
Introduktion til tekstminedrift
Tekstminering - I nutidens kontekst er tekst det mest almindelige middel, hvorpå information udveksles. Men at forstå betydningen fra teksten er slet ikke et let job. Vi har brug for et godt forretningsoplysningsværktøj, der hjælper med at forstå informationen på en nem måde.
Hvad er tekstminedrift
Text Mining er også kendt som Text Analytics. Det er processen med at forstå information fra et sæt tekster. Text Mining er designet til at hjælpe virksomheden med at finde ud af værdifuld viden fra tekstbaseret indhold. Dette indhold kan være i form af orddokument, e-mail eller posteringer på sociale medier.
Text Mining er brugen af automatiserede metoder til forståelse af den viden, der er tilgængelig i tekstdokumenterne.
Text Mining kan også bruges til at få computeren til at forstå strukturerede eller ustrukturerede data. Kvalitative data eller ustrukturerede data er data, der ikke kan måles i antal. Disse data indeholder normalt information som farve, tekstur og tekst. Kvantitative data eller strukturerede data er data, der let kan måles.
Tekstminedrift er et tværfagligt felt, der inkluderer indhentning af oplysninger, data mining, maskinindlæring, statistik og andre. Text Mining er et lidt andet felt end data mining.
Fordele ved tekstudvinding
Der er mange fordele ved at bruge Text Mining. De er anført nedenfor
- Det sparer tid og ressourcer og fungerer effektivt end menneskelige hjerner.
- Det hjælper med at spore meninger over tid
- Text Mining hjælper med at opsummere dokumenterne
- Tekstanalyse hjælper med at udtrække koncepter fra tekst og præsentere det på en mere enkel måde
- Teksten, der indekseres ved hjælp af Tekstmining, kan bruges i forudsigelig analyse
- Du kan tilslutte ethvert ordforråd for at bruge terminologien i dit interesseområde
Anvendelser af tekstindustrien
- Navnene på forskellige enheder og forhold mellem teksten kan let findes ved hjælp af forskellige teknikker.
- Det hjælper med at udtrække mønstre fra en stor mængde ustrukturerede data
- Systematisk gennemgang af litteratur - Det kan gå til dybdegående undersøgelse af tekst, finde ud af nøgletemaer og fremhæve de gentagne udtryk eller tekst og de populære emner over en periode.
- Test af hypotese - Gennem tekst mining kan en bestemt hypotese testes for at se, om dokumentet bekræfter eller afviser hypotesen. Oftest testes en etableret tro over dokumentet først.
Udvikle løsninger til forretningsproblemer effektivt. Lær at definere, analysere og dokumentere forretningskrav. Undersøg forretningsaktiviteter for at gøre dem mere effektive.
Betydningen af tekstudvinding
- Text Mining muliggør bedre og smart beslutningstagning
- Det hjælper med at løse videnopdagelsesproblemer inden for forskellige forretningsområder
- Gennem tekst mining kan du nemt visualisere dataene på mange måder som html-tabeller, diagrammer, grafer og andre
- Det er et fantastisk produktivitetsværktøj. Det giver bedre resultater hurtigere end noget andet værktøj.
- Tekstmining værktøj bruges af både store og små organisationer, der er videnstyrede organisationer.
Anvendelser af Text Mining
-
Analyse af åbne undersøgelsessvar
Spørgsmål med åbne undersøgelser hjælper respondenterne med at give deres syn eller mening uden nogen begrænsninger. Dette vil hjælpe med at vide mere om kundernes meninger end at stole på strukturerede spørgeskemaer. Tekstminering kan bruges til at analysere sådanne oplysninger i form af tekst.
-
Automatisk behandling af meddelelser, e-mails
Text Mining bruges også hovedsageligt til at klassificere teksten. Text Mining kan bruges til at filtrere den unødvendige mail ved hjælp af visse ord eller sætninger. Sådanne mails kasseres automatisk sådanne mails til spam. Sådan automatisk system til klassificering og filtrering af valgte mails og afsendelse af den tilsvarende afdeling udføres ved hjælp af Text Mining-system. Text Mining vil også sende en advarsel til e-mailbrugeren om at fjerne mails med sådanne fornærmende ord eller indhold.
-
Analyse af garanti- eller forsikringskrav
I de fleste forretningsorganisationer indsamles information hovedsageligt i form af tekst. For eksempel på et hospital kan patientintervjuerne fortælles kort i tekstform, og rapporterne er også i form af tekst. Disse noter er nu indsamlet en dags elektronisk, så de let kan overføres til algoritmer til tekstminering. Disse poster kan derefter bruges til at diagnosticere den faktiske situation.
