

Introduktion til Data mining
Dette er en data mining-metode, der bruges til at placere dataelementer i deres lignende grupper. Klynge er proceduren for opdeling af dataobjekter i underklasser. Clustering-kvalitet afhænger af den metode, vi brugte. Clustering kaldes også datasegmentering, da store datagrupper er divideret med deres lighed.
Hvad er klynger inden for data mining?
Clustering er gruppering af specifikke objekter baseret på deres egenskaber og ligheder. Hvad angår data mining, opdeler denne metode de data, der er bedst egnet til den ønskede analyse ved hjælp af en særlig sammenkoblingsalgoritme. Denne analyse tillader et objekt ikke at være en del eller strengt en del af en klynge, der kaldes den hårde partitionering af denne type. Glatte partitioner antyder imidlertid, at hvert objekt i samme grad hører til en klynge. Mere specifikke opdelinger kan oprettes som objekter af flere klynger, en enkelt klynge kan tvinges til at deltage, eller endda kan hierarkiske træer konstrueres i gruppeforhold. Dette filsystem kan bringes på plads på forskellige måder baseret på forskellige modeller. Disse distinkte algoritmer gælder for hver model og skelner mellem deres egenskaber og deres resultater. En god klynge-algoritme er i stand til at identificere klyngen uafhængig af klyngeformen. Der er 3 grundlæggende faser i klynge-algoritmen, som er vist som nedenfor
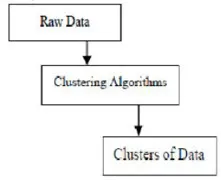
Clustering-algoritmer i datamining
Afhængig af de for nylig beskrevne klyngemodeller kan mange klynger bruges til at opdele oplysninger i et datasæt. Det skal siges, at hver metode har sine egne fordele og ulemper. Valg af en algoritme afhænger af egenskaberne og arten af datasættet.
Klyngemetoder til datamining kan vises som nedenfor
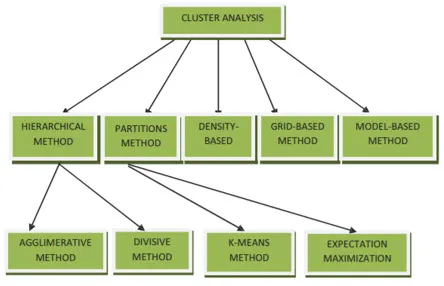
- Partitionsbaseret metode
- Tæthedsbaseret metode
- Centroid-baseret metode
- Hierarkisk metode
- Netbaseret metode
- Modelbaseret metode
1. Partitionsbaseret metode
Partitionsalgoritmen deler data i mange undergrupper.
Lad os antage, at partitionsalgoritmen bygger en partition af data, da k og n er objekter, der er til stede i databasen. Derfor bliver hver partition repræsenteret som k ≤ n.
Dette giver en idé om, at klassificeringen af dataene er i k-grupper, som kan vises nedenfor
Figur 1 viser originale punkter i klynger

Figur 2 viser partitionsklynger efter anvendelse af en algoritme
Dette indikerer, at hver gruppe har mindst et objekt såvel som hvert objekt skal tilhøre nøjagtigt en gruppe.
2. Tæthedsbaseret metode
Disse algoritmer producerer klynger på et bestemt sted baseret på den høje tæthed af datasætdeltagere. Det aggregerer et vist rækkevidde for gruppemedlemmer i klynger til et standardtæthedsniveau. Sådanne processer kan udføre mindre ved at detektere gruppens overfladearealer.
3. Centroid-baseret metode
Næsten hver klynge refereres til af en vektor af værdier i denne type os-grupperingsteknik. I sammenligning med andre klynger er hvert objekt en del af klyngen med en mindste forskel i værdi. Antallet af klynger skal foruddefineres, og dette er det største algoritmeproblem af denne type. Denne metodik er tættest på identifikationsemnet og bruges i vid udstrækning til optimeringsproblemer.
4. Hierarkisk metode
Metoden skaber en hierarkisk nedbrydning af et givet sæt dataobjekter. Baseret på hvordan den hierarkiske nedbrydning dannes, kan vi klassificere hierarkiske metoder. Denne metode er givet som følger
- Agglomerativ tilgang
- Delende tilgang
Agglomerativ tilgang er også kendt som Button-up Approach. Her begynder vi med hvert objekt, der udgør en separat gruppe. Det fortsætter med at smelte sammen objekter eller grupper
Opdelende fremgangsmåde er også kendt som top-down-metoden. Vi begynder med alle objekter i den samme klynge. Denne metode er stiv, dvs. den kan aldrig fortrydes, når en fusion eller opdeling er afsluttet
5. Netbaseret metode
Gitterbaserede metoder fungerer i objektområdet i stedet for at dele dataene i et gitter. Ristet er delt på baggrund af dataene. Ved at bruge denne metode er ikke-numeriske data let at administrere. Datarækkefølge påvirker ikke opdelingen af gitteret. En vigtig fordel ved en netbaseret model giver den hurtigere eksekveringshastighed.
Fordele ved hierarkisk klynge er som følger
- Det gælder for enhver attributtype.
- Det giver fleksibilitet relateret til granularitetsniveauet.
6. Modelbaseret metode
Denne metode bruger en hypotetiseret model baseret på sandsynlighedsfordeling. Ved at gruppere densitetsfunktionen lokaliserer denne metode klyngerne. Det afspejler datapunkternes rumlige fordeling.
Anvendelse af klynger i Data Mining
Clustering kan hjælpe på mange områder såsom biologi, planter og dyr klassificeret efter deres egenskaber såvel som i markedsføring. Clustering vil hjælpe med at identificere kunder i en bestemt kunderekord med lignende opførsel. I mange applikationer, såsom markedsundersøgelser, mønstergenkendelse, data og billedbehandling, bruges klynge-analysen i stort antal. Clustering kan også hjælpe annoncører i deres kundegrundlag med at finde forskellige grupper. Og deres kundegrupper kan defineres ved købsmønstre. I biologi bruges det til bestemmelse af taksonomier for planter og dyr, til kategorisering af gener med lignende funktionalitet og til indsigt i befolkningens iboende strukturer. I en jordobservationsdatabase gør klynger det også lettere at finde områder med lignende brug i jorden. Det hjælper med at identificere grupper af huse og lejligheder efter type, værdi og destination for huse. Klynge af dokumenter på nettet er også nyttigt til at finde oplysninger. Klyngeanalysen er et værktøj til at få indsigt i distributionen af data for at observere egenskaberne for hver klynge som en data mining funktion.
Konklusion
Clustering er vigtig i data mining og dens analyse. I denne artikel har vi set, hvordan klynger kan udføres ved at anvende forskellige klynge-algoritmer såvel som dens anvendelse i det virkelige liv.
Anbefalet artikel
Dette har været en guide til Hvad er klynge i datamining. Her diskuterede vi koncepter, definition, funktioner, anvendelse af Clustering i Data Mining. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Hvad er databehandling?
- Hvordan bliver man en dataanalytiker?
- Hvad er SQL-injektion?
- Definition af hvad er SQL Server?
- Oversigt over Data Mining Architecture
- Klynge i maskinlæring
- Hierarkisk klynge-algoritme
- Hierarkisk klynge | Agglomerativ og opdelende klynge