttede attributter som outliers, mængden af tilgængelige data, kvalitet af data, funktionsudvikling osv. I praksis foretrækkes det altid at starte med den enkleste model, der gælder for problemet og øge kompleksiteten gradvist ved korrekt parameterindstilling og krydsvalidering. Der er et ordsprog i datavidenskabens verden - 'Krydsvalidering er mere troværdig end domæneviden'.
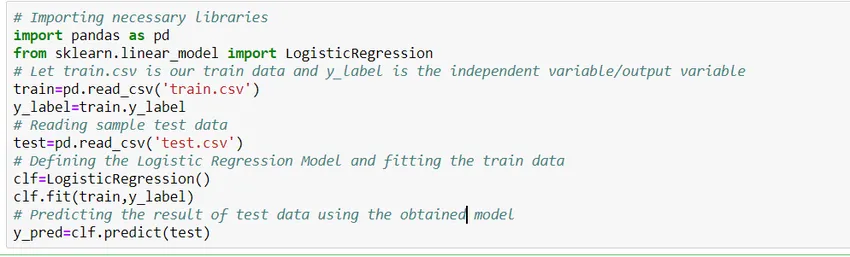
Hvordan man bygger en model?
Lad os se, hvordan man bygger en simpel logistisk regressionsmodel ved hjælp af Scikit Learn-biblioteket af python. For enkelheds skyld antager vi, at problemet er en standardklassificeringsmodel, og 'train.csv' er toget, og 'test.csv' er henholdsvis toget og testdata.
Konklusion
I denne artikel diskuterede vi de vigtige maskinlæringsmodeller, der bruges til praktiske formål, og hvordan man opbygger en simpel maskinlæringsmodel i python. Valg af en passende model til en bestemt brugssag er meget vigtig for at opnå det rette resultat af en maskinlæringsopgave. For at sammenligne ydelsen mellem forskellige modeller defineres evalueringsmetriker eller KPI'er for særlige forretningsproblemer, og den bedste model vælges til produktion efter anvendelse af den statistiske ydelseskontrol.
Anbefalede artikler
Dette er en guide til Machine Learning Models. Her diskuterer vi de 5 toptyper af maskinlæringsmodeller med dens definition. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Metoder til maskinindlæring
- Typer af maskinlæring
- Maskinlæringsalgoritmer
- Hvad er maskinlæring?
- Hyperparameter-maskinlæring
- KPI i Power BI
- Hierarkisk klynge-algoritme
- Hierarkisk klynge | Agglomerativ og opdelende klynge