-
Undersøgelse af konkurrenter ved at gennemgå deres websteder
Et andet vigtigt anvendelsesområde for Text Mining er at behandle indholdet af websider i et bestemt domæne. På denne måde finder tekstindvindingssystemet automatisk en liste over udtryk, der bruges på webstedet. På denne måde kan man finde ud af de vigtigste udtryk, der bruges på hjemmesiden. På denne måde kan man kende kapaciteterne om konkurrenterne, som kan hjælpe dig med at levere forretninger effektivt.
De andre applikationer af Text Mining inkluderer følgende
- Business Intelligence
- E Opdagelse
- Bioinformatik
- Records Management
- National sikkerhed eller intelligens fungerer
- Social medieovervågning
Teknikker, der bruges i Text Mining
Der er fem grundlæggende teknologier, der bruges i Text Mining-systemet. De diskuteres detaljeret nedenfor
-
Informationsudvinding
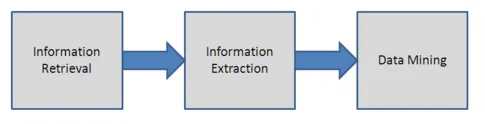
Dette bruges til at analysere den ustrukturerede tekst ved at finde ud af de vigtige ord og finde forholdene mellem dem. I denne teknik bruges processen med mønstermatchning til at finde ud af rækkefølgen i teksten. Det hjælper med at omdanne den ustrukturerede tekst til struktureret form. Informationsekstraktionsteknikken involverer sprogbehandlingsmoduler. Dette bruges mest, når der er store mængder data. Processen med informationsudvinding forklares på billedet herunder.
-
Kategorisering
Kategoriseringsteknik klassificerer tekstdokumentet under en eller flere kategorier. Det er baseret på input output eksempler for at gøre klassificeringen. Kategoriseringsprocessen inkluderer forbehandling, indeksering, dimensionel reduktion og klassificering. Teksten kan kategoriseres ved hjælp af teknikker som Naive Bayesian klassifikator, Beslutningstræ, Nærmeste nabo-klassifikator og Support Vendor Machines.
-
clustering
Clustering-metode bruges til at gruppere tekstdokumenter, der har lignende indhold. Det har partitioner, der kaldes klynger, og hver partition vil have et antal dokumenter med lignende indhold. Clustering sørger for, at intet dokument udelades fra søgningen, og at det henter alle de dokumenter, der har lignende indhold. K-middel er den hyppigt anvendte klyngeteknik. Denne teknik sammenligner også hver klynge og finder, hvor godt dokumentet er forbundet til hinanden. Virksomheder bruger denne teknik til at oprette en database med tusind lignende dokumenter.
-
Visualisering
Visualiseringsteknik bruges til at forenkle processen med at finde relevant information. Denne teknik bruger tekstflag til at repræsentere dokumenter eller gruppe af dokumenter og bruger farver til at indikere kompaktheden. Visualiseringsteknik hjælper med at vise tekstinformation på en mere attraktiv måde. Nedenstående billede repræsenterer Visualiseringsteknikken
-
Summarization
Opsummeringsteknik vil hjælpe med at reducere dokumentets længde og opsummere detaljerne i dokumenterne kort. Det får dokumentet til at arbejde for læsning for brugerne og forstå indholdet med et øjeblik. Resumé erstatter hele sæt dokumenter. Det opsummerer stort tekstdokument let og hurtigt. Mennesker tager mere tid på at læse og derefter sammenfatte dokumentet, men denne teknik gør det meget hurtigt. Det hjælper med at fremhæve vigtige punkter i et dokument. Opsummeringsprocessen er repræsenteret på billedet herunder.
Metoder og modeller, der bruges i tekstminedrift
Baseret på indhentning af information Text Mining har fire hovedmetoder
-
Termbaseret metode (TBM)
Term i et dokument betyder et ord, der har semantisk betydning. I denne metode analyseres hele sæt dokumenter med udgangspunkt i termen. En hovedulempe ved denne metode er problemet med synonym og polysemi. Synonym er det sted, hvor flere ord har samme betydning. Polysemi er hvor et enkelt ord har flere betydninger.
-
Sætningsbaseret metode (PBM)
I denne metode analyseres dokumentet på baggrund af de sætninger, der er mindre indlysende for flere betydninger og mere diskriminerende. Ulemperne ved denne metode inkluderer
- De har dårligere statistiske egenskaber i forhold til termer
- De har lav forekomst
- De har et stort antal støjende sætninger
-
Konceptbaseret metode (CBM)
I denne metode analyseres dokumentet på baggrund af sætning og dokumentniveau. I denne metode er der tre hovedkomponenter. Den første komponent undersøger den meningsfulde del af sætningerne. Den anden komponent producerer en konceptuel ontologisk graf til at forklare strukturer. Den tredje komponent uddrager topkoncepter baseret på de to første komponenter. Denne metode kan skelne mellem de vigtige og uvigtige ord.
-
Mønster taxonomimetode (PTM)
I denne metode analyseres dokumentet på baggrund af mønstre. Mønstre i et dokument kan findes ved hjælp af dataminingsteknikker som mining-associeringsregel, sekvensmønstermining, hyppig minedrift af genstande og afsluttet mønsterminedrift. Denne metode bruger to processer - mønsterudvikling og mønsterudvikling. Denne metode er vist sig at fungere bedre end alle de andre modeller eller metoder.
Hvordan fungerer Text Mining
Nu skulle du have forstået, at tekstudvinding gør det muligt at forstå teksten bedre end noget andet. Text Mining-system foretager en ordveksling fra ustrukturerede data til numeriske værdier. Tekst mining er med til at identificere mønstre og forhold, der findes inden for en stor mængde tekst. Tekstmining bruger ofte beregningsalgoritmer til at læse og analysere tekstinformation. Uden tekstudvinding er det vanskeligt at forstå teksten let og hurtigt. Tekst kan udvindes på en mere systematisk og omfattende måde, og informationen om virksomheden kan indfanges automatisk. Trinene i tekstindvindingsprocessen er vist nedenfor.
-
Trin 1: Indhentning af oplysninger
Dette er det første trin i processen med data mining. Dette trin involverer hjælp af en søgemaskine til at finde ud af samlingen af tekst, også kendt som korpus af tekster, som muligvis har brug for en vis konvertering. Disse tekster skal også samles i et bestemt format, som vil være nyttigt for brugerne at forstå. Normalt er XML standarden for tekstminedrift
-
Trin 2: Natural Language Processing
Dette trin giver systemet mulighed for at udføre grammatisk analyse af en sætning for at læse teksten. Den analyserer også teksten i strukturer.
-
Trin 3: Ekstraktion af oplysninger
Dette er det andet trin, hvor man gør det muligt at identificere betydningen af en bestemt tekstmarkering. I dette trin føjes en metadata til databasen om teksten. Det involverer også tilføjelse af navne eller placeringer til teksten. Dette trin gør det muligt for søgemaskinen at få oplysningerne og finde ud af forholdet mellem teksterne ved hjælp af deres metadata.
-
Trin 4: Datamining
Den sidste fase er data mining ved hjælp af forskellige værktøjer. Dette trin finder lighederne mellem de oplysninger, der har den samme betydning, som ellers vil være vanskelige at finde. Text Mining er et værktøj, der øger forskningsprocessen og hjælper med at teste forespørgsler.
Text Mining inkluderer følgende liste over elementer
- Tekstkategorisering
- Tekstklynge
- Koncept / enhedsekstraktion
- Granulær taksonomi
- Følelsesanalyse
- Dokument opsummering
- Modellering af enhedsrelationer
Udfordringer ved tekstminedrift
Den største udfordring, som Text Mining-systemet står overfor, er det naturlige sprog. Det naturlige sprog står overfor problemet med tvetydighed. Uklarhed betyder et udtryk med flere betydninger, hvor en sætning fortolkes på forskellige måder, og som et resultat opnås forskellige betydninger.
En anden begrænsning er, at det bruger semantisk analyse, når man bruger informationsekstraktionssystem. På grund af dette præsenteres ikke den fulde tekst, kun en begrænset del af teksten præsenteres for brugerne. Men i disse dage er der behov for mere tekstforståelse.
Text Mining har også begrænsninger i lovgivningen om ophavsret. Der er mange begrænsninger i tekstudvinding af et dokument. De fleste af de gange inkluderer det rettighederne for indehaverne af ophavsretten. De fleste af teksterne findes ikke som open source, og i sådanne tilfælde kræves tilladelse fra de respektive forfattere, udgivere og andre beslægtede parter.
En yderligere begrænsning er, at tekstminedrift ikke genererer nye fakta, og det er ikke en afslutningsproces.
Konklusion
Tekstmining eller tekstanalyse er en blomstrende teknologi, men stadig varierer resultaterne og dybden af analysen fra forretning til virksomhed. En organisation kan bruge tekstudvinding til at få viden om indholdsspecifikke værdier.